我们都知道在SqlServer中的nvarchar类型可以完美的存储诸如中文这种unicode字符,但是我们会发现有时候查询语句去查询nvarchar列的时候查不出来。
为什么nvarchar类型有时候需要前面带N的字符串才能查出结果
比如假如现在有一张表T_UserInfo如下,其中列[Name]为nvarchar类型用于存储中文姓名:
CREATE TABLE [dbo].[T_UserInfo]( [Id] [int] IDENTITY(1,1) NOT NULL, [Name] [nvarchar](50) NULL, [Age] [int] NULL, CONSTRAINT [PK_T_UserInfo] PRIMARY KEY CLUSTERED ( [Id] ASC )WITH (PAD_INDEX = OFF, STATISTICS_NORECOMPUTE = OFF, IGNORE_DUP_KEY = OFF, ALLOW_ROW_LOCKS = ON, ALLOW_PAGE_LOCKS = ON) ON [PRIMARY] ) ON [PRIMARY]
表中的数据如下图所示: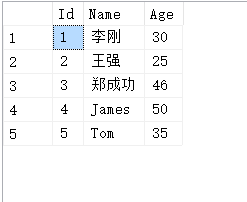
运行如下Sql查询,在有些环境是可以查出来结果的而有些环境却查不出来结果。。。
select * from [dbo].[T_UserInfo] where Name='王强'
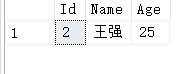
但是如果像下面这样在字符串前面加上N,无论在什么环境上都可以正确地查询出结果
select * from [dbo].[T_UserInfo] where Name=N'王强'
