相信很多同学都会刷每期的表白墙,并期待从表白墙上找到自己的名字。那么作为信息学院的学生,有没有办法能自动获取到表白墙呢?
Selenium包可以用于自动控制网页,是一种很好的爬虫工具。
1. 首先我们布置环境
# coding: utf-8 import sys from selenium import webdriver from selenium.common.exceptions import NoSuchElementException from selenium.webdriver.chrome.options import Options import selenium import json import time import requests
2. 我们使用chrome浏览器实现自动操作,首先需要下载针对chrome的webdriver驱动chromedriver,然后对浏览器进行设置。
chrome_options = webdriver.ChromeOptions() prefs = {"profile.managed_default_content_settings.images":2} #设置不加载图片,可以加快网页加载速度 chrome_options.add_experimental_option("prefs",prefs) driver = webdriver.Chrome("./chromedriver", chrome_options=chrome_options) #chromedriver的路径 # driver.set_page_load_timeout(10) # driver.set_script_timeout(15) driver.set_window_size(1366, 768) #设置浏览器打开的分辨率
3. 然后我们分析表白墙的网页
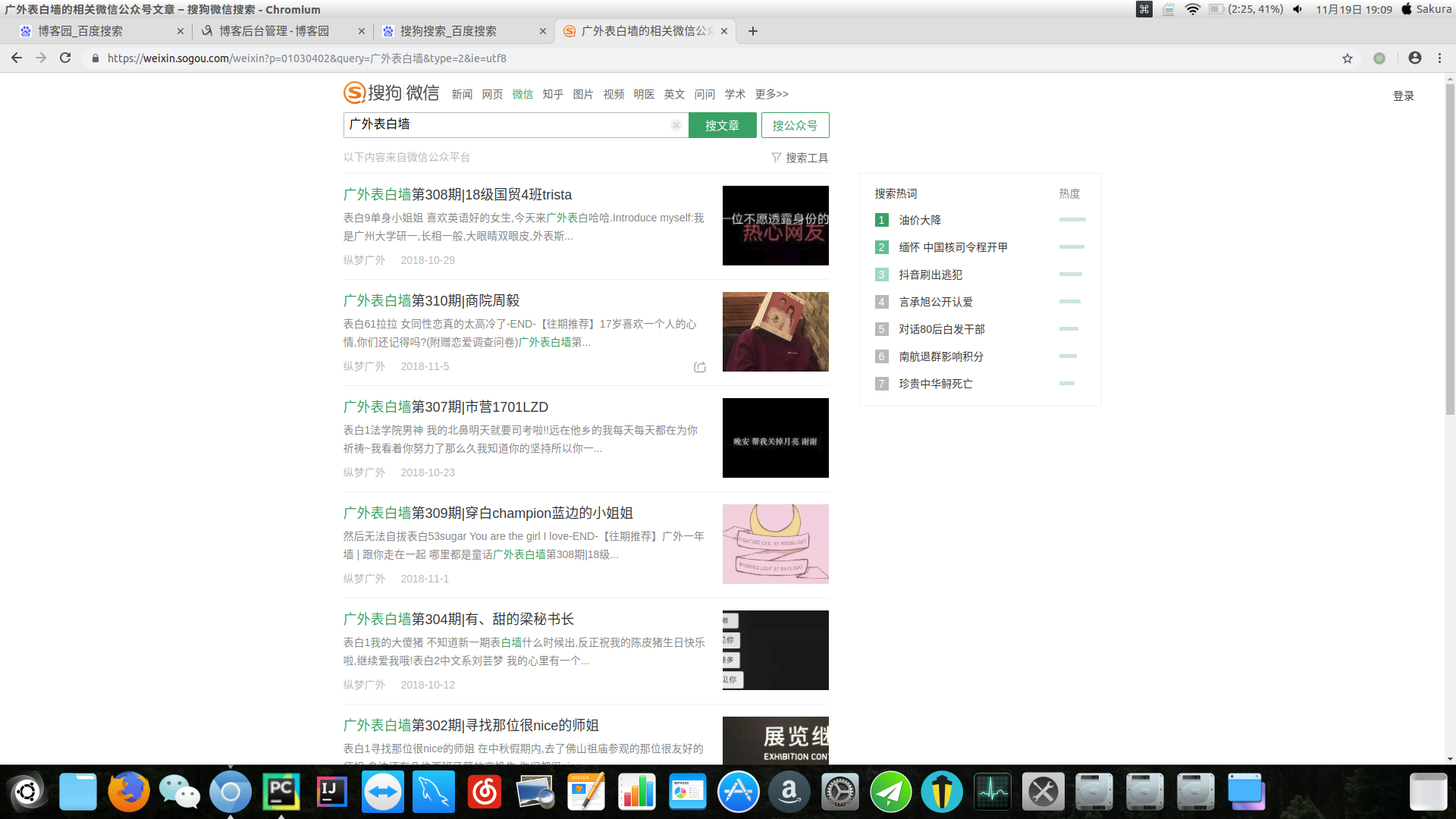
然后我们发现网页url为 “https://weixin.sogou.com/weixin?query=%E5%B9%BF%E5%A4%96%E8%A1%A8%E7%99%BD%E5%A2%99&type=2&page=2” , 因此翻页比较简单,只需要更换page后面的数字即可(用click点击下方的翻页按钮也可以)。
