课程评分标准:
考勤 10
平时作业 30
爬虫大作业 20
Hadoop生态安装与配置 20
Hadoop综合大作业 20
12周演示检查:《爬虫大作业》和《Hadoop安装与配置》
Hadoop综合大作业 要求:
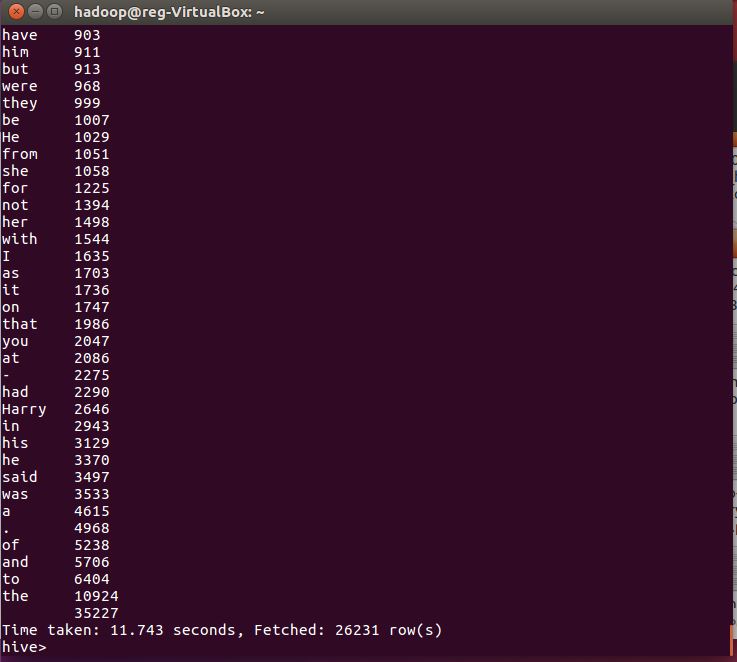
1.用Hive对爬虫大作业产生的文本文件(或者英文词频统计下载的英文长篇小说)进行词频统计。
词频分析英文小说:链接:https://pan.baidu.com/s/1ns-TjuHEU2WVpHZWWVFj9g 密码:61ua
PS:由于在最后数据展现的时候 把前面所打的代码过页处理。利用上一条截图如下
下面前2句相当于 start-all.sh 进入HDFS环境












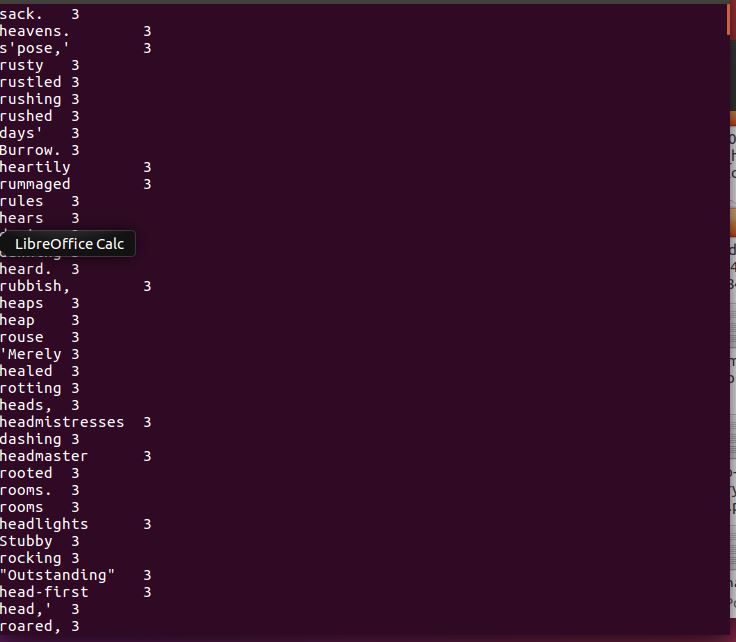
2.用Hive对爬虫大作业产生的csv文件进行数据分析,写一篇博客描述你的分析过程和分析结果。