出现这种情况的原因就是因为SqlServer在安装的时候有些环境选择的排序规则是Latin1_General_CI_AS,而有些环境选择的排序规则是Chinese_PRC_CI_AS,导致在SqlServer上新建的数据库时有些排序规则是Latin1_General_CI_AS,有些是Chinese_PRC_CI_AS。
而当数据库的排序规则是Latin1_General_CI_AS时,那么nvarchar类型的列必须用前面带N的字符串去查询才能查出结果,如下所示:
select * from [CustomerDB].[dbo].[T_UserInfo] where Name=N'王强'--如果数据库[CustomerDB]的排序规则是Latin1_General_CI_AS那么必须要用N'王强'才能查询到结果
而当数据库的排序规则是Chinese_PRC_CI_AS时,那么nvarchar类型的列用前面带N和不带N的字符串都能查出结果,如下所示:
select * from [CustomerDB].[dbo].[T_UserInfo] where Name='王强'--如果数据库[CustomerDB]的排序规则是Chinese_PRC_CI_AS,那么用N'王强'和'王强'都能查询到结果
更改数据库的排序规则
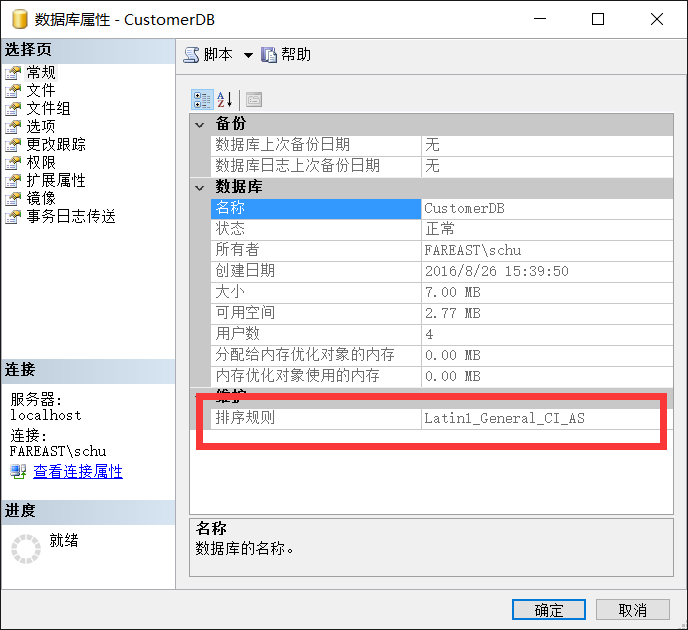
知道了这个问题那么我们来尝试下更改数据库的排序规则,如下图所示当前SqlServer中数据库CustomerDB的排序规则是Latin1_General_CI_AS的
现在我们使用下面的alter database语句将其排序规则改为Chinese_PRC_CI_AS(注意alter database语句需要在没人用数据库的时候才能成功执行,所以最好将数据库设置为single user模式后,再运行alter database语句)
