锲子:
这个匈牙利算法在网上烂大街,什么样的都有,详解匈牙利算法呀,找妹子算法呀等等等等,而且特别简单,但是还是来讲讲比较好。
正文:
匈牙利算法是与最大流匹配很像的算法,核心思路就是找增广路(augment path)
匈牙利基本模式就是:把增广路径加入到最大匹配中去
可见和最大流算法是一样的。但是这里的增广路径就有它一定的特殊性,下面我们来分析一下。
(注:匈牙利算法虽然根本上是最大流算法,但是它不需要建网络模型,所以图中不再需要源点和汇点,仅仅是一个二分图。每条边是没有方向的。)
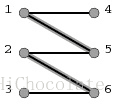
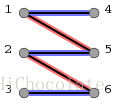
图1是二分图中的一个匹配:[1,5]和[2,6]。
图2就是在这个匹配的基础上找到的一条增广路径:3->6->2->5->1->4。我们借由它来描述一下二分图中的增广路径的性质:
(1)有奇数条边。
(2)起点在二分图的左半边,终点在右半边。
(3)路径上的点一定是一个在左半边,一个在右半边,交替出现。(其实二分图的性质就决定了这一点,因为二分图同一边的点之间没有边相连,不要忘记哦。)
(4)整条路径上没有重复的点。
(5)起点和终点都是目前还没有配对的点,而其它所有点都是已经配好对的。(如图1、图2所示,[1,5]和[2,6]在图1中是两对已经配好对的点;而起点3和终点4目前还没有与其它点配对。)
(6)路径上的所有第奇数条边都不在原匹配中,所有第偶数条边都出现在原匹配中。(如图1、图2所示,原有的匹配是[1,5]和[2,6],这两条配匹的边在图2给出的增广路径中分边是第2和第4条边。而增广路径的第1、3、5条边都没有出现在图1给出的匹配中。)
(7)最后,也是最重要的一条,把增广路径上的所有第奇数条边加入到原匹配中去,并把增广路径中的所有第偶数条边从原匹配中删除(这个操作称为增广路径的取反),则新的匹配数就比原匹配数增加了1个。(如图2所示,新的匹配就是所有蓝色的边,而所有红色的边则从原匹配中删除。则新的匹配数为3。)
图1中的两条灰色的边本身也是增广路径。找增广路径的顺序可能不同,但是最大匹配数一定都是相同的。
对于增广路径还可以用一个递归的方法来做。这个不一定最准确,但是它揭示了寻找增广路径的一般方法:
“从点A出发的增广路径”一定首先连向一个在原匹配中没有与点A配对的点B。如果点B在原匹配中没有与任何点配对,则它就是这条增广路径的终点;反之,如 果点B已与点C配对,那么这条增广路径就是从A到B,再从B到C,再加上“从点C出发的增广路径”。并且,这条从C出发的增广路径中不能与前半部分的增广 路径有重复的点。
比如图2中,我们要寻找一条从3出发的增广路径,要做以下3步:
(1)首先从3出发,它能连到的点只有6,而6在图1中已经与2配对,所以目前的增广路径就是3->6->2再加上从2出发的增广路径。
(2)从2出发,它能连到的不与前半部分路径重复的点只有5,而且5确实在原匹配中没有与2配对。所以从2连到5。但5在图1中已经与1配对,所以目前的增广路径为3->6->2->5->1再加上从1出发的增广路径。
(3)从1出发,能连到的不与自已配对并且不与前半部分路径重复的点只有4。因为4在图1中没有与任何点配对,所以它就是终点。所以最终的增广路径是3->6->2->5->1->4。
严格地说,以上过程中从2出发的增广路径(2->5->1->4)和从1出发的增广路径(1->4)并不是真正的增广路径。 因为它们不符合前面讲过的增广路径的第5条性质,它们的起点都是已经配过对的点。我们在这里称它们为“增广路径”只是为了方便说明整个搜寻的过程。而这两 条路径本身只能算是两个不为外界所知的子过程的返回结果。
要完成匈牙利算法,还需要一个重要的定理:
如果从一个点A出发,没有找到增广路径,那么无论再从别的点出发找到多少增广路径来改变现在的匹配,从A出发都永远找不到增广路径。
这个定理自己画几个图,笔玩一下,试图举两个反例,这个定理不难想通的。
证:如果你试图举个反例来说明在找到了别的增广路径并改变了现有的匹配后,从A出发就能找到增广路径。那么,在这种情况下,肯定在找到别的增广路径之前, 就能从A出发找到增广路径。这就与假设矛盾了。
这个想通了之后,就可以完成匈牙利算法了。
程序大体长下面这样:
假设我们为N个A,匹配M个B。
for i:=1 to n do
fillchar(p,sizeof(p),0);
if can(i) then inc(ans) //可以匹配就加入答案
//匹配过程(can(i)):
if p[i] then exit(false) //如果p[i]已经赶过别人了,就不能再被赶了,不然会死循环
p[i]:=true;
for j:=1 to m do //从头开始找一个B来匹配
if (b[j]=0) or (can(b[j])) then //若B中j这个位置为空,或者可以赶走别人,就占有这里
begin
b[j]=i;
exit(true); //匹配成功
end;
exit(false); //匹配失败另:
p[i]的作用
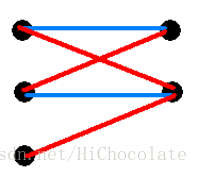
如图3(左边与右边匹配,蓝线为原来匹配的,当前到A3,它要连到B2,于是赶走A2,A2找到B1,要赶走A1,A1就会找到B2,若不标记,则A1会赶走A2,造成死循环)
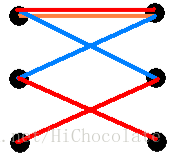
如图4(橙线为先前匹配失败,蓝线为先前匹配成功的,当前到A3,它要连到B2,于是赶走A1,A1先前不能匹配B1,但现在可以赶走A2来匹配B1,A2去匹配B3。如果不从头开始找B,A1就不能找到现在可以匹配的B1)
时间复杂度:
如果二分图的左半边一共有n个点,那么最多找n条增广路径。如果图中共有m条边,那么每找一条增广路径时最多把所有边遍历一遍,所花时间也就是m。所以总的时间大概就是O(n * m)。
Code:
var
n,m,i,j,ans:longint;
a:array[1..200,0..200]of longint;
b:array[1..200]of longint;
flag:array[1..200]of longint;
function can(x:longint):boolean;
var
ii:longint;
begin
if flag[x]=i then exit(false);
flag[x]:=i;
for ii:=1 to a[x,0] do
if (b[a[x,ii]]=0)or (can(b[a[x,ii]]))then
begin
b[a[x,ii]]:=x;
exit(true);
end;
exit(false);
end;
begin
readln(n,m);
for i:=1 to n do
begin
read(a[i,0]);
for j:=1 to a[i,0]do read(a[i,j]);
end;
for i:=1 to n do
if can(i)then inc(ans);
writeln(ans);
end.例题:
见我的blog:http://blog.csdn.net/hichocolate/article/details/77380796