在SQL Server中,UPDATE和DELETE语句是可以结合INNER/LEFT/RIGHT/FULL JOIN来使用的。
我们首先在数据库中新建两张表:
[T_A]
CREATE TABLE [dbo].[T_A]( [ID] [int] NOT NULL, [Name] [nvarchar](50) NULL, [Age] [int] NULL, CONSTRAINT [PK_T_A] PRIMARY KEY CLUSTERED ( [ID] ASC )WITH (PAD_INDEX = OFF, STATISTICS_NORECOMPUTE = OFF, IGNORE_DUP_KEY = OFF, ALLOW_ROW_LOCKS = ON, ALLOW_PAGE_LOCKS = ON) ON [PRIMARY] ) ON [PRIMARY]
[T_B]
CREATE TABLE [dbo].[T_B]( [ID] [int] NOT NULL, [Name] [nvarchar](50) NULL, [Age] [int] NULL, CONSTRAINT [PK_T_B] PRIMARY KEY CLUSTERED ( [ID] ASC )WITH (PAD_INDEX = OFF, STATISTICS_NORECOMPUTE = OFF, IGNORE_DUP_KEY = OFF, ALLOW_ROW_LOCKS = ON, ALLOW_PAGE_LOCKS = ON) ON [PRIMARY] ) ON [PRIMARY]
UPDATE与INNER/LEFT/RIGHT/FULL JOIN
UPDATE结合INNER JOIN:
TRUNCATE TABLE [T_A]; TRUNCATE TABLE [T_B]; INSERT INTO [T_A]([ID],[Name],[Age]) VALUES (1,N'Tome',10), (2,N'Jack',20), (3,N'Jim',30), (4,N'Mike',40), (5,N'Bob',50); INSERT INTO [T_B]([ID],[Name],[Age]) VALUES (1,N'Tome',100), (2,N'Jack',200), (3,N'Jim',300); UPDATE [T_A] SET Age=[T_B].Age FROM [T_A] INNER JOIN [T_B] ON [T_A].ID=[T_B].ID; SELECT * FROM [dbo].[T_A];
表[T_A]的结果如下所示:

其效果相当于通过下面INNER JOIN查询,先找出表[T_A]的数据记录,然后UPDATE这些找出的数据记录:
SELECT [T_A].*, [T_B].* FROM [T_A] INNER JOIN [T_B] ON [T_A].ID=[T_B].ID;
注意如果表[T_A]中的某行数据与表[T_B]中多行数据匹配上,这种情况下,表[T_A]的该行数据也只会被UPDATE一次,不过用表[T_B]中的哪一行匹配数据去UPDATE表[T_A]是不确定的。
UPDATE结合LEFT JOIN:
TRUNCATE TABLE [T_A]; TRUNCATE TABLE [T_B]; INSERT INTO [T_A]([ID],[Name],[Age]) VALUES (1,N'Tome',10), (2,N'Jack',20), (3,N'Jim',30), (4,N'Mike',40), (5,N'Bob',50); INSERT INTO [T_B]([ID],[Name],[Age]) VALUES (1,N'Tome',100), (2,N'Jack',200), (3,N'Jim',300); UPDATE [T_A] SET Age=[T_B].Age FROM [T_A] LEFT JOIN [T_B] ON [T_A].ID=[T_B].ID; SELECT * FROM [dbo].[T_A];
表[T_A]的结果如下所示:
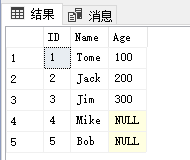
其效果相当于通过下面LEFT JOIN查询,先找出表[T_A]的数据记录,然后UPDATE这些找出的数据记录:
SELECT [T_A].*, [T_B].* FROM [T_A] LEFT JOIN [T_B] ON [T_A].ID=[T_B].ID;
UPDATE结合RIGHT JOIN:
