数据库EER图
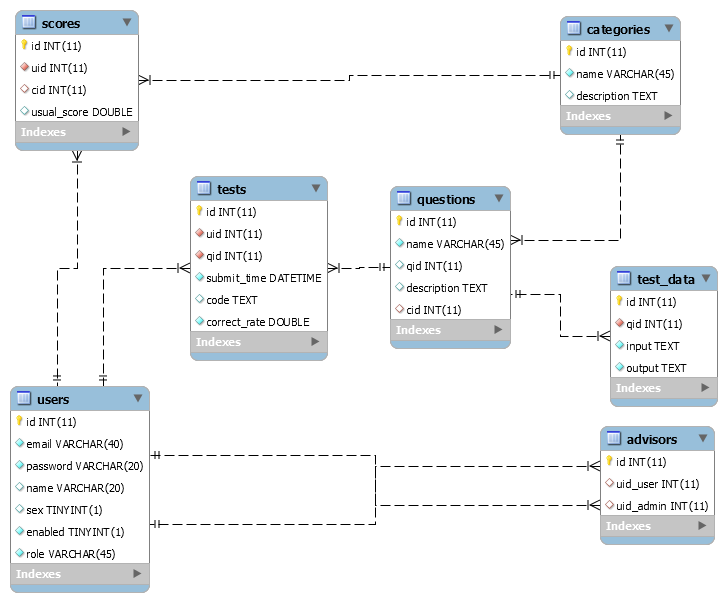
数据库表、字段、约束解释
users 用户:
id 标识符,email 邮箱,password 密码,name 姓名,sex 性别,enabled 启用 ,role 角色
id primary key
advisors 指导:
id 标识符,uid_user 被指导者,uid_admin 指导者
id primary key
uid_user -> user(id),uid_admin(id)
categories 类别:
id 标识符,name 名称,description 描述
id primary key
questions 问题:
id 标识符,qid 题号,description 描述,cid 类别标识符,name 名称
id primary key
cid -> categories(id)
test_data 测试数据:
id 标识符,qid 题号,input 一组输入,output 一组输出
id primary key
qid -> questions(id)
tests 测试信息:
id 标识符,uid 用户标识符,qid 题号,submit_time 提交时间,code 代码,correct_rate 正确率
id primary key
uid -> users(id),qid -> questions(id)
scores 成绩:
id 标识符,uid 用户标识符,cid 类别标识符,usual_score 平时成绩
复杂SQL语句
selectSumScoreAndRank:
功能:根据用户 ID,查询用户 ID、用户所有题目总成绩、总成绩的排名。
实现:主要是利用了聚集函数,MySQL 自带 @rowNum 属性。
代码:
SELECT * FROM (SELECT uid, sum_correct_rate, (@rowNum := @rowNum + 1) AS rank FROM (SELECT uid, sum(max_corrcet_rate) AS sum_correct_rate FROM (SELECT uid, qid, max(correct_rate) AS max_corrcet_rate FROM tests GROUP BY uid, qid) AS max_tests GROUP BY uid ORDER BY sum_correct_rate DESC) AS rank_tests, (SELECT (@rowNum := 0)) AS rank) AS all_tests WHERE uid = #{uid}
selectPracticeAndUsualScoreFromAdmin:
功能:根据管理员 ID 和类别 ID,查询特定管理员的指导关系下用户的实践成绩和平时成绩。
实现:首先根据指导关系下的用户 ID 和特定题库 ID 选出特定题目,再根据特定题目选出特定测试,最后利用聚集函数进行成绩整合(例如,聚集函数 sum 计算特定用户特定题库下的总分)。
代码:
SELECT scores.id, scores.uid, users.email, users.name AS userName, sum_tests.avg_correct_rate * 100 AS practice_score, scores.usual_score FROM (SELECT uid, avg(max_corrcet_rate) AS avg_correct_rate FROM (SELECT uid, qid, max(correct_rate) AS max_corrcet_rate FROM (SELECT uid, qid, correct_rate FROM tests WHERE uid IN (SELECT uid_user FROM advisors WHERE uid_admin = #{uidAdmin}) AND qid IN (SELECT questions.id FROM categories LEFT JOIN questions ON categories.id = questions.cid WHERE cid = #{cid}) ) AS filter_tests GROUP BY uid, qid) AS max_tests GROUP BY uid) AS sum_tests LEFT JOIN scores ON sum_tests.uid = scores.uid AND scores.cid = #{cid} LEFT JOIN users ON sum_tests.uid = users.id
设计思想
1、为什么要每张表都有 ID,并且把 ID 作为主键?
表的主键不应该可以变动的,而现实中的需求会变动。起初,表 questions 是没有列 cid 的,后来为了模拟现实中题目(questions)的类别(categories), 增加了 cid 列。
假设有一种情况:
类别名(categories name)为 Java,题号(qid)为 1,2,3;类别为 C#,题号为1,2,3。
如果表 questions 以 qid 作为主键,上述的情况是无法实现的,因为primary key 违反了唯一性约束,需要重新设计架构;如果表 questions 以无意义的 id 作为主键,上述情况实现很简单,不需要变动架构。
所以,表的主键最好是无意义的id。
2、表 questions 和表 test_data 的设计
表 questions 起初和 test_data 是放在一起的,即 input 和 output 起初是在表 questions 中的,并且每条记录表示的多组输入和多组输出。后来我剥离了,并且将每条记录由多组输入和多组输出变为一组输入和一组输出,原因如下:
① 多组的输入或者多组的输出不方便保存。如果合并为一组保存,必须以一个符号作为分隔符,然而在 OJ 系统,任何符号的输入都是有可能的,分隔符无法选择
② 如果采用多组保存,冗余性较高,qid、name等多保存了很多次。
所以,我采取弱关联(将多值属性剥离,新建一个表存入,新表高度依赖于原来的表)来保存。