对抗攻击领域综述(adversarial attack)
一、总结
一句话总结:
对抗攻击英文为adversarial attack。即对输入样本故意添加一些人无法察觉的细微的干扰,导致模型以高置信度给出一个错误的输出。
1、对抗攻击的意义?
我们不知道神经网络提取到的特征点:深度神经网络对输入图片的特征有了一个比较好的提取,但是具体提取了什么特征以及为什么提取这个特征不知道。
找到神经网络提取到的特征点:所以我们需要试图找到那个模型认为很重要的位置,然后尝试着去改变这个位置的像素值,使得DNN对输入做出一个误判。
2、对抗攻击分类?
白盒攻击,称为White-box attack,也称为open-box 对模型和训练集完全了解,这种情况比较简单,但是和实际情况不符合。
黑盒攻击,称为Black-box attack,对模型不了解,对训练集不了解或了解很少。这种攻击和实际情况比较符合,主要也是主要研究方向。
定向攻击,称为targeted attack,对于一个多分类网络,把输入分类误判到一个指定的类上
非定向攻击,称为non-target attack,只需要生成对抗样本来欺骗神经网络,可以看作是上面的一种特例。
二、对抗攻击领域综述(adversarial attack)
转自或参考:CV||对抗攻击领域综述(adversarial attack) - 知乎
https://zhuanlan.zhihu.com/p/104532285?utm_source=qq
一:对抗攻击概述
对抗攻击英文为adversarial attack。即对输入样本故意添加一些人无法察觉的细微的干扰,导致模型以高置信度给出一个错误的输出。
首先通过一些图片来对这个领域有一个直观的理解:对抗攻击就是使得DNN误判的同时,使得图片的改变尽可能少。
 从图中可以看的出来,DNN在左图中正常地把狗识别成狗,而在左图上添加一些扰动(perturbation)之后形成右图,在肉眼看来,这两张图片并没有什么区别,按正常左右两图的识别结果应该是一样的,但是DNN却在右图中不正常的把狗识别成了人、火车等等。
从图中可以看的出来,DNN在左图中正常地把狗识别成狗,而在左图上添加一些扰动(perturbation)之后形成右图,在肉眼看来,这两张图片并没有什么区别,按正常左右两图的识别结果应该是一样的,但是DNN却在右图中不正常的把狗识别成了人、火车等等。 在原图上加一个人肉分辨不出来的Perturbation之后,可以使得识别出现错误
在原图上加一个人肉分辨不出来的Perturbation之后,可以使得识别出现错误
对抗攻击从image attack起源,逐渐完善理论,然后慢慢扩大到了video attack以及在NLP、强化学习等领域中的应用。
其中的思想大致可以按下面理解:深度神经网络对输入图片的特征有了一个比较好的提取,但是具体提取了什么特征以及为什么提取这个特征不知道。所以我们需要试图找到那个模型认为很重要的位置,然后尝试着去改变这个位置的像素值,使得DNN对输入做出一个误判。
二:对抗攻击分类
- 白盒攻击,称为White-box attack,也称为open-box 对模型和训练集完全了解,这种情况比较简单,但是和实际情况不符合。
- 黑盒攻击,称为Black-box attack,对模型不了解,对训练集不了解或了解很少。这种攻击和实际情况比较符合,主要也是主要研究方向。
- 定向攻击,称为targeted attack,对于一个多分类网络,把输入分类误判到一个指定的类上
- 非定向攻击,称为non-target attack,只需要生成对抗样本来欺骗神经网络,可以看作是上面的一种特例。
三:对抗攻击发展历史与方法分类(对抗攻击寻找新的算法)
- Gradient-Based基于梯度的方法:(主要是白盒攻击的方法)
- 2014年,文章《Intriguing properties of neural networks》发布,这是对抗攻击领域的开山之作,文中介绍了一些NN的性质,首次提出了对抗样本的概念。在文章中,作者指出了深度神经网络学习的输入-输出映射在很大程度是相当不连续的,我们可以通过应用某些难以感知的扰动来使网络对图像分类错误,该扰动是通过最大化网络的预测误差来发现的。此外,这些扰动的特定性质并不是学习的随机产物:相同的扰动会导致在数据集的不同子集上进行训练的不同网络对相同输入进行错误分类