TRUNCATE TABLE [T_A]; TRUNCATE TABLE [T_B]; INSERT INTO [T_A]([ID],[Name],[Age]) VALUES (1,N'Tome',10), (2,N'Jack',20), (3,N'Jim',30), (4,N'Mike',40), (5,N'Bob',50); INSERT INTO [T_B]([ID],[Name],[Age]) VALUES (1,N'Tome',100), (2,N'Jack',200), (3,N'Jim',300), (4,N'Mike',400), (5,N'Bob',500), (6,N'Clark',600), (7,N'Sam',700); UPDATE [T_A] SET Age=[T_B].Age FROM [T_A] RIGHT JOIN [T_B] ON [T_A].ID=[T_B].ID; SELECT * FROM [dbo].[T_A];
表[T_A]的结果如下所示:

其效果相当于通过下面RIGHT JOIN查询,先找出表[T_A]的数据记录,然后UPDATE这些找出的数据记录:
SELECT [T_A].*, [T_B].* FROM [T_A] RIGHT JOIN [T_B] ON [T_A].ID=[T_B].ID;
UPDATE结合FULL JOIN:
TRUNCATE TABLE [T_A]; TRUNCATE TABLE [T_B]; INSERT INTO [T_A]([ID],[Name],[Age]) VALUES (1,N'Tome',10), (2,N'Jack',20), (3,N'Jim',30), (4,N'Mike',40), (5,N'Bob',50); INSERT INTO [T_B]([ID],[Name],[Age]) VALUES (1,N'Tome',100), (2,N'Jack',200), (3,N'Jim',300); UPDATE [T_A] SET Age=[T_B].Age FROM [T_A] FULL JOIN [T_B] ON [T_A].ID=[T_B].ID; SELECT * FROM [dbo].[T_A];
表[T_A]的结果如下所示:
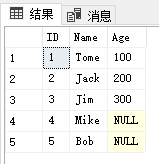
其效果相当于通过下面FULL JOIN查询,先找出表[T_A]的数据记录,然后UPDATE这些找出的数据记录:
SELECT [T_A].*, [T_B].* FROM [T_A] FULL JOIN [T_B] ON [T_A].ID=[T_B].ID;
DELETE与INNER/LEFT/RIGHT/FULL JOIN
DELETE结合INNER JOIN:
TRUNCATE TABLE [T_A]; TRUNCATE TABLE [T_B]; INSERT INTO [T_A]([ID],[Name],[Age]) VALUES (1,N'Tome',10), (2,N'Jack',20), (3,N'Jim',30), (4,N'Mike',40), (5,N'Bob',50); INSERT INTO [T_B]([ID],[Name],[Age]) VALUES (1,N'Tome',100), (2,N'Jack',200), (3,N'Jim',300); DELETE [T_A] FROM [T_A] INNER JOIN [T_B] ON [T_A].ID=[T_B].ID; SELECT * FROM [dbo].[T_A];
表[T_A]的结果如下所示:
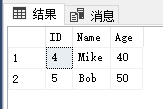
其效果相当于通过下面INNER JOIN查询,先找出表[T_A]的数据记录,然后DELETE这些找出的数据记录:
SELECT [T_A].* FROM [T_A] INNER JOIN [T_B] ON [T_A].ID=[T_B].ID;
DELETE结合LEFT JOIN:
TRUNCATE TABLE [T_A]; TRUNCATE TABLE [T_B]; INSERT INTO [T_A]([ID],[Name],[Age]) VALUES (1,N'Tome',10), (2,N'Jack',20), (3,N'Jim',30), (4,N'Mike',40), (5,N'Bob',50); INSERT INTO [T_B]([ID],[Name],[Age]) VALUES (1,N'Tome',100), (2,N'Jack',200), (3,N'Jim',300); DELETE [T_A] FROM [T_A] LEFT JOIN [T_B] ON [T_A].ID=[T_B].ID; SELECT * FROM [dbo].[T_A];
