作为一个师父离职早的野生程序员,业务方面还可以达到忽悠别人的水平,但上升到性能层面那就是硬伤。
真是天上掉馅饼,公司分配了一个测试性能的任务,真是感觉我的天空星星都亮了。
高并发主要限制因素:CPU、网络流量、内存、系统配置
CPU
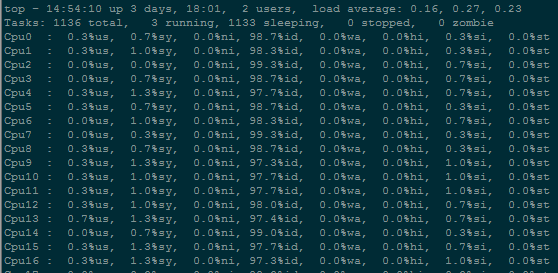
用top看cpu利用率,按1查看每个cpu线程的工作情况;这里面会显示出cpu的空闲、利用率、软中断等状态
如果某个cpu线程使用率经常达到100%,那cpu就成了瓶颈,通常为了实现高并发,负载比较大的服务程序会自己绑定cpu,使自己的任务分配到多个cpu线程中去,以保证程序稳定运行
绑定CPU的方法:
nCPUIndex 表示 CPU 序号,从 0 开始编号。
cpu_set_t mask;
CPU_ZERO(&mask);
CPU_SET(nCPUIndex, &mask);
sched_setaffinity(m_hThread, sizeof(mask), &mask);
当然yum install irqbalance也是一个不错的选择。
网卡流量
对于流媒体服务器来说,网卡绝对是主要瓶颈,即使是万兆网卡,面对1Mbps的码流,并发也只有1万;
网卡流量主要通过dstat -N来指定多网卡进行监控,在单机测试过程中,就需要CCIE的支持了:
(1)首先用bond(mod4)绑定多个网卡,但是相应的万兆交换机也需要与服务器这边一致。
这边有个知识点就是“多网卡绑定的七种模式”,好的交换机支持更多的网口负载方式,会让各网口流量基本均衡。
如果配置差错,在dstat统计的过程中就会发现,有些网卡流量满了,但是有些却没有流量,导致测试实例大量掉线;

dstat功能很全,cpu、内存都可以指定,比如read列流量高,就表明程序读写磁盘的操作比较频繁。
(2)另外,网卡cpu中断也最好要进行确认:
查看当前网卡的终端号:cat /proc/interrupts | grep eth1
查看当前网卡分配的CPU(98是第一步的结果):cat /proc/irq/98/smp_affinity_list
将比较空闲的CPU分配给该网卡:echo 1,2,3 >/proc/irq/98/smp_affinity_list
内存
可以用top、free -m等查看,反正耗得太多就是程序的问题了。free的各个值也可以看出程序的运行原理。
[root@cdn02 ~]# free -m
total used free shared buffers cached
Mem: 31993 1596 30397 0 12 22
-/+ buffers/cache: 1562 30431
Swap: 15999 7 15992
otal——总物理内存
used——已使用内存,一般情况这个值会比较大,因为这个值包括了cache+应用程序使用的内存
free——完全未被使用的内存
shared——应用程序共享内存
buffers——缓存,主要用于目录方面,inode值等(ls大目录可看到这个值增加)
cached——缓存,用于已打开的文件
note:
total=used+free
used=buffers+cached (maybe add shared also)
第二行描述应用程序的内存使用:
前个值表示-buffers/cache——应用程序使用的内存大小,used减去缓存值
后个值表示+buffers/cache——所有可供应用程序使用的内存大小,free加上缓存值
note:
-buffers/cache=used-buffers-cached
+buffers/cache=free+buffers+cached
第三行表示swap的使用:
used——已使用
free——未使用
系统参数
之前都是玩虚拟机,
文件描述符神马的一般配置成65535也就没发现什么问题,
也不会认为处于TIME_WAIT状态的socket有什么不好
但是这些对于高并发的服务器来说却是非常重要的
频繁的http服务会建立大量的短连接,就会有大量的TIME_WAIT在2ML的超时时间内,占用描述符,
如果恰巧配置的系统最大描述符又很小,性能当然也就上不去。
系统配置主要是修改:/etc/sysctl.conf 文件,修改之后sysctl -p进行更新
net.ipv4.tcp_max_tw_buckets = 6000
timewait 的数量,默认是180000。
net.ipv4.ip_local_port_range = 1024 65000
允许系统打开的端口范围。
net.ipv4.tcp_tw_recycle = 1
启用timewait 快速回收。
net.ipv4.tcp_tw_reuse = 1
开启重用。允许将TIME-WAIT sockets 重新用于新的TCP 连接。
net.ipv4.tcp_syncookies = 1
开启SYN Cookies,当出现SYN 等待队列溢出时,启用cookies 来处理。
net.core.somaxconn = 262144
web 应用中listen 函数的backlog 默认会给我们内核参数的net.core.somaxconn 限制到128,而nginx 定义的NGX_LISTEN_BACKLOG 默认为511,所以有必要调整这个值。
net.core.netdev_max_backlog = 262144
每个网络接口接收数据包的速率比内核处理这些包的速率快时,允许送到队列的数据包的最大数目。
net.ipv4.tcp_max_orphans = 262144
系统中最多有多少个TCP 套接字不被关联到任何一个用户文件句柄上。如果超过这个数字,孤儿连接将即刻被复位并打印出警告信息。这个限制仅仅是为了防止简单的DoS 攻击,不能过分依靠它或者人为地减小这个值,更应该增加这个值(如果增加了内存之后)。
net.ipv4.tcp_max_syn_backlog = 262144
记录的那些尚未收到客户端确认信息的连接请求的最大值。对于有128M 内存的系统而言,缺省值是1024,小内存的系统则是128。
net.ipv4.tcp_timestamps = 0
时间戳可以避免序列号的卷绕。一个1Gbps 的链路肯定会遇到以前用过的序列号。时间戳能够让内核接受这种“异常”的数据包。这里需要将其关掉。
net.ipv4.tcp_synack_retries = 1
为了打开对端的连接,内核需要发送一个SYN 并附带一个回应前面一个SYN 的ACK。也就是所谓三次握手中的第二次握手。这个设置决定了内核放弃连接之前发送SYN+ACK 包的数量。
net.ipv4.tcp_syn_retries = 1
在内核放弃建立连接之前发送SYN 包的数量。
net.ipv4.tcp_fin_timeout = 1
如果套接字由本端要求关闭,这个参数决定了它保持在FIN-WAIT-2 状态的时间。对端可以出错并永远不关闭连接,甚至意外当机。缺省值是60 秒。2.2 内核的通常值是180 秒,3你可以按这个设置,但要记住的是,即使你的机器是一个轻载的WEB 服务器,也有因为大量的死套接字而内存溢出的风险,FIN- WAIT-2 的危险性比FIN-WAIT-1 要小,因为它最多只能吃掉1.5K 内存,但是它们的生存期长些。
net.ipv4.tcp_keepalive_time = 30
当keepalive 起用的时候,TCP 发送keepalive 消息的频度。缺省是2 小时。
应用程序本身的配置
比如nginx,最好根据cpu的线程数去配置worker;要开启epoll模式,要开启sendfile等等就不说了。