那我们怎么点进去每一篇表白墙,获取里面的内容呢?思路就是:在外面的网页列表进行翻页,并获取每一遍表白墙的url,然后将url写入列表,传给下一个函数,然后下一个函数一个个打开这些网页,然后再获取里面的内容。
我们点击f12
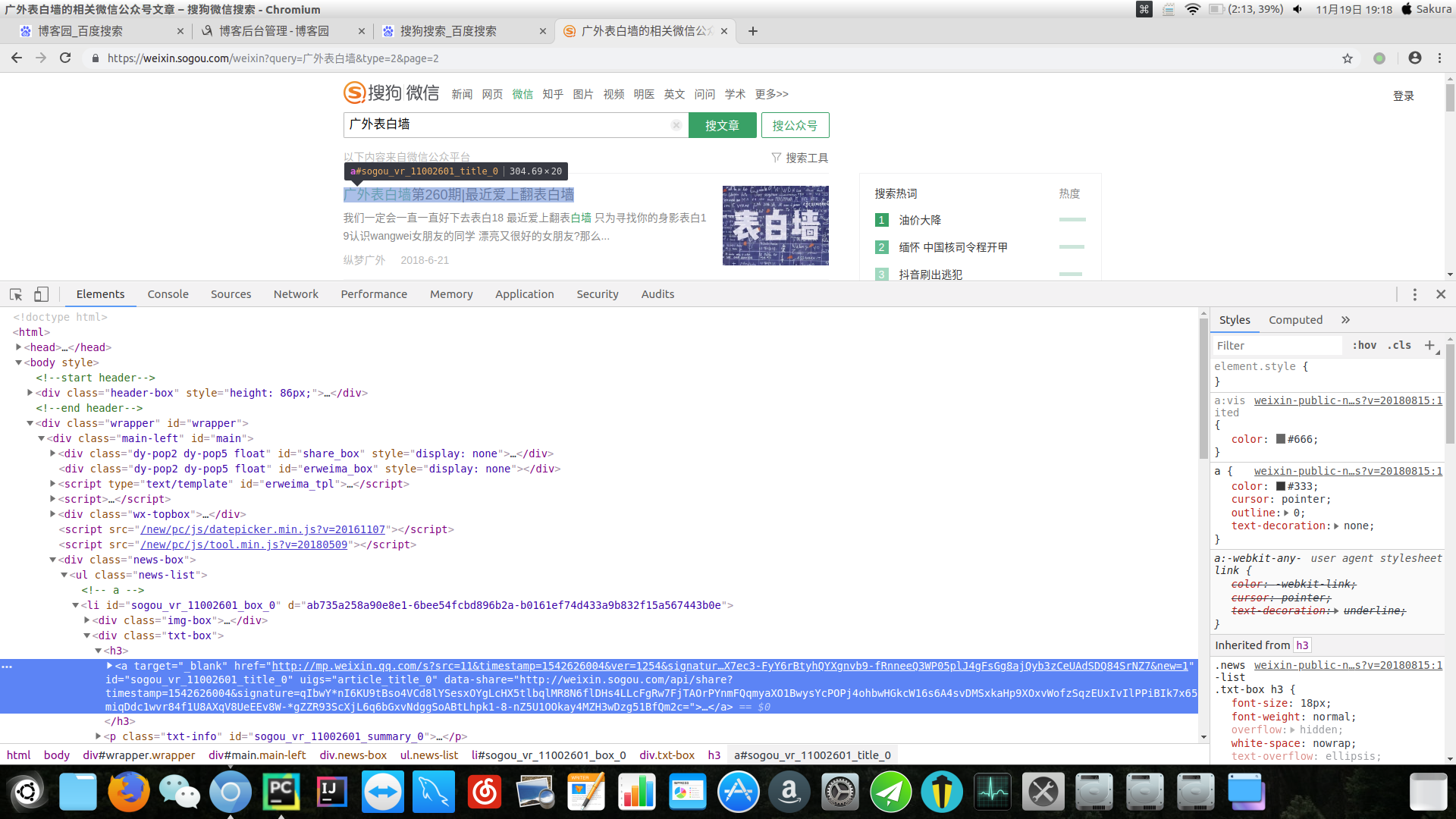
我们使用xpath确定表白墙标题的url。xpath是一种基于html的定位方式,把html路径确定好就可以定位到具体的标签。然后将url写入列表。
def release(url, all_urls): driver.get(url) content_div = driver.find_elements_by_xpath(u"//ul[@class='news-list']//h3/a") hrefs = [e.get_attribute("href") for e in content_div] all_urls.extend(hrefs) time.sleep(3)
把获取到的url列表保存到json文件。
def save_state(all_urls, crawled_urls): with open("../data/state.json", "w+") as f: json.dump({ "all": all_urls, "crawled": crawled_urls, },f)
读取url列表。
def load_state(): with open("../data/state.json", "r") as f: d = json.load(f) all_urls = d["all"] crawled_urls = d["crawled"] return all_urls, crawled_urls
其中的意思是,将已爬取和未爬取的url分为两个列表,分别进行保存。
然后我们对每一篇表白墙的内容进行分析。
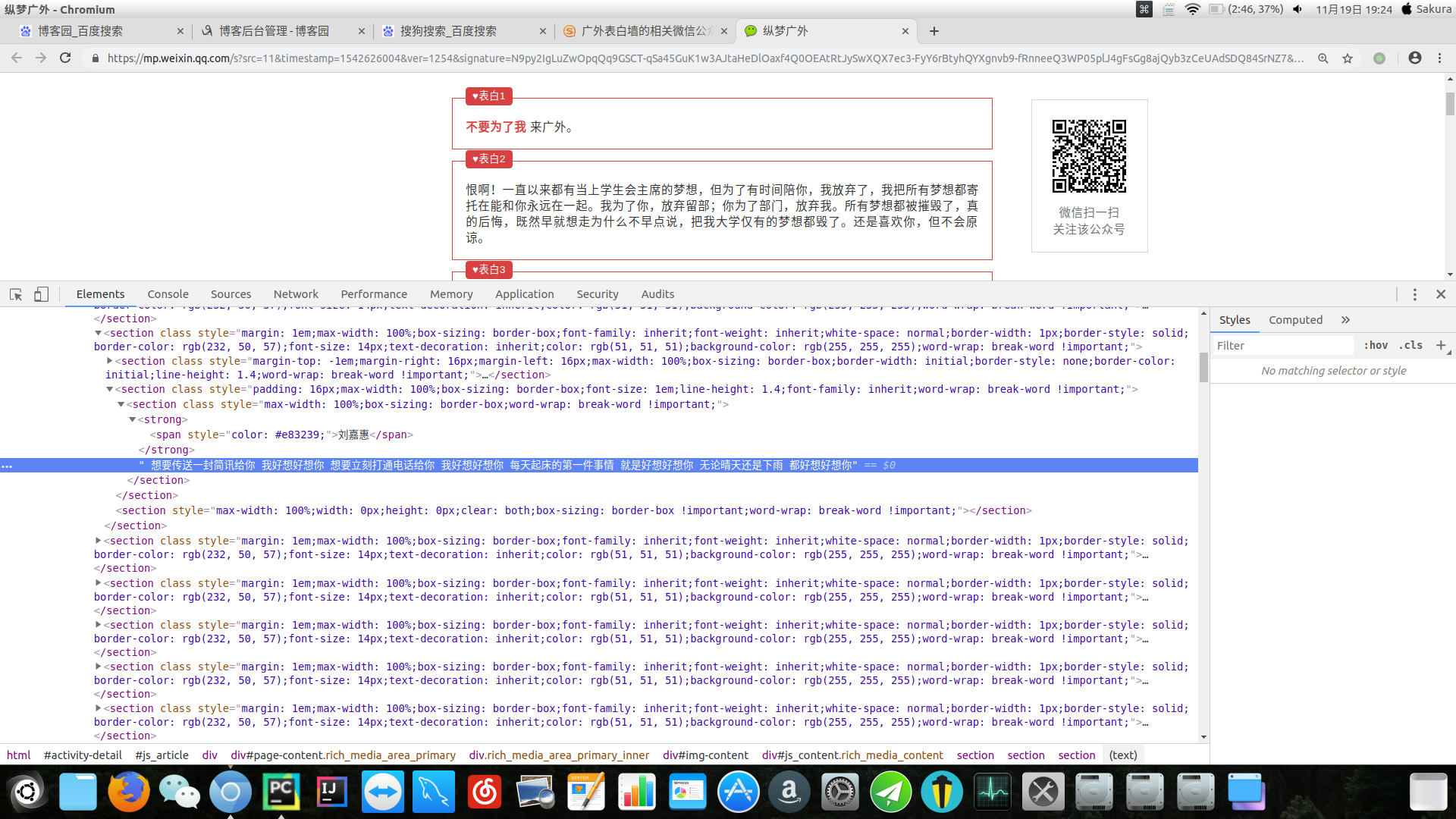
感觉表白墙的内容还是比较简单的,只需要获得section标签下的text内容即可。
def parse(url,all_urls): driver.get(url) data = driver.find_element_by_xpath(u"//div[@id='js_content']").text print(data) return data
我们将爬下来的表白墙保存。