alter database [CustomerDB] collate Chinese_PRC_CI_AS
然后再查看其数据库属性,发现CustomerDB的排序规则已经变为了Chinese_PRC_CI_AS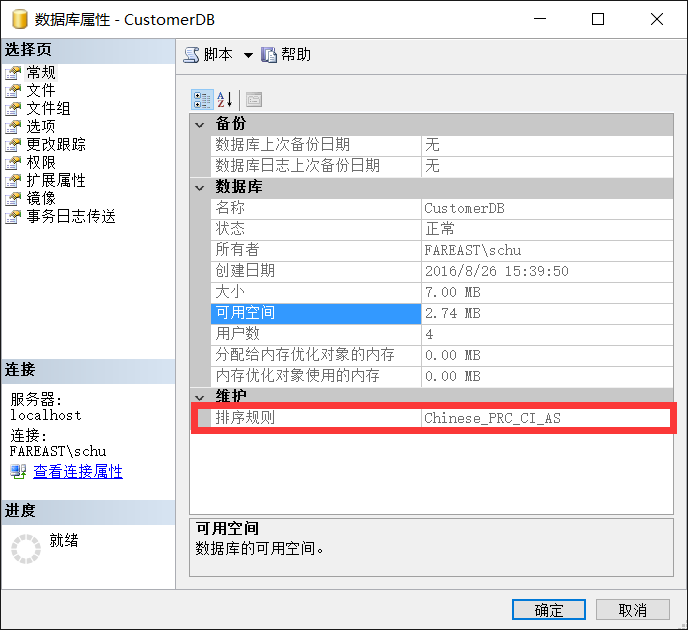
这个时候无论[T_UserInfo]表的[Name]列是什么排序规则,用N'王强'和'王强'都能查询出来结果,例如下图中我们看到虽然列[Name]的排序规则是Latin1_General_CI_AS,但是由于现在数据库CustomerDB的排序规则是Chinese_PRC_CI_AS,所以用'王强'是可以查询出结果的
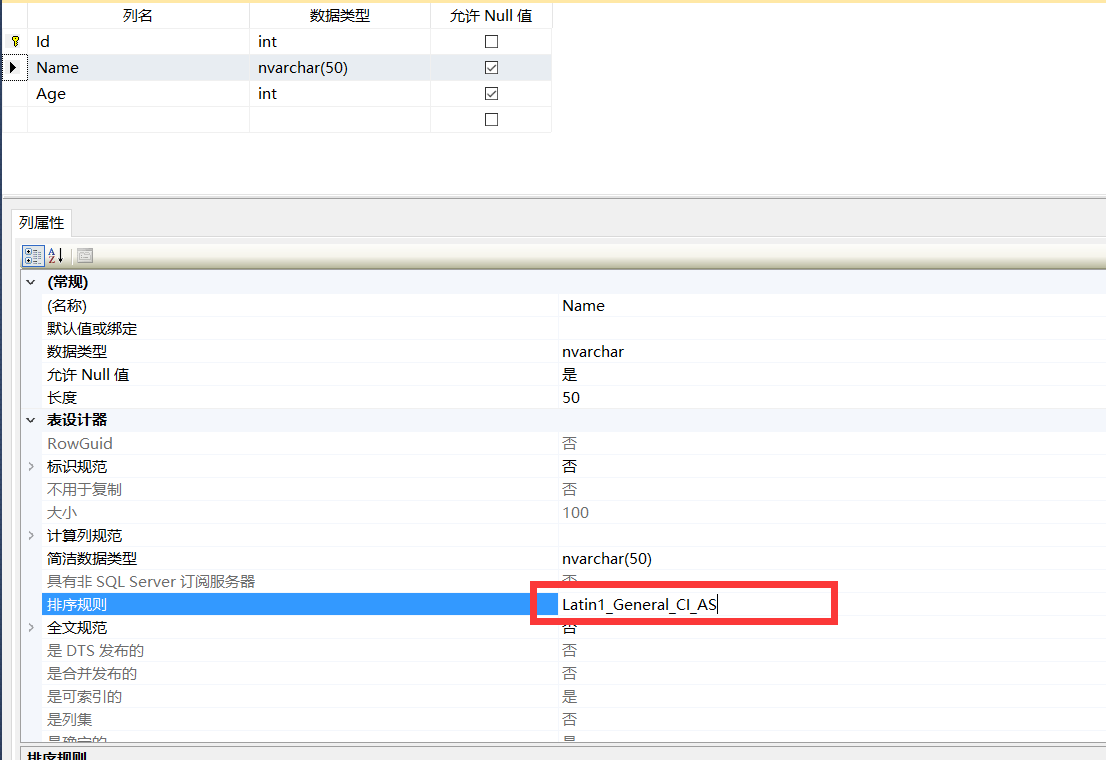
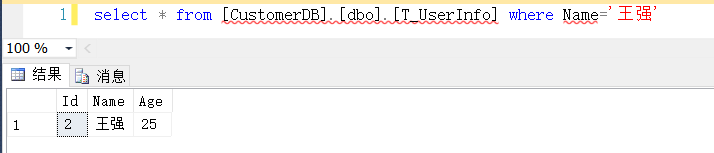
更改数据库实例的排序规则
我们知道新建数据库时,数据库的默认排序规则就是数据库实例的当前排序规则,那么如果将数据库实例的排序规则设置为我们想要的值后,新建的数据库自然也是预期的排序规则,下面介绍如何用命令行更改数据库实例的排序规则。
首先我们可以看到数据库实例MSSQLSERVER当前的排序规则是Latin1_General_CI_AS
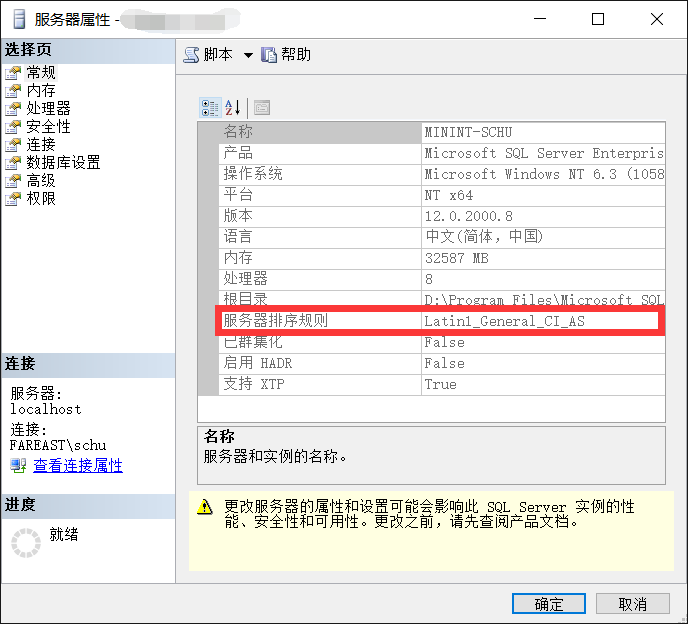
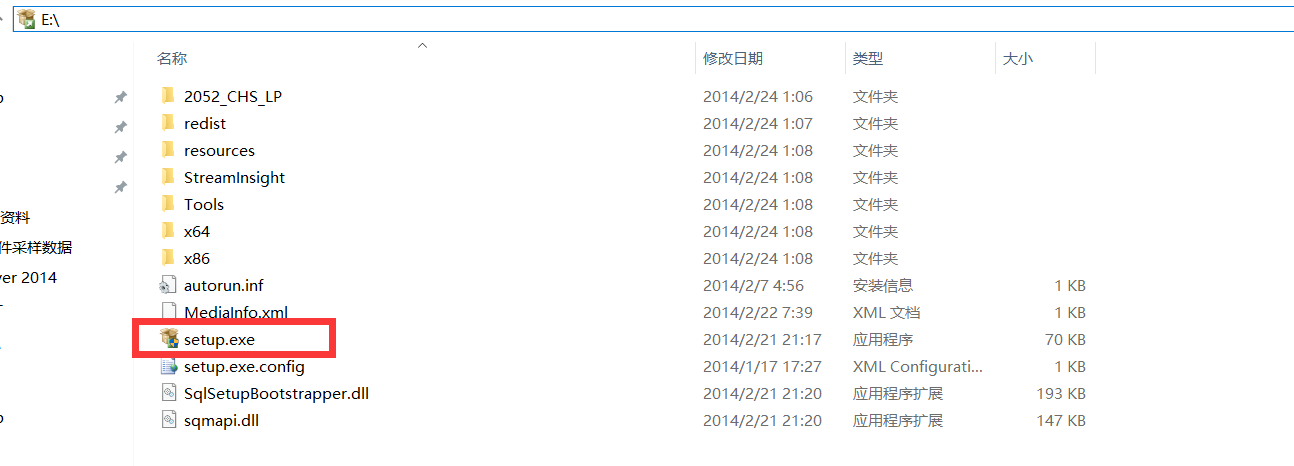
现在使用操作系统管理员权限启动cmd,也就是命令行提示符,然后定位到SqlServer安装文件所在的目录,在本例中我的SqlServer安装文件就在E盘(主要就是要找到安装文件setup.exe所在的目录)。
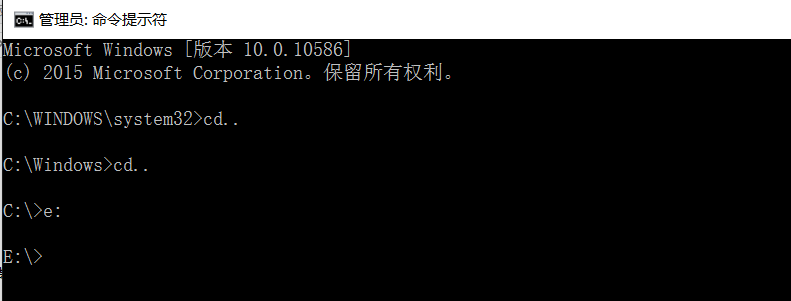
然后使用NET STOP MSSQLSERVER停止SqlServer服务,其中MSSQLSERVER就是你要更改SqlServer实例的windows服务名称

