最近在工作之余学习NLP相关的知识,对word2vec的原理进行了研究。在本篇文章中,尝试使用TensorFlow自行构建、训练出一个word2vec模型,以强化学习效果,加深理解。
一.背景知识:
在深度学习实践中,传统的词汇表达方式是使用one-hot向量,其中,向量的维度等于词汇量的大小。这会导致在语料较为丰富,词汇量较大的时候,向量的维度过长,进而产生一个相当大的稀疏矩阵,占用不少内存开销,降低机器运行速度。而word2vec则为这个问题提供了一种解决方案。
word2vec是一个用来产生词向量的相关模型,使用固定长度(长度较短)的词向量来代替one-hot向量,从而降低深度学习网络中的运算复杂度。其基本思想是使用skip-gram网络/cbow网络来对语料进行训练,留下其中间过程所生成的权重矩阵作为词向量表。这个词向量表是一个[词汇量大小*词向量维度]的矩阵,在使用时,可以使用one-hot向量和词向量表做矩阵乘法,提取出对应词汇的词向量以供后续使用。
除了降低词向量的维度之外,word2vec可以使两个含义相近的词语用于更为接近的词向量(即两个词向量之间的欧式距离更接近)。因此在搭建语言模型时拥有更强大的逻辑相关性。
现在已经有一个较为方便的word2vec模块(由Google开发)供大家使用,可以通过 pip install word2vec 指令来对其进行安装使用。为加深理解,强化学习效果,这里我们不使用该模块,尝试自己搭建预训练网络来生成word2vec词向量表。
二.建模思路:
这次的建模、训练流程如下图所示,大致分为语料预处理,网络搭建,训练存储三个阶段。
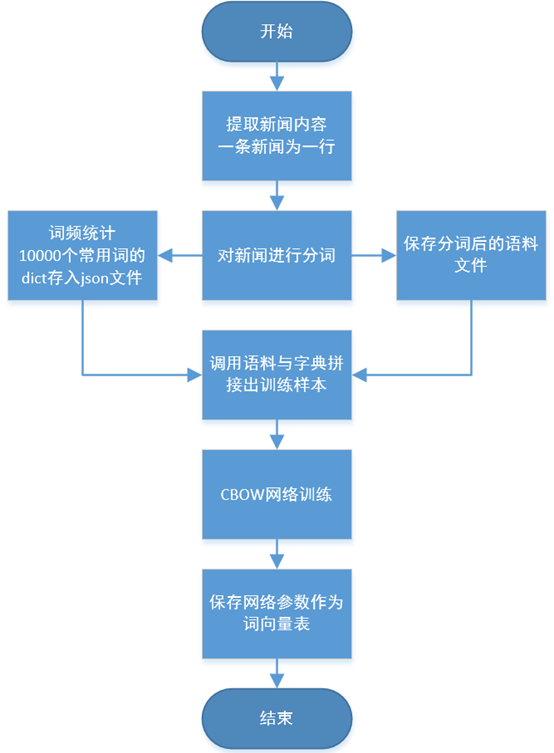
由于这次是对中文语料进行处理,因此预处理过程中较为复杂,相比处理英文语料多一个分词的步骤。此外,也没有查找到资料详细的解释word2vec是否需要对所有词汇进行训练,因此这里在预处理步骤中加入了词频统计,仅提取出10000个出现频率最高的词语作为常用词汇进行建模训练。
三.语料预处理:
这里我们使用的是搜狐新闻语料库(1.5GB)来作为我们的数据源。下载地址为:http://www.sogou.com/labs/resource/cs.php
首先我们要进行语料的预处理工作。搜狐新闻语料库是一个结构化的语料数据文件,其中,新闻标题位于标签<content-title></content-title>中,新闻内容位于标签<content></content>中。第一步就是要将新闻内容从标签中提取出来。
3.1 乱码问题
在提取新闻内容时,遇到了一个比较棘手的编码问题。在这个数据文件中,大部分的新闻内容是使用GBK方式进行编码的,而其中又夹杂着某些字符使用了其他编码格式,包括Unicode,ISO-8859-1等等。为解决这个问题,这里引入datadec模块来判断字符的编码格式。最初的想法是使用datadec来判断每一个字符,使用判断出的格式来对其进行解码。但实际问题是各种编码格式所占字节数长度并不一致,如GBK是双字节编码,而UTF-8则是可变长字符编码,从1-6字节不等,如果每次读取一个固定长度来datadec其编码类型,往往会判断出错。因此,在语料预处理中,读取文件的每一行,使用datadec.detect()函数来判断该行文件的编码格式,之后用对应的格式进行解码。其中遇到串码问题无法正确解析的,在decode()函数中使用errors=’ignore’参数来对该问题进行忽略,保证程序的正常运行。但最终生成的文件还是会有部分乱码,后期会使用词频统计的方式尽量将其过滤。
解决乱码问题的关键代码如下(注意读文件时要使用二进制方式读取,即’rb’):
1 pure_file = open(path[:-4]+"_pure.txt",'w',encoding='utf-8') 2 with codecs.open(path,'rb') as f_corp: 3 # TODO 去除杂质编码 4 count = 0 # 记录总共处理了多少行新闻文件 5 count1 = 0 # 记录通过非GBK编码处理了多少行新闻文件 6 lines = f_corp.readlines() 7 for word in lines: 8 try: 9 count += 1 10 # 此处不设置 errors='ignore' 参数,尝试使用GBK解码,遇到解析问题时跳入except处理流程。 11 word_out = word.decode('gbk') 12 pure_file.write(word_out) 13 except: 14 count1 += 1 15 code_name = chardet.detect(word) 16 if code_name['confidence']>0.90: 17 word_out = word.decode(code_name['encoding'],errors='ignore') 18 pure_file.write(word_out) 19 else: 20 continue 21 pure_file.close()
在解决完乱码问题之后,我们通过匹配<content>标签来提取所需要的新闻内容,使用逻辑判断的方式。