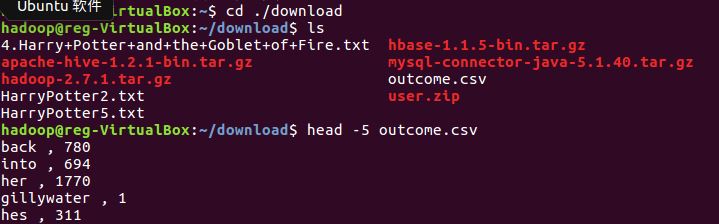
将数据以csv格式上传到hdfs
进入文件路径并查看数据前5
将文件上传到HDFS上

查看上传成功的文件的前20个数据
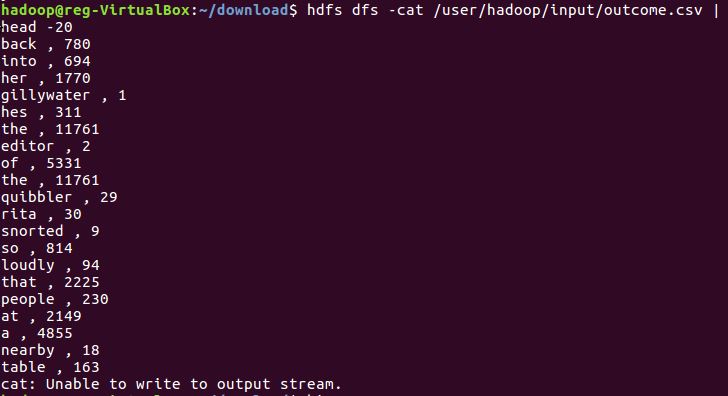
进入hive环境
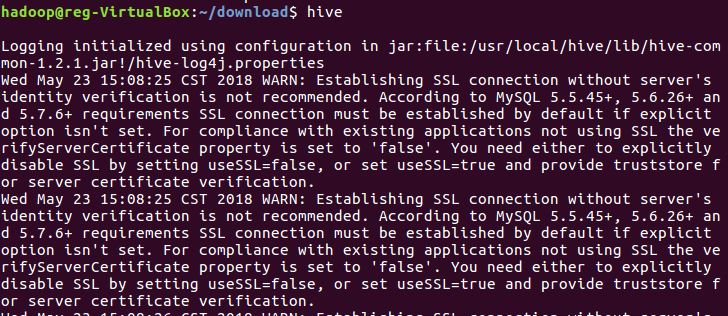
创建数据库和表 并将文件复制到表中
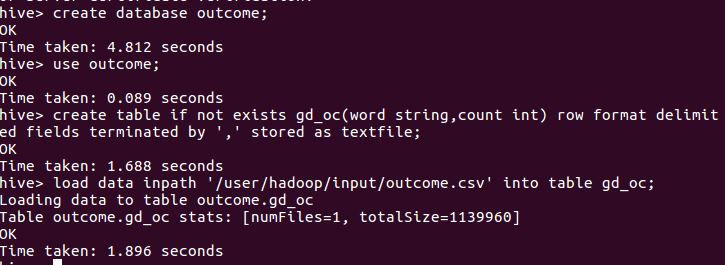
查看数据总条数
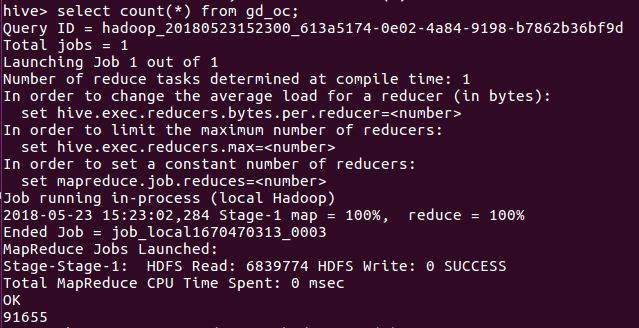
根据count查看数据的前50条
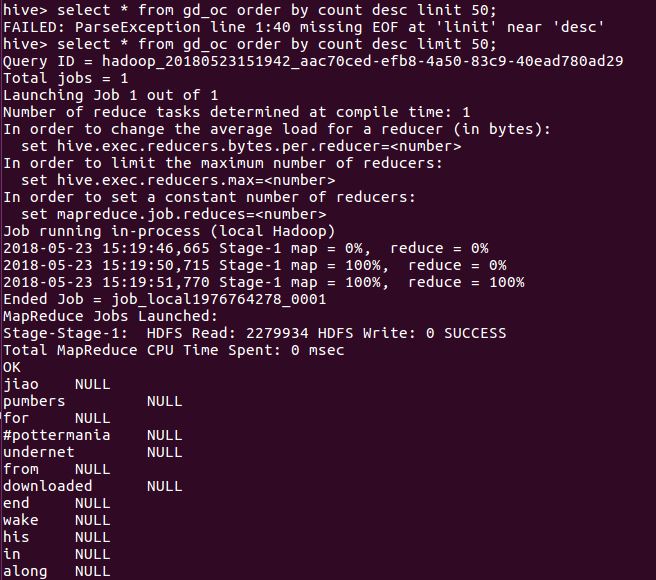
心得:在单词统计输出中加多一个逗号以方便形成CSV格式文件。在Hadoop中运行的时候 最后数据显示的结果全是NULL,但是目前还不知道是什么原因。可能是在分词的时候用上了逗号 使数据成为了,+数据 导致数据无法辨别成整数。