1. 应用K-means算法进行图片压缩
1) 读取一张图片
china = load_sample_image("china.jpg")
# 显示原图片
plt.imshow(china)
plt.show()
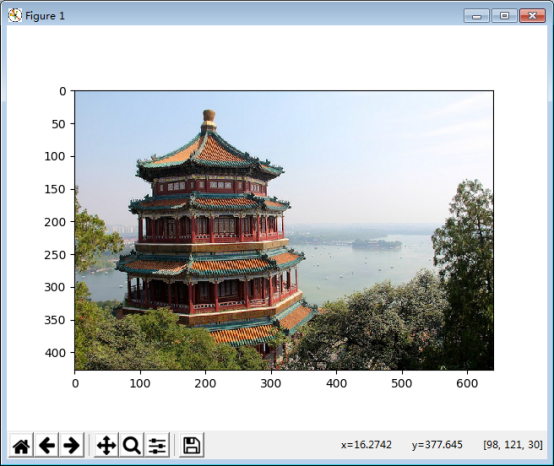
2) 观察图片文件大小,占内存大小,图片数据结构,线性化

3) 用kmeans对图片像素颜色进行聚类
4) 获取每个像素的颜色类别,每个类别的颜色
5) 压缩图片生成:以聚类中收替代原像素颜色,还原为二维
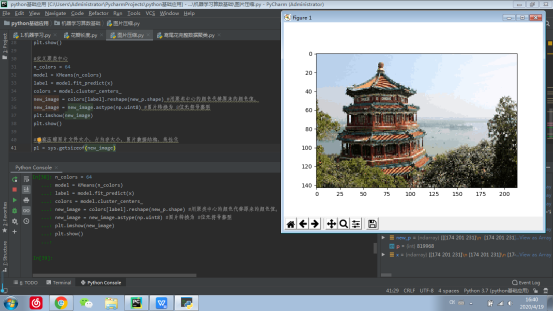
6) 观察压缩图片的文件大小,占内存大小

2. 观察学习与生活中可以用K均值解决的问题。
从数据-模型训练-测试-预测完整地完成一个应用案例。
这个案例会作为课程成果之一,单独进行评分。
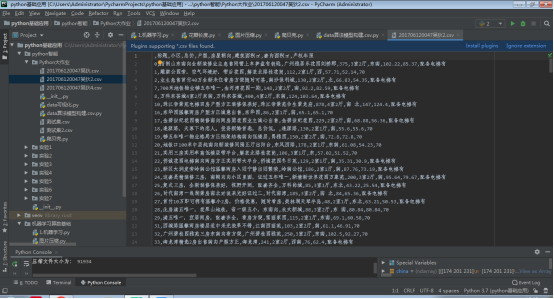
图为201706120047吴狄2.csv数据
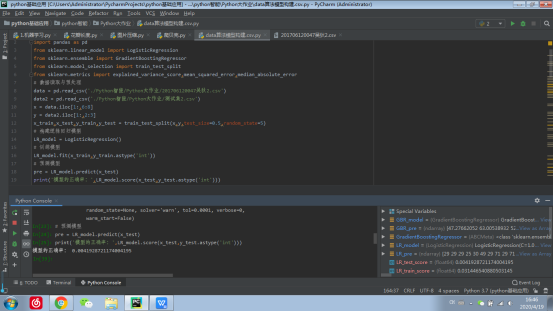
代码:
import pandas as pd
from sklearn.linear_model import LogisticRegression
from sklearn.ensemble import GradientBoostingRegressor
from sklearn.model_selection import train_test_split
from sklearn.metrics import explained_variance_score,mean_squared_error,median_absolute_error
# 数据读取与预处理
data = pd.read_csv('./Python智能/Python大作业/201706120047吴狄2.csv')
data2 = pd.read_csv('./Python智能/Python大作业/测试集2.csv')
x = data.iloc[1:,6:8]
y = data2.iloc[1:,2:3]
x_train,x_test,y_train,y_test = train_test_split(x,y,test_size=0.5,random_state=5)
# 构建逻辑回归模型
LR_model = LogisticRegression()
# 训练模型
LR_model.fit(x_train,y_train.astype('int'))
# 预测模型
pre = LR_model.predict(x_test)
print('模型的正确率:',LR_model.score(x_test,y_test.astype('int')))
LR_model =LogisticRegression().fit(x_train,y_train.astype('int'))