表[T_A]的结果如下所示:
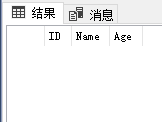
其效果相当于通过下面LEFT JOIN查询,先找出表[T_A]的数据记录,然后DELETE这些找出的数据记录:
SELECT [T_A].* FROM [T_A] LEFT JOIN [T_B] ON [T_A].ID=[T_B].ID;
DELETE结合RIGHT JOIN:
TRUNCATE TABLE [T_A]; TRUNCATE TABLE [T_B]; INSERT INTO [T_A]([ID],[Name],[Age]) VALUES (1,N'Tome',10), (2,N'Jack',20), (3,N'Jim',30), (4,N'Mike',40), (5,N'Bob',50); INSERT INTO [T_B]([ID],[Name],[Age]) VALUES (1,N'Tome',100), (2,N'Jack',200), (3,N'Jim',300), (4,N'Mike',400), (5,N'Bob',500), (6,N'Clark',600), (7,N'Sam',700); DELETE [T_A] FROM [T_A] RIGHT JOIN [T_B] ON [T_A].ID=[T_B].ID; SELECT * FROM [dbo].[T_A];
表[T_A]的结果如下所示:

其效果相当于通过下面RIGHT JOIN查询,先找出表[T_A]的数据记录,然后DELETE这些找出的数据记录:
SELECT [T_A].* FROM [T_A] RIGHT JOIN [T_B] ON [T_A].ID=[T_B].ID;
DELETE结合FULL JOIN:
TRUNCATE TABLE [T_A]; TRUNCATE TABLE [T_B]; INSERT INTO [T_A]([ID],[Name],[Age]) VALUES (1,N'Tome',10), (2,N'Jack',20), (3,N'Jim',30), (4,N'Mike',40), (5,N'Bob',50); INSERT INTO [T_B]([ID],[Name],[Age]) VALUES (1,N'Tome',100), (2,N'Jack',200), (3,N'Jim',300); DELETE [T_A] FROM [T_A] FULL JOIN [T_B] ON [T_A].ID=[T_B].ID; SELECT * FROM [dbo].[T_A];
表[T_A]的结果如下所示:
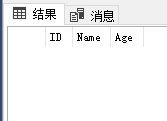
其效果相当于通过下面FULL JOIN查询,先找出表[T_A]的数据记录,然后DELETE这些找出的数据记录:
SELECT [T_A].* FROM [T_A] FULL JOIN [T_B] ON [T_A].ID=[T_B].ID;
JOIN语句使用子查询
其实我们还可以在UPDATE和DELETE语句使用JOIN时,对UPDATE和DELETE的表使用子查询,但是这种用法我个人不推荐,我们来看一个UPDATE的例子:
TRUNCATE TABLE [T_A]; TRUNCATE TABLE [T_B]; INSERT INTO [T_A]([ID],[Name],[Age]) VALUES (1,N'Tome',10), (2,N'Jack',20), (3,N'Jim',30), (4,N'Mike',40), (5,N'Bob',50); INSERT INTO [T_B]([ID],[Name],[Age]) VALUES (1,N'Tome',100), (2,N'Jack',200), (3,N'Jim',300); UPDATE [T_A] SET Age=[T_B].Age FROM ( SELECT * FROM [T_A] WHERE [T_A].ID<=2 ) AS [T_A] INNER JOIN [T_B] ON [T_A].ID=[T_B].ID; SELECT * FROM [dbo].[T_A];
表[T_A]的结果如下所示:
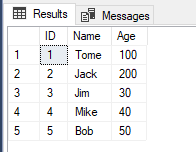
可以看到由于我们现在对表[T_A]做了子查询,用WHERE条件限制了其ID<=2,所以子查询只会返回表[T_A]的两条数据,因此最终表[T_A]只有两条数据得到了更新。
这个结果是符合我们预期的,但是其中有一个很重要的因素,就是UPDATE关键字后面的表名要和子查询的别名一致,我们对上面的UPDATE语句稍作修改,如下所示:
TRUNCATE TABLE [T_A]; TRUNCATE TABLE [T_B]; INSERT INTO [T_A]([ID],[Name],[Age]) VALUES (1,N'Tome',10), (2,N'Jack',20), (3,N'Jim',30), (4,N'Mike',40), (5,N'Bob',50); INSERT INTO [T_B]([ID],[Name],[Age]) VALUES (1,N'Tome',100), (2,N'Jack',200), (3,N'Jim',300); UPDATE [T_A] SET Age=[T_B].Age FROM ( SELECT * FROM [T_A] WHERE [T_A].ID<=2 ) AS [T_A_1] INNER JOIN [T_B] ON [T_A_1].ID=[T_B].ID; SELECT * FROM [dbo].[T_A];
现在我们将子查询的名字命名为了[T_A_1],但是我们UPDATE的表是[T_A],上面语句执行后,表[T_A]的结果如下所示:

我们可以看到表[T_A]的所有数据都被莫名其妙地更新了,我们来看看UPDATE语句的执行计划,如下所示:
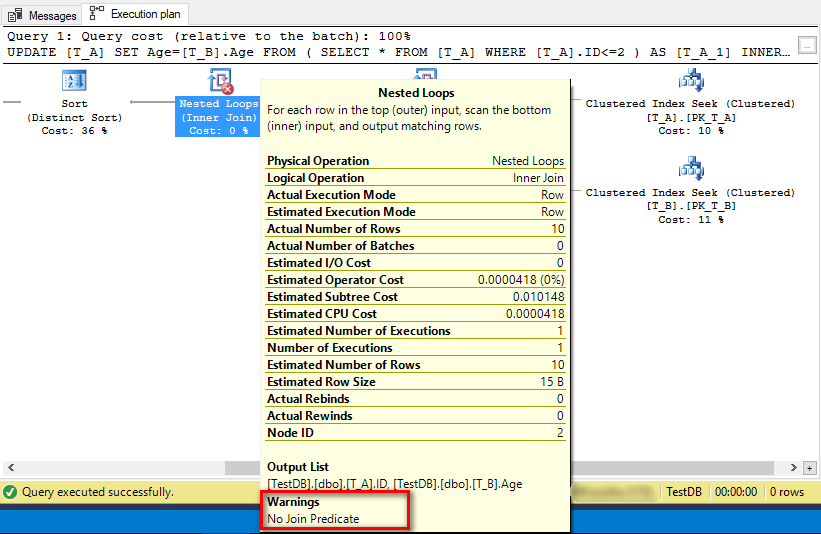
我们可以看到最关键的一个步骤,也就是表[T_A]和JOIN结果集之间的"Nested Loops"这个JOIN有个警告:"No Join Predicate",其含义就是说表[T_A]和JOIN结果集之间的JOIN是没有ON条件的,相当于CROSS JOIN,所以我们最后才看到表[T_A]的所有数据都被莫名其妙地更新了。这是因为现在UPDATE语句后面的表名[T_A]和子查询的命名[T_A_1]不一致,所以UPDATE语句现在不知道如何将[T_A_1]和[T_B]之间INNER JOIN后的结果集对应到UPDATE的表[T_A]中,所以就将表[T_A]的所有数据都更新了。
要解决这个问题其实也很简单,只要将UPDATE语句后面的表名改为子查询的名字[T_A_1],使得UPDATE语句后面的表名和子查询的名字一致就行了,如下所示:
TRUNCATE TABLE [T_A]; TRUNCATE TABLE [T_B]; INSERT INTO [T_A]([ID],[Name],[Age]) VALUES (1,N'Tome',10), (2,N'Jack',20), (3,N'Jim',30), (4,N'Mike',40), (5,N'Bob',50); INSERT INTO [T_B]([ID],[Name],[Age]) VALUES (1,N'Tome',100), (2,N'Jack',200), (3,N'Jim',300); UPDATE [T_A_1] SET Age=[T_B].Age FROM ( SELECT * FROM [T_A] WHERE [T_A].ID<=2 ) AS [T_A_1] INNER JOIN [T_B] ON [T_A_1].ID=[T_B].ID; SELECT * FROM [dbo].[T_A];
现在,表[T_A]的结果如下所示:
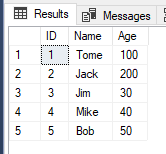
可以看到这次UPDATE语句正确地只更新了表[T_A]的两行数据,我们看看UPDATE语句的执行计划:

可以看到这次"Nested Loops"没有任何警告,正确地将表[T_A]和[T_B]进行了INNER JOIN,所以UPDATE语句只更新了表[T_A]的两行数据。这说明虽然我们在UPDATE语句后面写的是子查询的名字[T_A_1],但是UPDATE语句还是可以根据子查询[T_A_1]知道要更新的表实际上是[T_A],不得不说这一点SQL Server还是挺智能的。
但是鉴于在UPDATE和DELETE语句中使用JOIN时,再对UPDATE和DELETE的表使用子查询看起来比较怪,并且如上所示,用得不对会造成结果出错,所以我个人还是不推荐在UPDATE和DELETE语句中使用JOIN时,再对UPDATE和DELETE的表使用子查询,况且这种子查询实际上完全可以用其它方式来替代。
总结
举了这么多例子,其实我个人觉得UPDATE和DELETE语句与INNER JOIN结合使用才是最有用的,但是不管是什么JOIN,从上面的例子可以看出,其实都相当于是先用SELECT语句做表[T_A]的INNER/LEFT/RIGHT/FULL JOIN查询,然后UPDATE或DELETE表[T_A]中查询出的这些数据记录。