- 同时文章中也提出了BFGS:通过寻找最小的损失函数添加项,使得神经网络做出误分类,将问题转化成了凸优化。问题的数学表述如下:
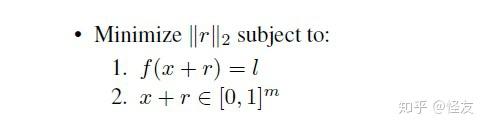 f(x)表示习得的分类映射函数,r表示改变的步长,公式表达了寻找使得f(x+r)映射到指定的类l上的最小的r
f(x)表示习得的分类映射函数,r表示改变的步长,公式表达了寻找使得f(x+r)映射到指定的类l上的最小的r
之后人们在此基础上,提出了各种改进措施:
(1)Goodfellow等人在2014年提出了提出了快速梯度符号方法(FGSM)以生成具有单个梯度步长的对抗性示例。在进行反向传播之前,该方法用于扰动模型的输入,这是对抗训练的早期形式。
(2)SM Moosavi-Dezfooli等人在2015年提出的DeepFool通过计算出最小的必要扰动,并应用到对抗样本构建的方法,使用的限制扰动规模的方法是L2范数,得到比较优的结果
(3)N Papernot等人在2015年的时候提出的JSMA,通过计算神经网络前向传播过程中的导数生成对抗样本
(4)Florian Tramèr等人在2017年通过添加称为R + FGSM的随机化步骤来增强此攻击,后来,基本迭代方法对FGSM进行了改进,采取了多个较小的FGSM步骤,最终使基于FGSM的对抗训练均无效。
(5)N Carlini,D Wagner等人在2017年提出了一个更加高效的优化问题,能够以添加更小扰动的代价得到更加高效的对抗样本。
- Transfer-based方法:(黑盒和白盒攻击之间过渡的一种方法)
基于Transfer的攻击不依赖模型信息,但需要有关训练数据的信息。
Nicolas Papernot等人在2017年的时候利用训练数据,训练出可以从中生成对抗性扰动的完全可观察的替代物模型。Liu等人2016年的时候在论文《SafetyNet: Detecting and Rejecting Adversarial Examples Robustly》证明了:如果在一组替代模型上创建对抗性示例,则在某些情况下,被攻击模型的成功率可以达到100%。
- Score-based方法:(黑盒攻击)
一些攻击更不可知,仅依赖于预测分数(例如类别机率或对数)。 从概念上讲,这些攻击使用数值估算梯度的预测。该方法的开始真正work在于2017年PY Chen等人提出的ZOO方法《ZOO: Zeroth Order Optimization Based Black-box Attacks to Deep Neural Networks without Training Substitute Models》(https://dl.acm.org/doi/abs/10.1145/3128572.3140448)。文中通过对一阶导和二阶导的近似、层次攻击等多种方式减少了训练时间,保障了训练效果
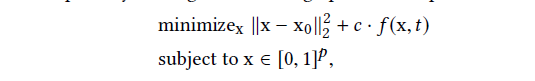 该方程在最初的优化方程基础上进行改进,x0表示原始图片,x表示修改之后的图片,t表示重定向的类别,f(x,t)表示x分类为t的损失函数(或者说是置信度),对抗攻击问题转变成使这两项之和最小的最优化问题。
该方程在最初的优化方程基础上进行改进,x0表示原始图片,x表示修改之后的图片,t表示重定向的类别,f(x,t)表示x分类为t的损失函数(或者说是置信度),对抗攻击问题转变成使这两项之和最小的最优化问题。
此后人们在从“选择下一个要进行梯度估算更改的像素进行更改”的角度入手:
(1)B. Ru, A. Cobb等人在2020年发表文章《BayesOpt Adversarial Attack》利用了贝叶斯优化来以高查询效率找到成功的对抗扰动。此外该论文还通过采用可替代的代理结构来减轻通常针对高维任务的优化挑战,充分利用了我们的统计替代模型和可用的查询数据,以通过贝叶斯模型选择来了解搜索空间的最佳降维程度。
(2)L. Meunier等人在2020年发表文章《Yet another but more efficient black-box adversarial attack: tiling and evolution strategies》利用了evolutional algorithms。通过结合两种优化方法实现了无导数优化。