def save2file(data, news_id): with open("../data/"+str(news_id)+".txt","w+") as f: f.write(data) f.close()
最后是主函数
def main(): all_urls = [] crawled_urls = [] for i in range(10): url = "https://weixin.sogou.com/weixin?query=%E5%B9%BF%E5%A4%96%E8%A1%A8%E7%99%BD%E5%A2%99&type=2&page=" + str(i) release(url, all_urls) save_state(all_urls, crawled_urls) all_urls,crawled_urls = load_state() n = 1 while len(all_urls) > 0: url = all_urls.pop(0) if url in crawled_urls: continue print("正在爬取:",url,) data = parse(url,all_urls) save2file(data, n) crawled_urls.append(url) save_state(all_urls, crawled_urls) print("已保存。") n += 1 # except selenium.common.exceptions.NoSuchWindowException as ex2: # print("爬虫终止") # pass # except Exception as ex1: # all_urls.append(url) # save_state(all_urls, crawled_urls) # print("出错啦!!!!!!",ex1) # pass main()
所有代码:
# coding: utf-8 import sys from selenium import webdriver from selenium.common.exceptions import NoSuchElementException from selenium.webdriver.chrome.options import Options import selenium import json import time import requests chrome_options = webdriver.ChromeOptions() prefs = {"profile.managed_default_content_settings.images":2} #设置不加载图片,可以加快网页加载速度 chrome_options.add_experimental_option("prefs",prefs) driver = webdriver.Chrome("./chromedriver", chrome_options=chrome_options) #chromedriver的路径 # driver.set_page_load_timeout(10) # driver.set_script_timeout(15) driver.set_window_size(1366, 768) #设置浏览器打开的分辨率 # global driver # chrome_options = Options() # chrome_options.add_argument('--headless') # chrome_options.add_argument('--disable-gpu') # # driver = webdriver.Chrome(chrome_options=chrome_options) # def release(url, all_urls): driver.get(url) content_div = driver.find_elements_by_xpath(u"//ul[@class='news-list']//h3/a") hrefs = [e.get_attribute("href") for e in content_div] all_urls.extend(hrefs) time.sleep(3) def parse(url,all_urls): driver.get(url) data = driver.find_element_by_xpath(u"//div[@id='js_content']").text print(data) return data def save2file(data, news_id): with open("../data/"+str(news_id)+".txt","w+") as f: f.write(data) f.close() def save_state(all_urls, crawled_urls): with open("../data/state.json", "w+") as f: json.dump({ "all": all_urls, "crawled": crawled_urls, },f) def load_state(): with open("../data/state.json", "r") as f: d = json.load(f) all_urls = d["all"] crawled_urls = d["crawled"] return all_urls, crawled_urls def main(): all_urls = [] crawled_urls = [] for i in range(10): url = "https://weixin.sogou.com/weixin?query=%E5%B9%BF%E5%A4%96%E8%A1%A8%E7%99%BD%E5%A2%99&type=2&page=" + str(i) release(url, all_urls) save_state(all_urls, crawled_urls) all_urls,crawled_urls = load_state() n = 1 while len(all_urls) > 0: url = all_urls.pop(0) if url in crawled_urls: continue print("正在爬取:",url,) data = parse(url,all_urls) save2file(data, n) crawled_urls.append(url) save_state(all_urls, crawled_urls) print("已保存。") n += 1 # except selenium.common.exceptions.NoSuchWindowException as ex2: # print("爬虫终止") # pass # except Exception as ex1: # all_urls.append(url) # save_state(all_urls, crawled_urls) # print("出错啦!!!!!!",ex1) # pass main()
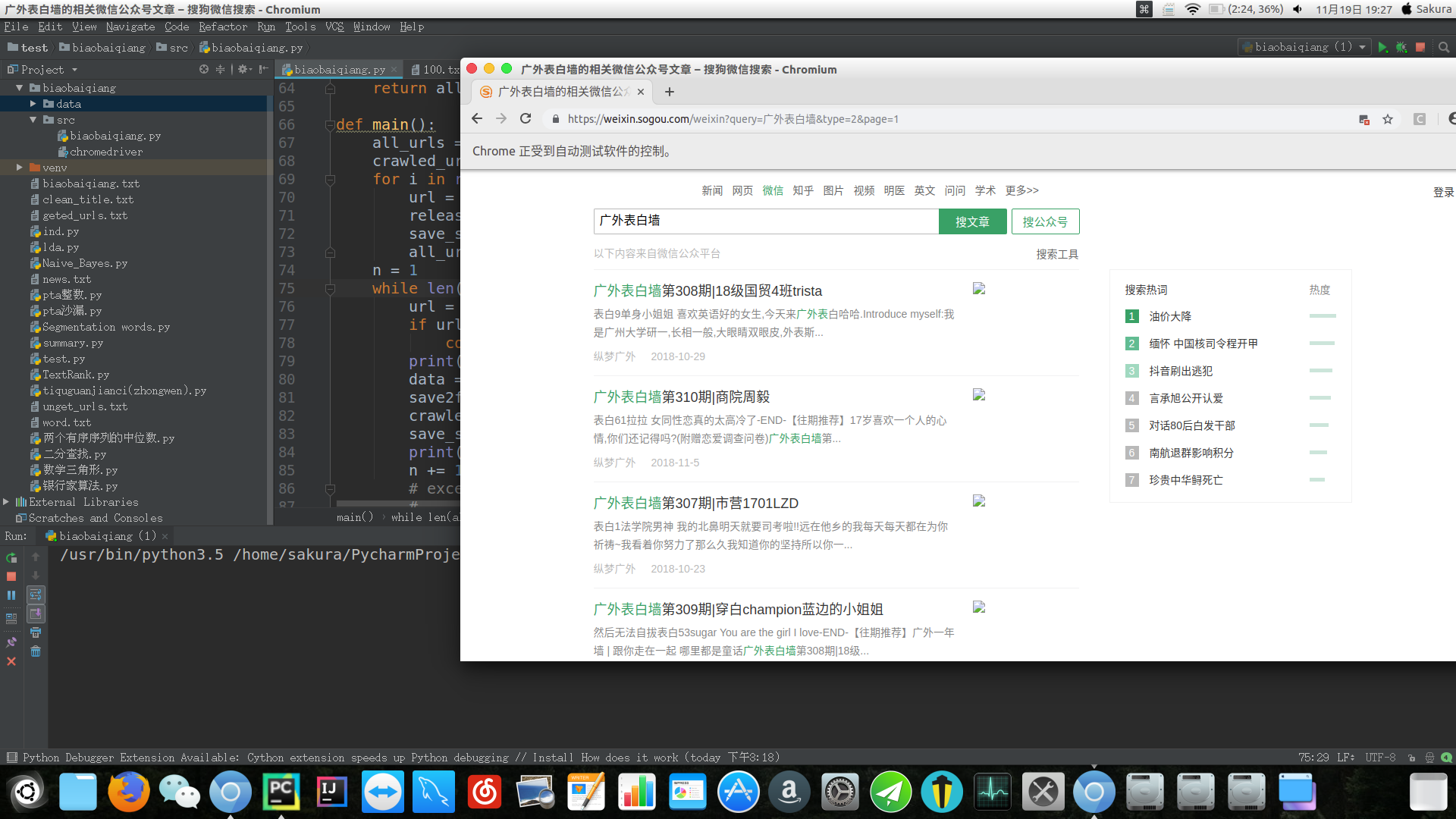
爬取时的效果图:
爬下来的表白墙:
有没有学到呢?以后就可以看有没有人偷偷给自己写表白墙啦!