首先明确分析的思路
步骤:一、提出问题
二、理解数据
1、导入数据
2、查看数据集信息
3、数据理解
4、简单关系图
三、特征选择
四、构建模型
五、总结
其他
三、数据清洗
1、数据预处理
2、特征选择
一、提出问题
预测哪些人在泰坦尼克号上更容易存活?
二、理解数据
1、导入数据,导入pandas库和numpy库
cd D:DocumentsTencent Files2698968530FileRecv1-Titanic Machine Learning from Disaster
import pandas as pd #数据分析 import numpy as np #科学计算 from pandas import Series,DataFrame
导入训练集与测试集
train = pd.read_csv('D:\Documents\Tencent Files\2698968530\FileRecv\1-Titanic Machine Learning from Disaster\train.csv')
test= pd.read_csv('D:\Documents\Tencent Files\2698968530\FileRecv\1-Titanic Machine Learning from Disaster\test.csv')
2、查看数据集信息
一次性看训练集和测试集大小
print('训练集大小:',train.shape,'测试集大小:',test.shape)
训练集大小: (891, 12) 测试集大小: (418, 11)
合并数据集,方便对两个数据集同时进行清洗,后期怕麻烦还要再次分训练集和测试集我是直接拿训练集做的
full = train.append(test, ignore_index = True) print('合并后的数据集:',full.shape)
合并后的数据集: (1309, 12)
3、数据理解
查看数据信息
full.head()

full.columns

能看到这些字段
PassengerId => 乘客ID
Pclass => 乘客等级(1/2/3等舱位)
Name => 乘客姓名
Sex => 性别
Age => 年龄
SibSp => 堂兄弟/妹个数
Parch => 父母与小孩个数
Ticket => 船票信息
Fare => 票价
Cabin => 客舱
Embarked => 登船港口
查看数据集中各个字段的数量大小和类型
full.info()
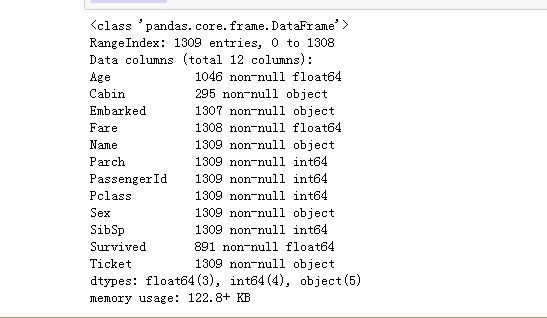
数据中总共有1309名乘客,但是有些数据属性是缺失值,年龄Age只有1046条数据,客舱Cabin只有295条数据是已知的
描述性分析
full.describe()

从mean字段来看,最后大约有0.383838的 人获救了,其他的数据看起来可能不怎么有效
4、简单关系图
可以看每个属性都存活Survived之间的关系
import matplotlib.pyplot as plt #画图 plt.rcParams['font.sans-serif']=['SimHei'] #用来正常显示中文标签 plt.rcParams['axes.unicode_minus']=False #用来正常显示负号 #有中文出现的情况,需要u'内容' #import matplotlib.pyplot as plt plt.figure(figsize=[800,500]) fig = plt.figure() fig.set(alpha=0.2) # 设定图表颜色alpha参数 plt.subplot2grid((2,3),(0,0)) # 在一张大图里分列几个小图,以及第一张图的位置给出 train.Survived.value_counts().plot(kind='bar')#把获救的和未获救的人画柱形图比较 plt.title(u"获救情况 (1为获救)") # 加上标签 plt.ylabel(u"人数") plt.subplot2grid((2,3),(0,1)) #第二张图的位置 train.Pclass.value_counts().plot(kind="bar") plt.ylabel(u"人数") plt.title(u"乘客等级分布") plt.subplot2grid((2,3),(0,2)) plt.scatter(train.Survived, train.Age) plt.ylabel(u"年龄") # 设置y轴 plt.grid(b=True, which='major', axis='y') # 格式化图形的网格线样式 plt.title(u"按年龄看获救分布 (1为获救)") plt.subplot2grid((2,3),(1,0), colspan=2) train.Age[train.Pclass == 1].plot(kind='kde') # 绘制第一类乘客年龄子集的核密度估计 train.Age[train.Pclass == 2].plot(kind='kde') train.Age[train.Pclass == 3].plot(kind='kde') plt.xlabel(u"年龄")# 绘制轴标签 plt.ylabel(u"密度") plt.title(u"各等级的乘客年龄分布") plt.legend((u'头等舱', u'2等舱',u'3等舱'),loc='best') # 设定图例 plt.subplot2grid((2,3),(1,2)) train.Embarked.value_counts().plot(kind='bar') plt.title(u"各登船口岸上船人数") plt.ylabel(u"人数") plt.show() plt.subplots_adjust(wspace=50,hspace=200)
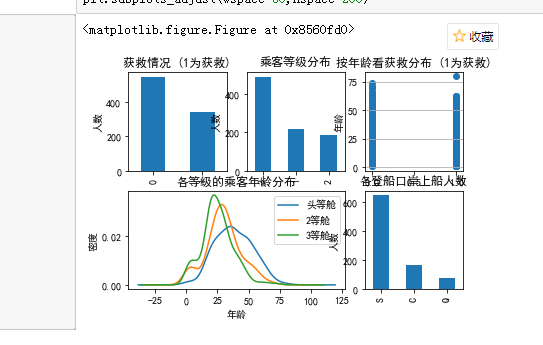
可以看到图例,得出基本的信息,此处应该再先解决设置代码的格式问题,我的图得到的图形有乱码情况,一般可以在代码最前面注释 # -*- coding: utf-8 -*-
图一可以看到未获救的人数是大于获救人数,被救的人数小于400大于300;3等舱乘客较多,遇难和获救的人年龄跨度都较广,3个不同舱年龄总体趋势相似,2/3等舱乘客20岁人最多,一等舱-40岁左右最多(可能年龄与财富成正比的原因),登船港口按照S/C/Q递减,S远多于另外的港口。
可以再单独看这些属性值的统计分布
看各乘客等级的获救情况
fig = plt.figure() fig.set(alpha=0.2) # 设定图表颜色alpha参数 Survived_0 = train.Pclass[train.Survived == 0].value_counts() Survived_1 = train.Pclass[train.Survived == 1].value_counts() df=pd.DataFrame({u'获救':Survived_1, u'未获救':Survived_0}) df.plot(kind='bar', stacked=True) plt.title(u"各乘客等级的获救情况") plt.xlabel(u"乘客等级") plt.ylabel(u"人数") plt.show()
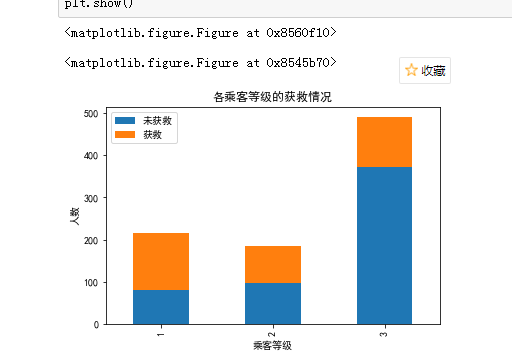
明显等级为1的乘客,获救的概率高很多,所占比例最高
再看各登录港口的获救情况
fig = plt.figure() fig.set(alpha=0.2) # 设定图表颜色alpha参数 Survived_0 = train.Embarked[train.Survived == 0].value_counts() Survived_1 = train.Embarked[train.Survived == 1].value_counts() df=pd.DataFrame({u'获救':Survived_1, u'未获救':Survived_0}) df.plot(kind='bar', stacked=True) plt.title(u"各登录港口乘客的获救情况") plt.xlabel(u"登录港口") plt.ylabel(u"人数") plt.show()
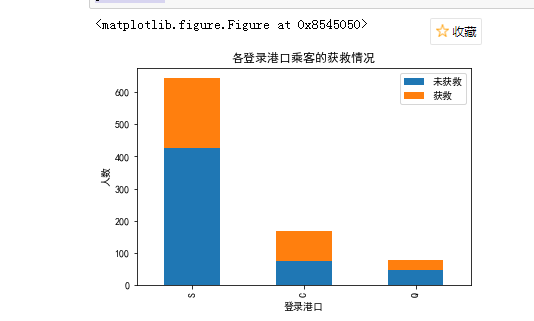
结果显示似乎每个港口的获救率都差不多
分析不同性别的获救情况,看是否满足女人和孩子先走的口号。。
fig = plt.figure() fig.set(alpha=0.2) # 设定图表颜色alpha参数 Survived_m = train.Survived[train.Sex == 'male'].value_counts() Survived_f = train.Survived[train.Sex == 'female'].value_counts() df=pd.DataFrame({u'男性':Survived_m, u'女性':Survived_f}) df.plot(kind='bar', stacked=True) plt.title(u"按性别看获救情况") plt.xlabel(u"性别") plt.ylabel(u"人数") plt.show()