(3)J. Du等人在2020年发表了文章《Query-efficient Meta Attack to Deep Neural Networks》采用了meta learning来近似估计梯度。该方法可以在不影响攻击成功率和失真的情况下,大大减少所需的查询次数。 通过训练mata attacker,并将其纳入优化过程以减少查询数量。
- Decision-based方法:(黑盒攻击)
Wieland Brendel等人在2018年提出的基于决策边界的的方法,这种方法是第三种方法的一种变化,有点像运筹学中的原始对偶方法,保证结果的情况之下,逐渐使得条件可行。通过多次迭代的方式使得条件逐渐收敛。其算法描述如下:
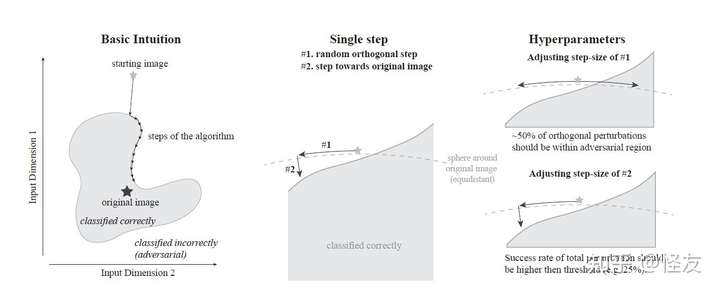 左图:本质上,边界攻击沿着对抗图像和非对抗图像之间的边界执行拒绝采样。中间:在每个步骤中,我们通过(#1)从iid高斯绘制并投影在球体上,并通过(#2)向目标图像稍作移动,来绘制新的随机方向。右图:根据边界的局部几何动态调整两个步长(正交和朝向原始输入)。
左图:本质上,边界攻击沿着对抗图像和非对抗图像之间的边界执行拒绝采样。中间:在每个步骤中,我们通过(#1)从iid高斯绘制并投影在球体上,并通过(#2)向目标图像稍作移动,来绘制新的随机方向。右图:根据边界的局部几何动态调整两个步长(正交和朝向原始输入)。
Z Yao 等人在2019年的CVPR上发表的《Trust region basedadversarial attackon neural networks》,这种方法在非凸优化问题上有着非常好的效果
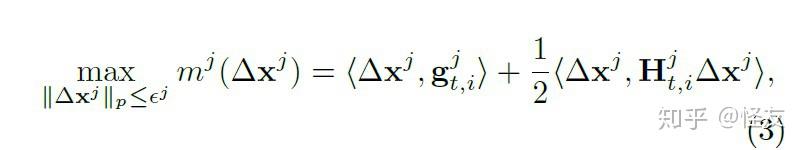
是第j次的trust region的半径,
是函数
的核函数的近似。通过迭代的方法选择可信半径
来查找该区域内的对抗性扰动,以使错误类别的概率变为最大
- Attack on Attntion:(黑盒攻击)
为了在不同的DNN模型中都能够有比较好的效果,需要从这些DNN都具有共同特性上下手。AoA方法是对score-based的方法的改进,与score-based的方法不同的是,AoA想要改变attention heat map.将注意力从原始类别(非目标类别)转移到接近目标类别(目标)。
S Chen 等人在2020年发表的《Universal Adversarial Attack on Attention and the Resulting Dataset DAmageNet》是该方面的开山之作,同时设计了一个AoA数据集DAmageNet。
四:对抗攻击寻找新的应用场景
对抗样本攻击首先在image attack中被提出,并得到充分发展。其中主要是在分类与识别场景的神经网络的攻击上。
同时,对抗样本攻击也在自编码器和生成模型,在循环神经网络,深度强化学习,在语义切割和物体检测等方面也有应用。
- 强化学习RL:Lin等人在《Tactics of adversarial attack on deep reinforcement learning agents》提出了两种不同的针对深度强化学习训练的代理的对抗性攻击。在第一种攻击中,被称为策略定时攻击,对手通过在一段中的一小部分时间步骤中攻击它来最小化对代理的奖励值。提出了一种方法来确定什么时候应该制作和应用对抗样本,从而使攻击不被发现。在第二种攻击中,被称为迷人攻击,对手通过集成生成模型和规划算法将代理引诱到指定的目标状态。生成模型用于预测代理的未来状态,而规划算法生成用于引诱它的操作。这些攻击成功地测试了由最先进的深度强化学习算法训练的代理。
- 循环神经网络:2016年Papernot等人在《Crafting adversarial input sequences for recurrent neural networks》提出
- 语义切割和物体检测:2018年Carlini N等人在《Audio adversarial examples: Targeted attacks on speech-to-text》提出
五:对抗训练与对抗防御方法最新总结
