Semi-Supervised Learning
半监督学习(二)
介绍
在上篇文章中我们介绍了关于统计机器学习和半监督学习的一些基本概念。在这篇文章中,我们仍着重带读者更深入地了解半监督学习基础,了解半监督学习的常用方法,模型假设,并且通过实例带读者去理解半监督学习的过程。难度依然较基础,但是相信读完这篇文章,你会对半监督学习是什么有完整的把握。
半监督学习方法
半监督学习方法有很多,不同的方法往往基于边缘分布P(x)与条件分布P(y|x)之间关系的不同假设。
通常我们将半监督方法分为以下几类:self-training, probabilistic generative models, co-training, graph-based models, semi-supervised support vector machines等,在接下来的内容中,我们将分别介绍这些方法以及它们所基于的假设。
虽然半监督的方法很多,但是如果盲目地选择并不一定能提升监督学习的表现,事实上,使用错误的假设,无标签数据反而会使模型的表现更差。
下面,我们通过简单的例子来证明模型假设的敏感性,通过比较在简单分类问题上,监督学习和半监督学习的表现来阐述。
例子
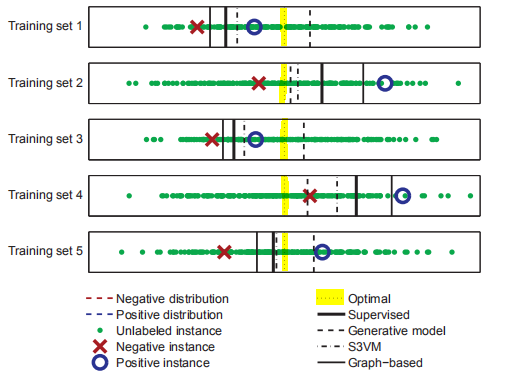
有一个二分类问题,每个类服从高斯分布,且这两个类的高斯分布大量重叠,如下图所示:

可以看出,真实的决策边界就在两个分布的中间(黄线),由于我们知道真实分布,我们可以根据落在决策边界不正确一侧的每个高斯概率质量来计算测试样本错误率。由于类分布的重叠,最优误差率(Bayes误差)为21.2%。
不同算法表现比较
-
监督学习:从图中可以看出,学习到的决策边界位于两个有标签样本(忽略无标签数据,即图中绿色的点)的中间,偏离了真实的决策边界,根据有标签数据的随机采样不同,学习到的决策边界也不同,但是大概率地也会偏离真实边界。为了比较监督学习和半监督学习的表现,我们采样了1000个样本点,其中每一种类别分别采样一个有标签数据和99个无标签数据(如上图五组测试样例),在该训练集上通过监督学习得到的决策边界的分类错误率为31.6%,虽然决策边界的均值是0.02(很接近真实边界0),但是标准差为0.72;
下面几种算法属于半监督学习,今天我只对比实验效果,下一篇文章中会给出每一种模型的详细介绍:
-
概率生成模型(Generative model):通过EM学习两个高斯分布(该模型做出了正确的假设),从图中可以看出,学习到的决策边界比较接近真实边界,而且方差也比较小。其在1000个样本上的平均误差为30.2%,平均决策边界为-0.003,标准差为0.55,表明该算法比监督学习更优;
-
半监督支持向量机(S3VM):它假设决策边界不应该通过密集的样本区域,然而我们的两类样本重叠比较严重,所以真实的边界其实是闯过点密集的区域的(假设不成立)。这种状况下学习到的决策边界又会怎么样呢?从图中我们可以看出学习到的决策边界仍优于监督学习,和生成模型方法效果差不多。平均误差为29.6%,平均决策边界为0.01,标准差为0.48。可以看到,虽然模型假设是错误的,但由于该方法使用的两种类别样本数相同(太理想),所以决策边界接近于中心;
-
基于图的模型(graph-based):标记数据和未标记数据两两之间都用一条边相连,边权重用两点之间的距离来衡量(近则权重大)。该模型的假设是两个点之间的权重越大越趋于同一个类。显然,这个假设在我们的样本上并不成立(分布重叠区靠的近的点可能属于不同的类),那它的表现如何呢?它的错误率是36.4%,平均决策边界是0.03,标准差是1.23,表现比监督学习还差得多。
上面的实验说明模型假设在半监督学习中至关重要,它弥补了标签缺失的不足,决定了判别器的质量,然而做出正确假设仍然是半监督学习中待解决的问题。
接下来,我们先介绍一种简单的半监督学习模型Self-Training Model 作为半监督算法学习的入门。
Self-Training
Self-Training是最经典的半监督学习方法,他的特点是学习的过程是使用自己的预测器来自学习,因此也叫自学习模型。
算法伪代码:

![]()
算法的主要思想是先在有标签数据上训练一个模型f,然后用f取预测无标签数据,然后取出部分数据加入有标签数据集,然后又在扩充后的有标签数据集上重新训练模型,重复上述流程。
Self-Training Assumption:
该算法基于的假设是训练出来的模型很大概率是正确的。它的优点是简单,模型的选择也是开放的,比如可以是简单的kNN模型,或者非常复杂的分类器,通过一层层“包裹”分类模型而不改变实际内部机制。这种模型在很多场景下都适用,比如自然语言处理中,因为模型通常是复杂的黑盒模型,不适应变化。但是,由于初始有标签样本比较少,学习到的模型并不好,生成错误标签的数据反而会使得在下一轮生成更加错误的模型,当然,很多启发式的方法已经被用来改善这个问题,比如propagating 1-nearest-neighbor算法。
propagating 1-nearest-neighbor

算法的思想是每一轮都选一个距离有标签数据集中某一个点最近的无标签数据,并打上相同的标签加入有标签数据集中,循环直到所有无标签数据都打上标签。我们来看该算法的一个应用:
假设有100个样本其中只有2个有标签分别表示男性和女性,其他98个没有标签,每个样本有两个维度特征(weight & height),现在要为98个人预测其性别。
下图展现了使用propagating 1-nearest-neighbor算法一定轮数的迭代后样本的分类状况。由于该算法的假设(这些类形成分类良好的簇)符合实验样本的分布,所以模型的效果很好。
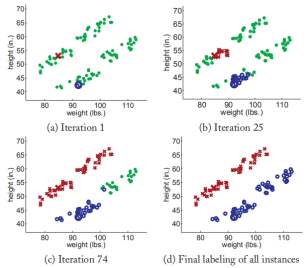
接着我们在上一个实验中的两个类之间添加一个离群点,这个离群点打破了上述假设,来看看实验效果如何吧?
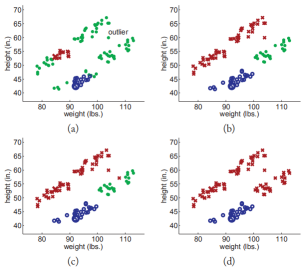
显然,self-training方法,比如说propagating 1-nearest-neighbor对离群点很敏感会导致错误。
总结:
今天的内容仍然是半监督学习的入门内容,结合上一篇文章相信你已经理解了什么是半监督学习,以及半监督学习一般的学习过程,接下来的文章会开始详细介绍和分享几种经典的,以及近几年提出的半监督学习算法!
希望大家多多支持我的公众号,扫码关注,我们一起学习,一起进步~