lady first的口号得到证明,是女性的获救人数较多
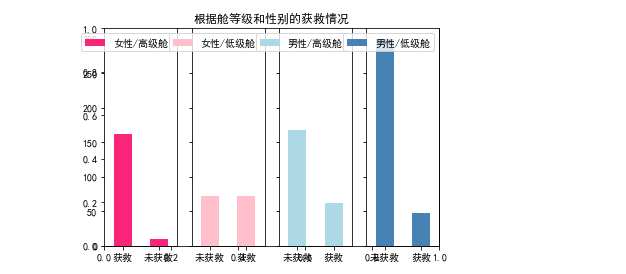
分析各种舱级别情况下各性别的获救情况
fig=plt.figure() fig.set(alpha=0.65) # 设置图像透明度,无所谓 plt.title(u"根据舱等级和性别的获救情况") ax1=fig.add_subplot(141) train.Survived[train.Sex == 'female'][train.Pclass != 3].value_counts().plot(kind='bar', label="female highclass", color='#FA2479') ax1.set_xticklabels([u"获救", u"未获救"], rotation=0) ax1.legend([u"女性/高级舱"], loc='best') ax2=fig.add_subplot(142, sharey=ax1) train.Survived[train.Sex == 'female'][train.Pclass == 3].value_counts().plot(kind='bar', label='female, low class', color='pink') ax2.set_xticklabels([u"未获救", u"获救"], rotation=0) plt.legend([u"女性/低级舱"], loc='best') ax3=fig.add_subplot(143, sharey=ax1) train.Survived[train.Sex == 'male'][train.Pclass != 3].value_counts().plot(kind='bar', label='male, high class',color='lightblue') ax3.set_xticklabels([u"未获救", u"获救"], rotation=0) plt.legend([u"男性/高级舱"], loc='best') ax4=fig.add_subplot(144, sharey=ax1) train.Survived[train.Sex == 'male'][train.Pclass == 3].value_counts().plot(kind='bar', label='male low class', color='steelblue') ax4.set_xticklabels([u"未获救", u"获救"], rotation=0) plt.legend([u"男性/低级舱"], loc='best') plt.show()
在分析有堂兄弟的的家庭对存活概率是否有影响
g = train.groupby(['SibSp','Survived']) df = pd.DataFrame(g.count()['PassengerId']) df

g =train.groupby(['Parch','Survived']) df = pd.DataFrame(g.count()['PassengerId']) df
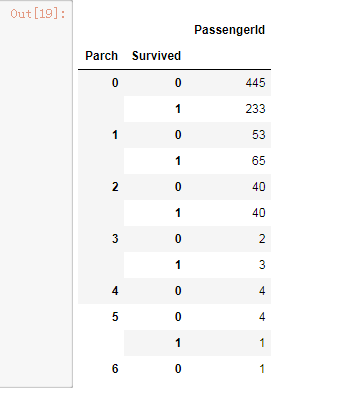
暂时不能得出结论
ticket是船票编号,应该是unique的,和最后的结果没有太大的关系,不纳入考虑的特征范畴,cabin只有204个乘客有值,我们先看看它的一个分布
train.Cabin.value_counts()
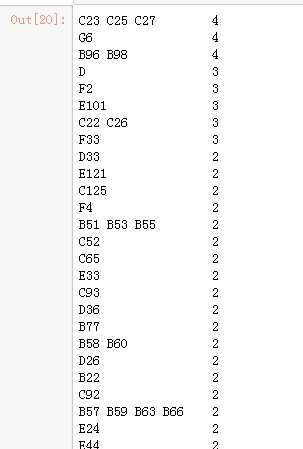

暂时也未能看出什么
三、特征选择
选择特征,使用相关系数法来进行特征的选择相关系数较高的属性
corrDf = train.corr() corrDf['Survived'].sort_values(ascending = False)

由上图我们可以看出性别、客舱等级、家庭类别、船票价格等和存活具有较高的相关性,所以我们将这些特征作为我们模型训练的输入
train_X = pd.concat( [Pclass,#客舱等级 familyDf,#家庭大小 full['Fare'],#船票价格 full['Sex']#性别 ] , axis=1 )
四、构建模型
选择逻辑回归
from sklearn.linear_model import LogisticRegression model = LogisticRegression()
。。
五、总结
到这就告一小段落,通过项目熟悉了很多数据分析的流程和一些数据处理的基本操作,但是也有很多问题未能得到解决,对于Python代码和算法的运用还不是很熟悉,很多需要查找资料才能想到具体的运用,耗时较长且效果不理想,数据分析之路且行且珍惜。
后续还增加了一些数据的预处理的方法
其他
三、数据清洗
现在解决特征值的提取问题,进行简单的数据清洗进行特征提取时,我们首先需要将数据进行分类。处理不同特征时,对于不同的数据类型处理原则也不一样。一般数值型保持不变,时间序列变成日期类型,对于分类数据:有直接类别的,用不同数值(0/1)代表不同的类别;如果分类类别大于2,则采用one-hot编码进行编码处理。没有直接类别的,也可能可以从数据中提取出有价值的部分
本案例中:1、数值型:乘客编号(Passengerld),年龄(Age)、船票价格(Fare),堂兄弟/妹个数(SibSp),表兄弟/妹个数(Parch)
2、时间序列:无
3、分类数据:a直接类别的:乘客性别(Sex)、登船港口(Embarked)、客舱等级(Pclass)
b没有直接类别的:乘客姓名(Name)、客舱号(Cabin)、船票编号(Ticket)
对于年龄和船票列可以用均值填充
train['Age']=train['Age'].fillna(train['Age'].mean()) train['Fare']=train['Fare'].fillna(train['Fare'].mean())
对于登船港口Embarked用众数港口“S”替代
对于船舱列别Cabin缺失较多,用“U”替代
train['Embarked']=train['Embarked'].fillna('S') train['Cabin']=train['Cabin'].fillna('U')
性别只有两类,所以不需要进行one—hot编码,直接用数值来对应编码,1—male,0—female
sex_mapDict = {'male':1, 'female':0}
train['Sex'] = train['Sex'].map(sex_mapDict)
train.head()

登舱港口有3个类别,所以需要进行one—hot编码
EmbarkedDf = pd.DataFrame() EmbarkedDf = pd.get_dummies(train['Embarked'], prefix = 'Embarked') # 第一个参数是需要编码的列,第二个参数是编码后列的前缀 EmbarkedDf.head()
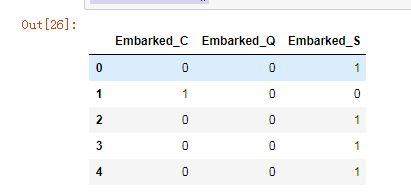
将该DataFrame合并入full表中,并将full表中的'Embarked'列删除。
train = pd.concat([train, EmbarkedDf], axis=1) train.drop('Embarked', axis = 1, inplace = True)
客舱等级分为三级,其中1表示1等舱,2表示2等舱,3表示3等舱。所以我们依然对其进行one-hot编码。
pclassDf = pd.DataFrame() pclassDf = pd.get_dummies(train['Pclass'], prefix = 'Pclass') pclassDf.head()
将上面的DataFrame与full合并,并删除'Pclass'列
train= pd.concat([train, pclassDf], axis = 1) train.drop('Pclass', axis = 1, inplace = True)