- V Zantedeschi 等人在2017年发表文章《Efficient defenses against adversarial attacks》提出了一种双重defence方法,能够在对原来模型标准训练代价影响较小的情况下完成配置。防御从两个方面入手,其一是通过改变ReLU激活函数为受限的ReLU函数以此来增强网络的稳定性。另一方面是通过高斯数据增强,增强模型的泛化能力,让模型能将原始数据和经过扰动后的数据分类相同。
- A Athalye等人在2018年的时候发表文章《Obfuscated gradients give a false sense of security: Circumventing defenses to adversarial examples》在文章中提到 发现了一种「混淆梯度」(obfuscated gradient)现象,它给对抗样本的防御带来虚假的安全感。在案例研究中,试验了 ICLR 2018 接收的 8 篇论文,发现混淆梯度是一种常见现象,其中有 7 篇论文依赖于混淆梯度,并被的这一新型攻击技术成功攻克。
- A Shafahi等人在2019年发表文章《Universal adversarial training》。作者通过使用交替或同时随机梯度方法优化最小-最大问题来训练鲁棒模型来防御universal adversarial attack。 同时证明了:使用某些使用“归一化”梯度的通用噪声更新规则,这是可能的。
- P Maini等人在2019年的时候发表文章《Adversarial Robustness Against the Union of Multiple Perturbation Models》。在文中,作者证明了在针对多个Perturbation模型的联合进行训练时,对抗训练可以非常有效。 同时作者还比较了对抗训练的两个简单概括和改进的对抗训练程序,即多重最速下降,该方法将不同的扰动模型直接合并到最速下降的方向。
- R Zhai等人在2020年发表文章《MACER: Attack-free and Scalable Robust Training via Maximizing Certified Radius》这是一种无攻击且可扩展的鲁棒的训练方法,它可以直接最大化平滑分类器的认证半径。同时文章证明了对抗性训练不是鲁棒的训练的必要条件,基于认证的防御是未来研究的有希望的方向!
六:对抗攻击的用处
- DNN在很多方面已经展示出比人类要好的水平,比如image classification,machine translation等等。
- DNN的可攻击性,导致了DNN在一些重要领域之内无法大规模部署,极大的限制了DNN的发展。
- 对对抗攻击有了比较深入的理解之后,才能对对抗防御有比较深入的理解。(We believe:只有更好的攻击才会有更好的防御,而只有attack的算法更加先进,defence的算法才会随着更加先进,而且这种先进是和attack算法是否公开没有必然关联的。)
具体的用处:比如在图片和视频的分类,在面部识别上,等等,举一个比较小众,但是确实存在的例子->
各种短视频盛行的当下,网络上一方面各种短视频盛行(其中大量是色情视频),另一方面是版权问题,很多人把一些火爆的视频下载下来,稍微修改就上传上去,从而赚取流量。这两个问题引起了公众的极大担忧,也对内容生产平台的检测和过滤带来了很大的技术挑战,而人工审核成本太高且低效,了解视频的对抗攻击有助于防御从而更好的检测与过滤。
七:研究热点
- 寻找新的应用场景,从图片的研究开始,逐渐往NLP和和视频等的相关场景。
- 寻找新的用来攻击的网络,从分类的网络开始,到RNN,再到强化学习中的神经网络
- 构建效率更好的对抗攻击网络,从原始的最优化的方法开始,到利用meta learning去优化对抗网络的查询,可以看一下有什么新的技术可以应用到凸优化之中。
- 对抗防御和对抗训练的策略,每一种对抗攻击方法都可以提出一种对抗防御的方法。
- 将GAN与对抗攻击研究相结合。它可以同时构建效果更加好的对抗样本和实现让模型更加鲁棒的defence策略。
- 研究一种评估攻击方法或者防御策略的有效性的评估方法。
八:直观理解—攻击一个神经网络有多难?
实际上只需要改变一个像素即可! 修改一个像素值,就能够让神经网络识别图像出错:
可以参考文章: