BM算法介绍
各种文本编辑器的 "查找" 功能(Ctrl+F),大多采用 Boyer-Moore 算法。

Boyer-Moore 算法不仅效率高,而且构思巧妙,容易理解。1977 年,德克萨斯大学的 Robert S. Boyer 教授和 J Strother Moore 教授发明了一种新的字符串匹配算法:Boyer-Moore 算法,简称 BM 算法。
该算法 从模式串的尾部开始匹配,且拥有在最坏情况下 O(N) 的时间复杂度。有数据表明,在实践中,比 KMP 算法的实际效能高,可以快大概 3-5 倍。
BM 算法中有两个核心规则:坏字符规则与好后缀规则
定义
BM算法 的一个特点是当不匹配的时候 一次性可以跳过不止一个字符 。即它不需要对被搜索的字符串中的字符进行逐一比较,而会跳过其中某些部分。通常搜索关键字越长,算法速度越快。它的效率来自于这样的事实:对于每一次失败的匹配尝试,算法都能够使用这些信息来排除尽可能多的无法匹配的位置。
它充分利用待搜索字符串的 一些特征 ,加快了搜索的步骤。
那它是利用了什么特性去 排除尽可能多的无法匹配的位置 呢?
它是基于以下两个规则让模式串每次向右移动 尽可能大 的距离。
- 坏字符规则(bad-character shift):当文本串中的某个字符跟模式串的某个字符不匹配时,我们称文本串中的这个失配字符为坏字符,此时模式串需要向右移动,移动的位数 = 坏字符在模式串中的位置 – 坏字符在模式串中最右出现的位置。此外,如果”坏字符”不包含在模式串之中,则最右出现位置为 -1。坏字符针对的是文本串。
- 好后缀规则(good-suffix shift):当字符失配时,后移位数 = 好后缀在模式串中的位置 – 好后缀在模式串上一次出现的位置,且如果好后缀在模式串中没有再次出现,则为 -1。好后缀针对的是模式串。

坏字符规则
坏字符出现的时候有两种情况进行讨论。
1、模式串中没有出现了文本串中的那个坏字符,将模式串直接整体对齐到这个字符的后方,继续比较。


2、模式串中有对应的坏字符时,让模式串中 最靠右 的对应字符与坏字符相对。
这句话有一个关键词是 最靠右。
思考一下为什么是 最靠右?
看图!




实现代码
//计算坏字符数组bmBc[]
void PreBmBc(char *pattern, int m, int bmBc[]) {
int i;
for (i = 0; i < 256; ++i)
{
bmBc[i] = m;
}
for (i = 0; i < m - 1; ++i)
{
bmBc[pattern[i]] = m - i - 1;
}
}
好后缀规则
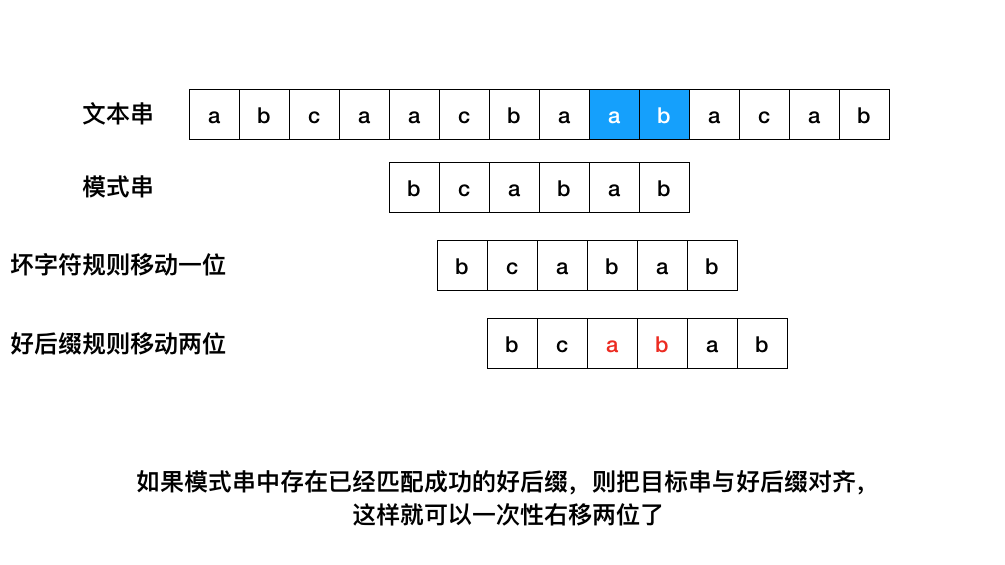
Case 1、如果模式串中存在已经匹配成功的好后缀,则把目标串与好后缀对齐,然后从模式串的最尾元素开始往前匹配。

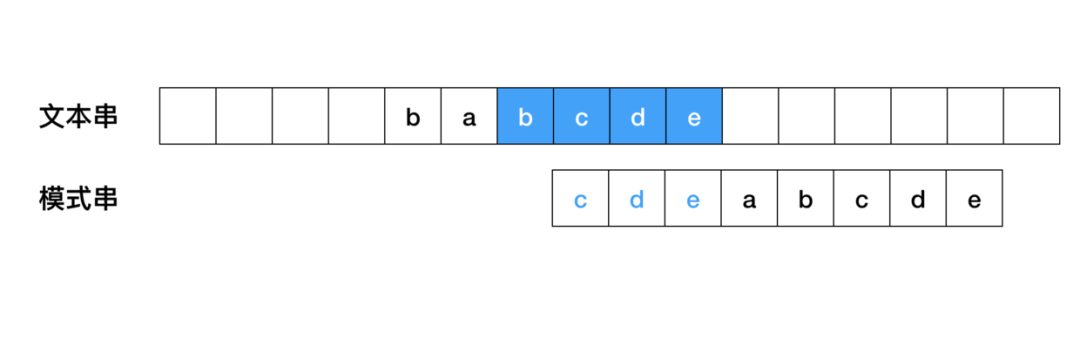
Case 2、如果无法找到匹配好的后缀,找一个匹配的最长的前缀,让目标串与最长的前缀对齐(如果这个前缀存在的话)。模式串[m-s,m] = 模式串[0,s] 。