1 content_file = open(path[:-4]+"_content.txt",'w',encoding='utf-8') 2 with open(path,'r',encoding='utf-8') as f_corp: 3 content_lines = f_corp.readlines() 4 for item in content_lines: 5 if item[:9]=='<content>' and len(item)>20: # 需判断长度,防止有<content></content> 的情形出现 6 content_file.write(item[9:-11]+' ') 7 content_file.close()
最终获得纯净的新闻内容供后续使用,类似下图所示(可以看出仍有部分乱码,后期会通过词频统计进行处理)。

3.2 分词与词频统计
拿到纯净的新闻内容后,就可以进行分词与词频统计工作。这里使用jieba分词器来完成我们的分词工作。jieba分词器是一个轻量级的中文分词模块,可以使用pip install jieba指令来进行安装。注意,由于jieba是第三方python模块,因此不能够使用conda来进行安装。
考虑到后面制作训练样本时,各类词语容易与标点形成训练样本,影响训练效果。在分词之前,首先借助unicodedata模块中的category函数来去除新闻中的标点符号。
1 for ss in c_lines: 2 sentences = ''.join(ch for ch in ss if category(ch)[0]!='P')
对每一行新闻通过上述语句进行扫描,排除掉其中的标点符号。
之后使用jieba分词器来对语句进行切分,并存入语料文件。
1 words = jieba.cut(sentences,cut_all=False) 2 words = ' '.join(words) # 使用 空格 将每一个词汇隔开 此时是str类型变量。 3 array_c.append(words[:-1]) # 去除句末的 ' '
切分后语料如下:

可以看出,在文本中仍然存在有些许乱码,这多少为后续的准确训练埋下隐患,但由各种乱码常常是孤立字符,可以通过统计常用词的方式将其进行排除。
为完成词频统计工作,我们建立两个list,array_di(记录已统计的词汇)以及array_dn(记录array_di中各对应位置词汇的出现次数)。代码逻辑大致如下:挨个扫描新闻中词汇,若该词语已在存在于array_di中,则array_dn的对应位置+1;若该词汇从未出现过,则将其添加在array_di的末尾,同时array_dn的末尾添加一个1,表示这个词汇出现了一次。
在分词与词频统计的过程中,会出现程序运行缓慢,CPU使用率较低的情况,可以使用多进程的方法分派工作,待所有子进程完工之后,再进行拼接。具体方法在我的上一篇学习笔记中有描述。(学习笔记-使用多进程、多线程加速文本内容预处理)
截取常用词的工作可以使用numpy模块的argsort()函数来对array_dn进行逆序排序,截取数值最大的10000个值所在的索引,提取出对应索引在array_di中的词汇做成字典,保存在json文件内。
1 dict_list_index_last = np.array(array_dn) 2 word_frequent_list = np.argsort(-dict_list_index_last) # 降序排序,并获取其排序的索引顺序 3 d_out = dict() # TODO 最终常用词词典列表 4 count = 0 5 for index in word_frequent_list[:10000]: # 提取10000个常用词汇 6 d_out[array_di[index]] = count 7 count += 1 8 with open(pured_file[:-4]+'_dict.json','w',encoding='utf-8') as f_dict: 9 json.dump(d_out, f_dict)
最终生成的.json文件如下:
其中,key为词汇的utf-8编码,value值为其对应的位置,取值从0~9999。为后续构建初始one-hot vector作好了准备。
四.网络搭建:
4.1 模型结构设计
数据预处理工作完成以后,可以开展网络结构的设计。有两种网络模型可以用来进行word2vec的训练,分别是CBOW(Continuous Bag-of-Words Model)和skip-Gram(Continuous Skip-gram Model)。这两个网络的区别主要在于训练样本的构造。
CBOW构造一个训练样本时,样本的输入为当前词汇的前n个词和后n个词,其中n表示窗口长度。例如对于句子[寒冷的 冬天 我 爱 在 学校 里 跑步],当窗口长度为2的时候,这个句子可以分解为4个训练样本,即[[寒冷的,冬天,爱,在],[我]],[[冬天,我,在,学校],[爱]],[[我,爱,学校,里],[在]],[[爱,在,里,跑步],[学校]]。其中每一个样本的前半部分为输入,后半部分为其对应的输出。
而使用skip-Gram来构造训练样本时,同样取向前n个词和向后n个词作为窗口。但输入与输出的维度是相等的,即训练样本以词对的形式来展现。同样对于[寒冷的 冬天 我 爱 在 学校 里 跑步]这个句子,窗口长度n=2。
输出词汇为[寒冷的]时,有[[寒冷的],[冬天]],[[寒冷的],[我]]两个样本,
输入词汇为[冬天]时,有[[冬天],[寒冷的]],[[冬天],[我]],[[冬天],[爱]]三个样本,
输入词汇为[我]时,有[[我], [寒冷的]],[[我], [冬天]],[[我],[爱]],[[我],[在]]这四个样本。
以此类推,这句话一共可以生成2+3+4+4+4+4+3+2=26个样本。相对于CBOW网络来说训练内容要丰富一些。
考虑到训练量过大会比较考验机器性能,这里选择使用CBOW网络来完成word2vec的训练。
现在开始考虑网络的维度结构,因为选择的是CBOW网络,所以说初始的输入是2*n个词汇(n表示窗口长度),即2*n个one-hot vector,叠加成的矩阵,由于预处理中截取的词汇量为10000,所以输入矩阵的维度为[2n*10000];同样的,由于输出仅仅只有一个词汇,所以样本的输出是一个维度为[1*10000]的one-hot vector。这里假设目标词向量的维度为300,因此词向量表的维度为[10000*300]。输入矩阵和词向量表经过矩阵乘法相乘,可以得到一个维度为[2n*300]的矩阵,即2n个词汇经过降维所得到的较短的词向量。为了使其可以正确的和样本输出计算进行对应,需将其正确的映射到[1*10000]的维度。这里使用[1*2n]×[2n*300]×[300*10000]的方法,将其转换为[1*10000]的向量,经过softmax激活函数计算,可以同样本输出计算出loss值,并根据loss使用随机梯度下降法来对网络进行训练。
网络的模型维度设计示意图如下:
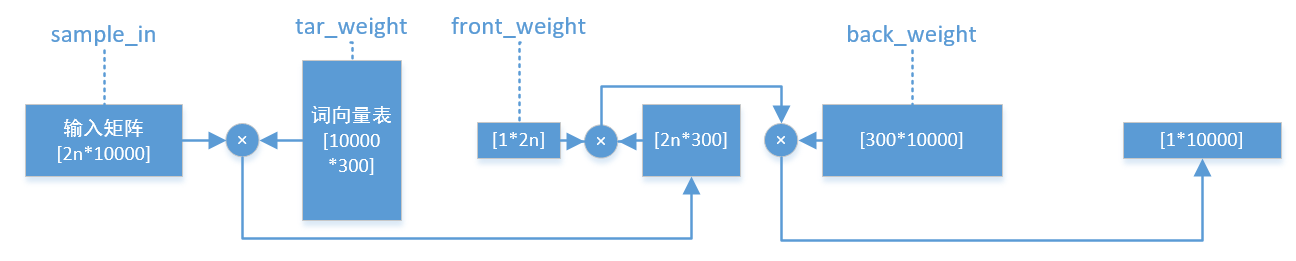
如图所示,搭建此次网络模型需要初始化tar_weight,front_weight,back_weight三个权重矩阵。
根据上面设计的网络维度结果,开始构建CBOW网络类:
1 import numpy as np 2 import tensorflow as tf 3 4 class CBOW_Cell(object): 5 def __init__(self, window_length=5, word_dim=300): 6 with tf.variable_scope("matrix_scope") as matrix_scope: 7 self.tar_weight = tf.get_variable(name='tar_weight',shape=[10000,word_dim], 8 initializer=tf.truncated_normal_initializer(stddev=0.1),dtype=tf.float32) 9 self.front_weight = tf.get_variable(name='front_weight',shape=[1,2*window_length], 10 initializer=tf.truncated_normal_initializer(stddev=0.1),dtype=tf.float32) 11 self.back_weight = tf.get_variable(name='back_weight',shape=[word_dim,10000], 12 initializer=tf.truncated_normal_initializer(stddev=0.1),dtype=tf.float32) 13 matrix_scope.reuse_variables() 14 # 上方为tar_weight,front_weight,back_weight 三个权重矩阵的维度设置及初始化。 15 # 下方为偏移量权重的设置 及 变量保存。 16 self.bias = tf.Variable(tf.zeros([1,10000])) # 偏移量,用于加到softmax前的输出上 17 self.word_dim = word_dim # 词向量维度 18 self.window_length = window_length 19 # 下方为占位符,规定好输入、输出的shape 20 self.sample_in = tf.placeholder(tf.float32, [2*window_length, 10000],name='sample_in') 21 self.sample_out = tf.placeholder(tf.float32, [1, 10000],name='sample_out')
除了上面提到的3个权重矩阵需要使用tf.get_variable()进行初始化,还额外的需要两个占位符sample_in,sample_out来表示训练样本输入及训练样本输出。
下一步来设计前向传播函数以及损失函数:
1 def forward_prop(self,s_input): 2 step_one = tf.matmul(s_input,self.tar_weight) 3 out_vector = tf.matmul(tf.matmul(self.front_weight,step_one),self.back_weight)+self.bias 4 return out_vector 5 6 def loss_func(self,lr=0.001): 7 out_vector = self.forward_prop(self.sample_in) 8 y_pre = tf.nn.softmax(out_vector,name='y_pre') 9 cross_entropy = tf.nn.softmax_cross_entropy_with_logits_v2(labels=self.sample_out,logits=y_pre) 10 train_op = tf.train.GradientDescentOptimizer(lr).minimize(cross_entropy) 11 return y_pre,cross_entropy,train_op
前向传播函数forward_prop()使用占位符sample_in来计算出维度为[1,10000]的输出向量。而损失函数loss_func()通过softmax来计算出前向预测结果y_pre,并通过交叉熵函数计算出损失值,train_op是定义了随机梯度下降的权重优化计算图。在后续的程序中,我们可以通过train_op来对权重进行优化。
4.2 制作训练样本
在前面分词工作结束之后,我们获得了类似[寒冷的 冬天 我 爱 在 学校 里 跑步]的语料样本。这里要根据这个语料样本,以及窗口大小n,来制作输入维度为[2n*10000],输出维度为[1*10000]的训练样本。
制作训练样本分为如下几步:①对于一条新闻来说,首先就是要确定句子的长度,如果句子包含的词语数≤2*n时,该语句无法拼接成样本,直接将其进行弃置。②对于长度充足的句子,我们取一个长度为2n+1的滑动窗口,前n个词和后n个词做成维度为[1*10000]的one-hot vector,叠加成为[2n*10000]的输入矩阵,中间词汇做成[1*10000]的one-hot vector作为样本输出。将输入和输出组成对进行输出。③为了使样本更多一些,对于一个句子开头和结束的几个词语,在目标词汇前方/后方的词语数目小于窗口长度时,顺着后方/前方窗口额外取数个词语使输入词语数目达到2n,再组成[2n*10000]的输入矩阵,将目标词汇做成one-hot vector向量作为样本输出。(第③步的样本制作方法的目标是增加训练样本数目,但该方法是否科学合理仍有待论证)
为此,编写样本制作函数如下:
1 def make_samples(crop_lines_all,index_to_word,word_to_index,window_len,i): #参数中的i指第几轮语料 2 # 一次处理5行语料防止内存溢出 3 crop_lines = crop_lines_all[i*5:(i+1)*5] 4 sample_in_list = [] # 输入样本list 5 sample_out_list = [] # 输出样本list 6 for line in crop_lines: 7 line_list = line.split(' ') 8 line_list = [word for word in line_list if word in index_to_word] 9 if len(line_list)<window_len*2+1: # 如果语句词汇过少,则抛弃这条语句 10 continue 11 else: 12 # 词语大于双倍窗口的情况下,可以开始拼接样本 13 for i2 in range(len(line_list)): 14 # 句子开头几个词语,前侧的词语数量不够window_len,则后侧多取一些词语攒齐2*window_len的长度 15 if i2<window_len+1: 16 temp_line_list = line_list[:i2]+line_list[i2+1:2*window_len+1] 17 sample_in_list.append(input_matrix_calc(word_to_index,temp_line_list)) 18 temp_out_sample = np.zeros(10000) 19 temp_out_sample[word_to_index[line_list[i2]]] = 1.0 20 sample_out_list.append(temp_out_sample) 21 # 句子末尾几个词语,后侧的词语数量不够window_len,则前侧多取一些词语攒齐2*window_len的长度 22 elif i2>=len(line_list)-window_len: 23 temp_line_list = line_list[len(line_list)-2*window_len-1:i2]+line_list[i2+1:] 24 sample_in_list.append(input_matrix_calc(word_to_index,temp_line_list)) 25 temp_out_sample = np.zeros(10000) 26 temp_out_sample[word_to_index[line_list[i2]]] = 1.0 27 sample_out_list.append(temp_out_sample) 28 # 处于中间阶段,前窗口和后窗口都不越界 29 else: 30 