然后在命令行中使用如下命令调用setup.exe(注意:当使用Setup命令后,所更改数据库实例中的所有用户数据库都会被脱机(系统数据库不会),你需要在使用Setup命令后重新附加所有的用户数据库到数据库实例)
Setup /QUIET /ACTION=REBUILDDATABASE /instancename=<数据库实例名> /SQLSYSADMINACCOUNTS=<数据库管理员账号> /sapwd=<数据库管理员密码> /sqlcollation=Chinese_PRC_CI_AS
虽然MSDN说上面的sapwd参数可以省略,但是测试发现如果省略了这个参数,待上面的setup命令执行完后,数据库实例的排序规则还是没有改变,所以这里建议一定要使用sapwd参数输入数据库管理员账号的密码
现在执行上面的Setup命令

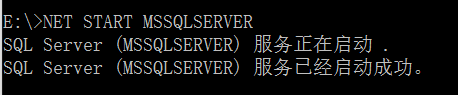
等待几分钟的时间setup命令执行完毕,然后我们再使用NET START MSSQLSERVER命令启动SqlServer服务
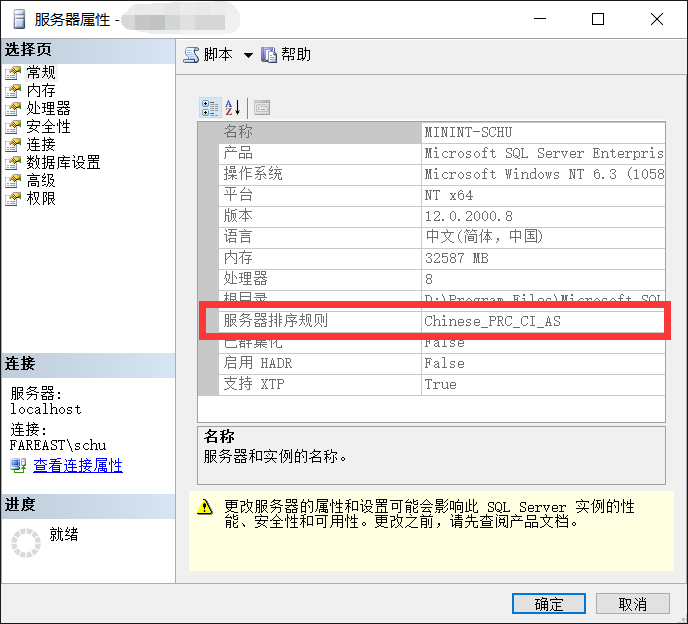
现在再查看数据库实例MSSQLSERVER的排序规则,可以看到数据实例MSSQLSERVER的排序规则已经变为了Chinese_PRC_CI_AS
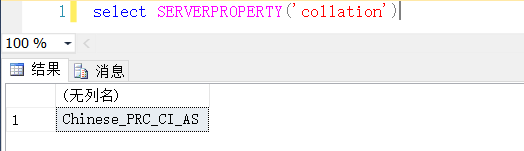
另外使用下面的Sql查询也可以查到当前连接到数据库实例的排序规则
select SERVERPROPERTY('collation')
SqlServer的排序规则关系到表的列,数据库及数据库实例,知道怎么配置排序规则对使用SqlServer还是比较重要的,希望通过本文大家能有所收获,谢谢!