今天看着有个很吸引人的小说作品信息:一家只在深夜开门营业的书屋,欢迎您的光临。
作为东野奎吾《深夜食堂》漫画的fans,看到这个标题按捺不住我的好奇心........
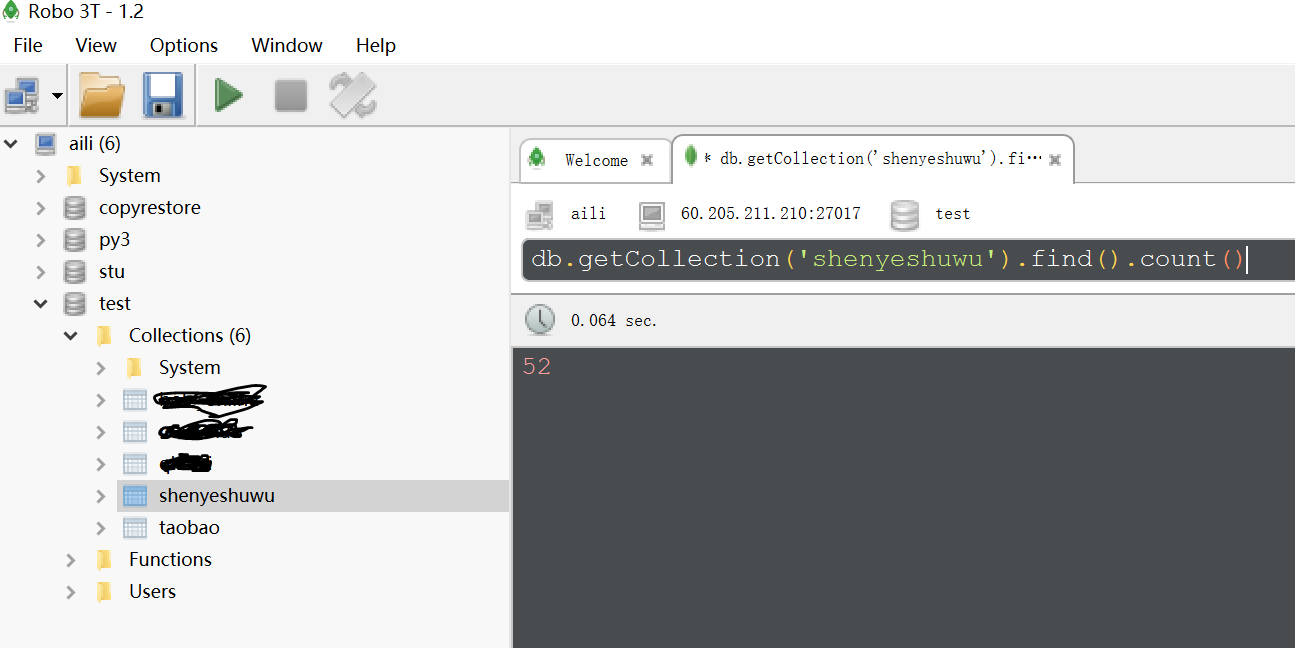
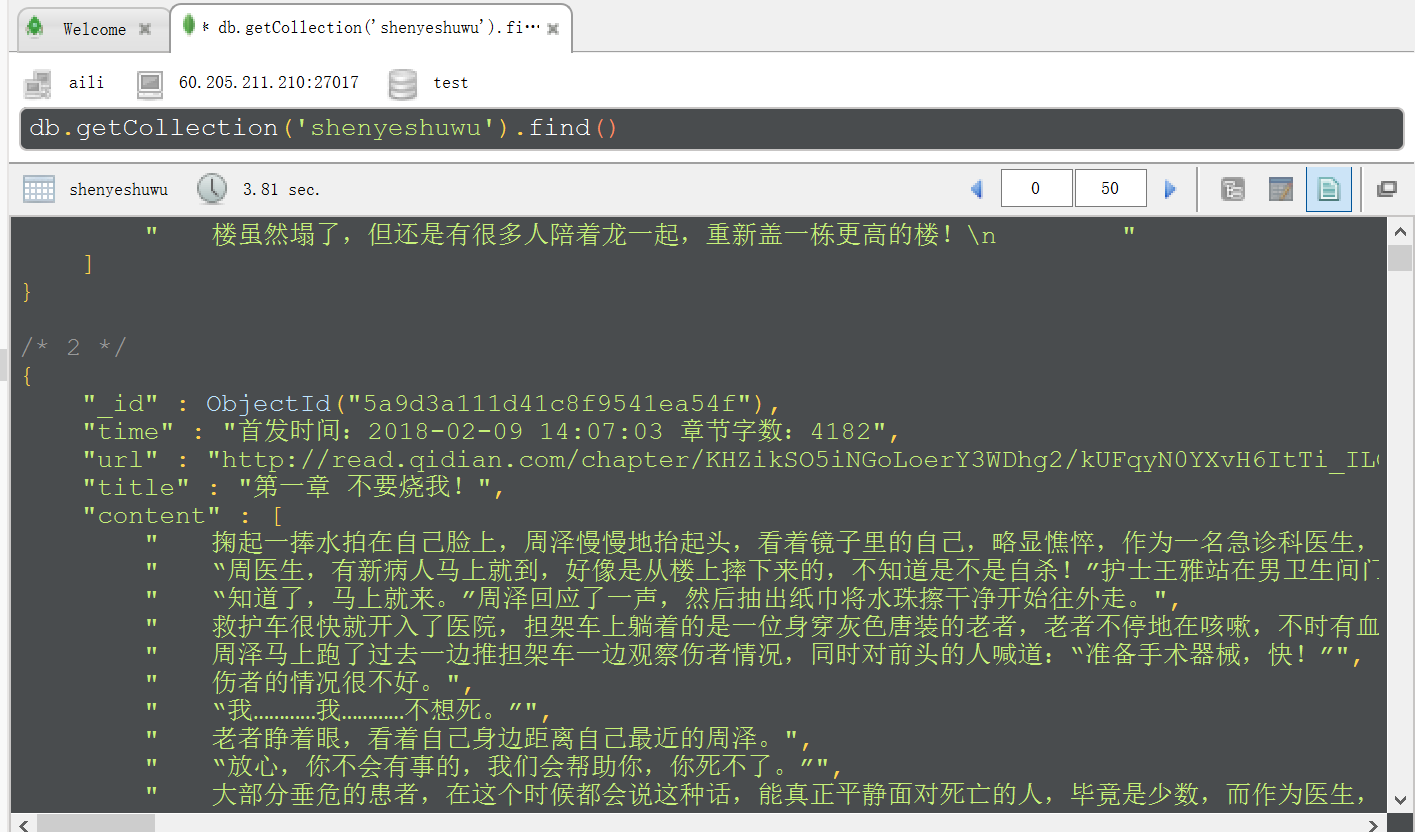
所以我又抓下来了,总共52章,下面有源码,写的有点乱哦,凑合看看,关键看结果,@~@。。。。
代码写完,几秒钟就抓取下来,比下载效率高不少,小激动~~~~~~
readme>>>环境python2,我的python2还有多长寿命;其他內库依赖见代码体现
# coding:utf-8
from multiprocessing import Pool
from lxml import etree
import requests
import pymongo
def save_mongo(data):
client = pymongo.MongoClient('60.205.211.210',27017)
db = client.test
collection = db.shenyeshuwu
collection.insert(dict(data))
print('--------%s---------存储完毕' %data['title'])
def parse_content(url):
resp = requests.get(url).content
html = etree.HTML(resp)
contents = html.xpath('//*[@id="j_chapterBox"]/div[2]/div/div[2]/p/text()|//*[@id="j_chapterBox"]/div[1]/div/div[2]/p/text()')
return contents
def parse_html(html):
'''
[{
'title':title,
'url':url,
'content':content
}]
'''
page = etree.HTML(html)
article_url_list = page.xpath('//ul[@class="cf"]/li/a')
for i in article_url_list:
url = 'http:' + i.xpath('./@href')[0]
# print(url)
title = i.xpath('./text()')[0]
# print(title)
time = i.xpath('./@title')[0]
# print(time)
con = parse_content(url)
# print(con)
data = {
'url': url,
'title': title,
'time': time,
'content': con
}
print(data)
save_mongo(data)
def get_page(url):
header = {
'User-Agent':'Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/64.0.3282.186 Safari/537.36'
}
resp = requests.get(url,headers=header).content
parse_html(resp)
def main():
url = 'https://book.qidian.com/info/1011335417#Catalog'
# get_page(url)
# 使用进程池 map(func,iterable)
pool = Pool(4)
# pool.map(parse_content,data)
pool.apply_async(get_page,args=(url,))
pool.close()
pool.join()
if __name__ == '__main__':
main()
如往常,把截图展示下: