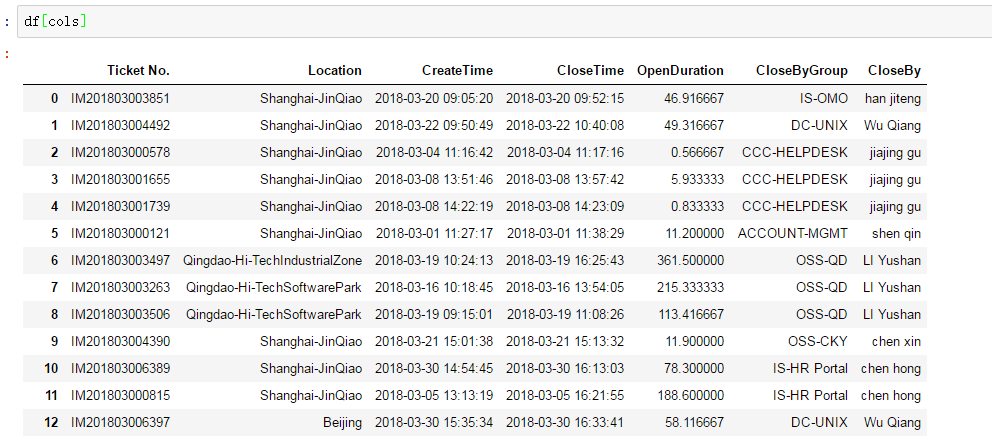
作业要求
我们尝试 ? Pandas 来玩玩一些真实的数据。文 ? tickets_201803.csv 含有三月份中国区ITSM的支持数据 ?
大约这么个样子

简单整理后
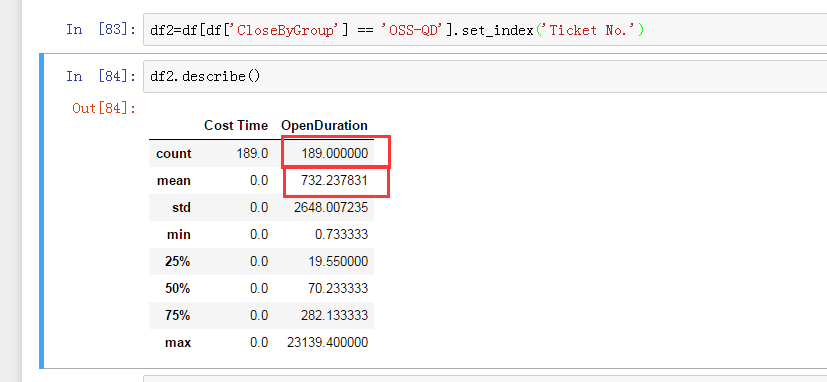
练习1:求OSS-QD ?3月份的Ticket数量和Ticket平均解决时间在中国区的名次 ?
df = pd.read_csv('tickets_201803.csv') cols = ['Ticket No.', 'Location', 'CreateTime', 'CloseTime', 'OpenDuration', 'CloseByGroup', 'CloseBy',] df2=df[df['CloseByGroup'] == 'OSS-QD'].set_index('Ticket No.') #这里当最普通的条件过滤理解即可 df[df['num']>5] df2.groupby('')
运行结果
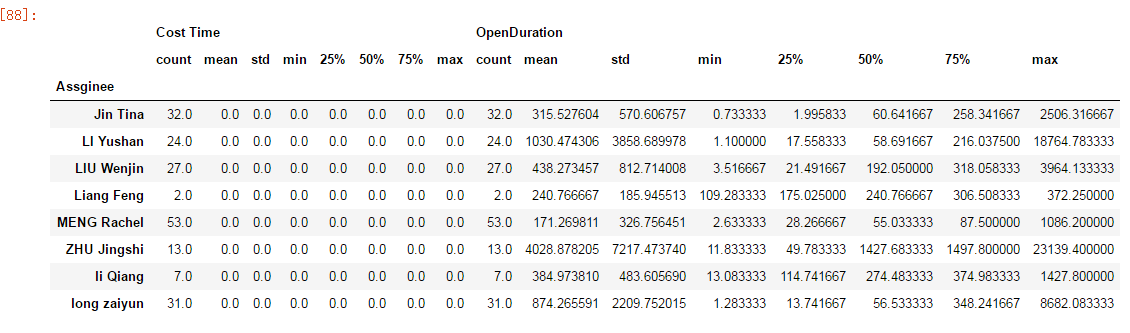
#练习2:求OSS-QD组各个工程师的Ticket相关统计
继续上边的不变
df2=df[df['CloseByGroup'] == 'OSS-QD'].set_index('Ticket No.') df2.describe() group=df2.groupby('Assginee') group.describe()
运行结果
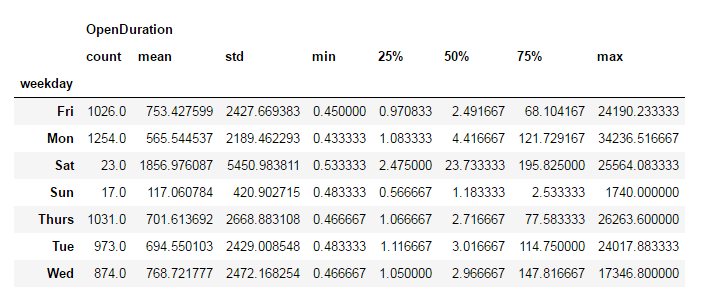
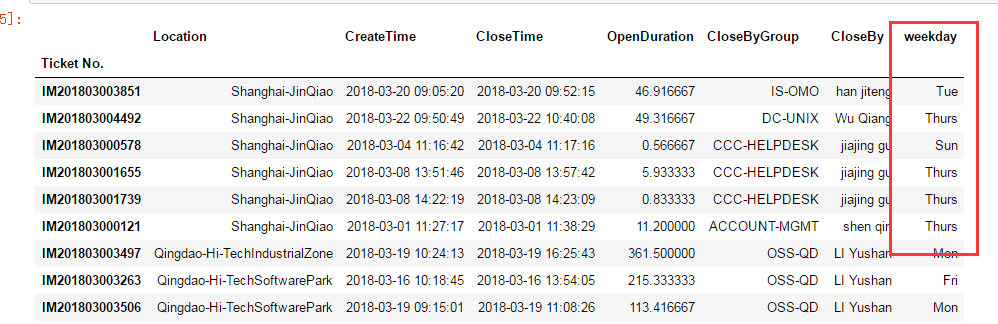
#练习3: 为df1添加一列,列的内容是对应每条Ticket所对应日期在一周中的名 ?
df1 = df[cols].set_index('Ticket No.') a=df1['CreateTime'].dt.weekday # 一个时间序列的 dt 对象可以返回很多有用的属性,weekday就是其中之一 df1['weekday']=a #把a列添加到df1 weekday_dic={0:'Mon',1:'Tue',2:'Wed',3:'Thurs',4:'Fri',5:'Sat',6:'Sun'} #生成一个日期对应的字典 df1['weekday']=df1['weekday'].map(weekday_dic) #进行替换操作 group=df1.groupby('weekday') group.describe() #进行数据分析 df1.to_csv('newtickets_201803.csv') # 保存整理过的数据
运行结果
进行数据分析