粘包就是传输数据时,数据在缓冲池中粘连,无法分开.
为了解决粘包,就要知道发送方发送了多少数据,接受方就接收多少.区分开来
但是,怎么知道数据的长度呢?就需要在传送数据的时候,先将要发送的字节数告诉接收方(而且这个数字还要是固定字节数,要不我读取的时候也会发生偏差)
所以就用到了struct模块,它的功能是将,不同长度的数字,转换成固定字节数的bytes类型..
1 import struct 2 s = struct.pack("i", 1234) 3 s1 = struct.pack("i", 12345) 4 s2 = struct.pack("i", 123456) 5 print(s, len(s)) 6 print(s1, len(s1)) 7 print(s2, len(s2)) 8 9 u = struct.unpack("i", s) 10 u1 = struct.unpack("i", s1) 11 u2 = struct.unpack("i", s2) 12 print(u) 13 print(u1) 14 print(u2)
结果对照:
1 b'xd2x04x00x00' 4 2 b'90x00x00' 4 3 b'@xe2x01x00' 4 4 (1234,) 5 (12345,) 6 (123456,)
由上面代码可以看出,在接收方角度,收数据前,先recv(4),交给struck解包,接下来我再接收这个解包后数字的字节数就好了..
这就是解决粘包问题的核心思想..下面是struck的对照表
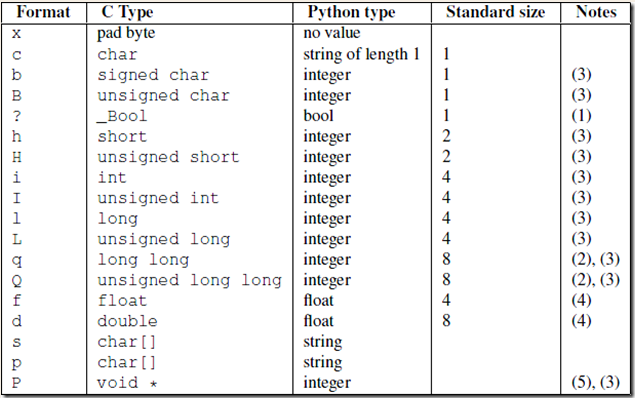
我们已经会用struck解决粘包问题了..但是又出现一个新问题.struck不能转换无限长的数字.如果大文件就很难办了
1 import struct 2 s = struct.pack("i", 1234111111111111111111111111111111111111111) 3 print(s, len(s)) 4 5 6 结果: 7 s = struct.pack("i", 1234111111111111111111111111111111111111111) 8 struct.error: argument out of range
所以,又有另外一种更高级的解决办法.就是将这个无限大的数字..封装到我的字典,列表等容器中,并用json.dumps()将字典列表转换成字节码,
再将这个字节码len()一下长度,用struck转换就容易多了..
1 import json 2 import struct 3 n = [1234111111111111111111111111111111111111111] # 不仅仅是列表,可以是字典,里面存储一些文件的名字,大小,md5等等数据.以便接收方使用 4 j = json.dumps(n).encode() 5 s = struct.pack("i", len(j)) 6 print(s, len(s)) 7 8 结果: 9 b'-x00x00x00' 4
这样子,我就是在数据的头部,先发送四个字节的struck,再发送json转换后的字节,最后在发送数据..
1 接收方先收四个字节,知道了这个json转换后的字节长度,
2 再读取这个长度的字节数,就能得到json转换后的字节数据,
3 再用loads转成对象..或者一个字典或列表等,,然后里面的值,我就可以随便应用了,
4 根据里面记录的数据的字节数,接收所有数据即可..
1 # 接收和发送文件时,控制接收数就可以解决粘包了..控制接收数(循环)可参考下面代码的while判断语句.. 2 def recv_file(file_path): 3 recv_size = 0 4 file_size = os.path.getsize(file_path) 5 with open(file_path,"ab") as f: 6 while recv_size<file_size: 7 recv_data = client.recv(1024) 8 recv_size += len(recv_data) 9 f.write(recv_size) 10 11 12 def send_file(file_path): 13 send_size = 0 14 file_size = os.path.getsize(file_path) 15 with open(file_path,"rb") as f: 16 while send_size<file_size: 17 read_data = f.read(1024) 18 send_data = server.send(read_data) 19 send_size += len(send_data)
到此,接收方粘包问题已经解决了..