temp_line_list = line_list[i2-window_len:i2]+line_list[i2+1:i2+1+window_len] 31 sample_in_list.append(input_matrix_calc(word_to_index,temp_line_list)) 32 temp_out_sample = np.zeros(10000) 33 temp_out_sample[word_to_index[line_list[i2]]] = 1.0 34 sample_out_list.append(temp_out_sample) 35 return np.array(sample_in_list),np.array(sample_out_list)
参数列中的i是用于分批制作样本的参数,每次处理5行语料,来防止内存溢出,因为一个样本对应了一个巨大的稀疏矩阵,因此每次少处理一些语料比较保险。
五.训练存储:
由于需要TensorFlow的Session中完成训练的步骤,因此训练及存储的工作需要在CBOW网络类中实现。编辑功能函数train_model如下:
1 def train_model(self, savepath,crop_lines_all,index_to_word,word_to_index,epochs=1000,lr=0.001): 2 y_pre,cross_entropy,train_op = self.loss_func(lr) # TODO TODO TODO 这句话千万不能放到循环里面,会重复绘制计算图!!!运行很慢!! 3 with tf.Session() as sess: 4 sess.run(tf.global_variables_initializer()) 5 for data_num in range(int(len(crop_lines_all)/5)): 6 pass # 生成 in_list out_list 7 in_list,out_list = make_samples(crop_lines_all,index_to_word, 8 word_to_index,self.window_length,data_num) #一次20个行的处理语料样本 9 out_list = out_list.reshape(len(in_list),1,10000) 10 if (data_num)%50==0: 11 print('样本已处理',data_num*5,'/',len(crop_lines_all),'行。 ',datetime.datetime.now().strftime('%H:%M:%S.%f')) 12 for i in range(epochs): 13 for j in range(len(in_list)): 14 sess.run(train_op, feed_dict={self.sample_in:in_list[j], 15 self.sample_out:out_list[j]}) 16 #下面为存储模型的代码 17 tar_weight=self.tar_weight.eval() # 这个就是词向量表[10000*词向量维度],是word2vec的最终目标 18 front_weight=self.front_weight.eval() 19 back_weight=self.back_weight.eval() 20 bias=self.bias.eval() 21 word_dim=self.word_dim 22 window_length=self.window_length 23 np.savez(savepath,tar_weight=tar_weight,front_weight=front_weight, 24 back_weight=back_weight,bias=bias,word_dim=word_dim,window_length=window_length) 25 print('model saved in:',savepath)
在该函数中,首先获取损失函数所返回的三个计算图:y_pre,cross_entropy,train_op。之后建立Session,初始化权重矩阵,通过制作训练样本的函数获取训练样本列表,对于每个样本分别使用train_op进行训练,优化权重矩阵。经过了数轮训练,将权重矩阵及CBOW网络类的参数存入.npz文件,这个文件以字典形式保存权重矩阵,其中tar_weight是我们最终目标的词向量表。
六.实践与结果验证:
6.1 词向量表调用:
使用np.load()函数便可以加载.npz文件,并获取词向量表tar_weight。
param_dict = np.load(filepath) tar_weight = param_dict['tar_weight']
我们也可以通过np.linalg.norm()函数来计算两个词向量之间的欧氏距离,通过下面数个词汇来观察词向量距离变化。
dist = np.linalg.norm(w2v[word_to_index['车辆']] - w2v[word_to_index['车子']])
print('"车辆" 与 "车子" 之间的欧式距离为:',dist,'!!')
dist = np.linalg.norm(w2v[word_to_index['机械']] - w2v[word_to_index['工业化']])
print('"机械" 与 "工业化" 之间的欧式距离为:',dist,'!!')
dist = np.linalg.norm(w2v[word_to_index['车辆']] - w2v[word_to_index['茶叶']])
print('"车辆" 与 "茶叶" 之间的欧式距离为:',dist,'!!')
dist = np.linalg.norm(w2v[word_to_index['粮食']] - w2v[word_to_index['手表']])
print('"粮食" 与 "手表" 之间的欧式距离为:',dist,'!!')
6.2 效果呈现:
最初,经过4000条新闻的训练,词汇之间的关系还比较散乱,词语之间的关系随机性较为明显(下图左)。后经过10万条新闻的训练(花了大约24小时….),随着网络内部参数的调整,[车辆,车子],[机械,工业化]这些意义接近的词组之间的欧式距离变小,而[车辆,茶叶][粮食,手表]这些意义较远的词汇欧氏距离变大(下图右)。


但是训练的速度还是较慢,与谷歌提供的word2vec模块依然有较大差距。
七.后记:
这次自己手动实现word2vec,主要是为了巩固前期的学习成果,在实践的过程中仍然发现了不少待探究的细节。
第一个处理不到位的地方就是对不常用的词的处理方法。本次实践中,我们将其做了删除操作,将非常用词排除在样本制作之外。这样做有可能会丢失部分信息。一种处理了思路是使用unknown标签来将不常用的词进行概括,作为词汇表的一部分。
还有一个疑问就是对于标点符号的处理是否妥当。本次实践中,我们将语料中的标点进行了删除,之后再进行分词操作,主要目的是提高处理效率,但标点符号对语句结构的影响会被忽略。
当然,这次我所构架的仅仅是一个简单的结构,还有部分优化策略没有使用,导致训练速度特别的慢。一方面原因是负采样策略的缺失。如果使用采样数为5的负采样策略的话,每一次随机梯度下降过程将会只调整6个(5个负样本和一个正样本)权重值,计算量仅相当于现有情况的万分之六,训练速度也会飞速提升。(直至网络搭建完成之后,经查阅手册才发现有个tf.nn. nce-loss()函数可以实现负采样功能,后期需要继续对其进行深入学习研究。)
另一个待优化的区域是训练样本制作方面,本次实践所采用的训练样本制作方法仍较为笨拙。(该网络搭建完成后,查阅有关资料,发现tf.nn.embedding_lookup()函数可以进行查表操作,因此省去第一步one-hot向量的制作。)我在本机使用Google开发的word2vec模块,可以在几分钟之内将30多万行经过分词的语料训练完毕,而我这个手撸的CBOW网络模型训练10万行语句就消耗了24小时,其中大部分时间都消耗在了样本制作上。后续可参考word2vec的源码继续深入学习研究。
参考资料:
https://mp.weixin.qq.com/s/u2IumPRlzr4uHStrWXM87A
http://www.dataguru.cn/article-13488-1.html