Case 3、如果完全不存在和好后缀匹配的子串,则右移整个模式串。
//计算好后缀数组
void PreBmGs(char *pattern, int m, int bmGs[])
{
int i, j;
int suff[SIZE]; //SIZE 256
// 计算后缀数组
suffix(pattern, m, suff);
// 先全部赋值为m,包含Case3
for(i = 0; i < m; i++)
{
bmGs[i] = m;
}
// Case2
j = 0;
for(i = m - 1; i >= 0; i--)
{
if(suff[i] == i + 1)
{
for(; j < m - 1 - i; j++)
{
if(bmGs[j] == m)
bmGs[j] = m - 1 - i;
}
}
}
// Case1
for(i = 0; i <= m - 2; i++)
{
bmGs[m - 1 - suff[i]] = m - 1 - i;
}
}
//在计算bmGc数组时,为提高效率,先计算辅助数组suff[]表示好后缀的长度。
void suffix(char *pattern, int m, int suff[])
{
int i, j;
int k;
suff[m - 1] = m;
for(i = m - 2; i >= 0; i--)
{
j = i;
while(j >= 0 && pattern[j] == pattern[m - 1 - i + j]) j--;
suff[i] = i - j;
}
}
其实还可以再进行优化
void suffix(char *pattern, int m, int suff[]) {
int f, g, i;
suff[m - 1] = m;
g = m - 1;
for (i = m - 2; i >= 0; --i) {
if (i > g && suff[i + m - 1 - f] < i - g)
suff[i] = suff[i + m - 1 - f];
else {
if (i < g)
g = i;
f = i;
while (g >= 0 && pattern[g] == pattern[g + m - 1 - f])
--g;
suff[i] = f - g;
}
}
}
完整BM代码
#include<iostream>
using namespace std;
#define MAX_CHAR 256
#define SIZE 256
#define MAX(x,y) (x)>(y)?(x):(y)
void BoyerMoore(char *pattern, int m, char *text, int n);
int main() {
char text[256], pattern[256];
while (1)
{
scanf("%s%s", text, pattern);
if (text == 0 || pattern == 0) break;
BoyerMoore(pattern, strlen(pattern), text, strlen(text));
printf("
");
}
return 0;
}
//计算坏字符数组bmBc[]
void PreBmBc(char *pattern, int m, int bmBc[]) {
int i;
for (i = 0; i < 256; ++i)
{
bmBc[i] = m;
}
for (i = 0; i < m - 1; ++i)
{
bmBc[pattern[i]] = m - i - 1;
}
}
/*
suff数组的定义:m是pattern的长度
a. suffix[m-1] = m;
b. suffix[i] = k
for [ pattern[i-k+1] ...,pattern[i]] == [pattern[m-1-k+1],pattern[m-1]]
*/
void suffix_old(char *pattern, int m, int suff[])
{
int i, j;
suff[m - 1] = m;
for (i = m - 2; i >= 0; i--)
{
j = i;
while (j >= 0 && pattern[j] == pattern[m - 1 - i + j]) j--;
suff[i] = i - j;
}
}
void suffix(char *pattern, int m, int suff[]) {
int f, g, i;
suff[m - 1] = m;
g = m - 1;
for (i = m - 2; i >= 0; --i) {
if (i > g && suff[i + m - 1 - f] < i - g)
suff[i] = suff[i + m - 1 - f];
else {
if (i < g)
g = i;
f = i;
while (g >= 0 && pattern[g] == pattern[g + m - 1 - f])
--g;
suff[i] = f - g;
}
}
}
//计算好后缀数组bmGs[]
void PreBmGs(char *pattern, int m, int bmGs[]) {
int i, j;
int suff[SIZE];
//计算后缀数组
suffix(pattern, m, suff);
// 先全部赋值为m,包含Case3
for (i = 0; i < m; i++)
{
bmGs[i] = m;
}
// Case2
j = 0;
for (i = m - 1; i >= 0; i--)
{
if (suff[i] == i + 1)
{
for (; j < m - 1 - i; j++)
{
if (bmGs[j] == m)
bmGs[j] = m - 1 - i;
}
}
}
// Case1
for (i = 0; i <= m - 2; i++)
{
bmGs[m - 1 - suff[i]] = m - 1 - i;
}
}
void print(int *array, int n, char *arrayName)
{
int i;
printf("%s: ", arrayName);
for (i = 0; i < n; i++)
{
printf("%d ", array[i]);
}
printf("
");
}
void BoyerMoore(char *pattern, int m, char *text, int n)
{
int i, j, bmBc[MAX_CHAR], bmGs[SIZE];
// Preprocessing
PreBmBc(pattern, m, bmBc);
PreBmGs(pattern, m, bmGs);
// Searching
j = 0;
while (j <= n - m)
{
for (i = m - 1; i >= 0 && pattern[i] == text[i + j]; i--);
if (i < 0)
{
printf("Find it, the position is %d
", j+1);
j += bmGs[0];
return;
}
else
{
j += MAX(bmBc[text[i + j]] - m + 1 + i, bmGs[i]);
}
}
printf("No find.
");
}
Ps:图片来自网络,侵权删除