概念上:
C++是一门计算机编程语言,而G++则是C++的编译器。
GCC和G++都是GUN的编译器,cc是Unix系统的C Compiler,而gcc则是GNU Compiler Collection,GNU编译器套装。gcc原名为Gun C语言编译器,因为它原本只能处理C语言,但gcc很快地扩展,包含很多编译器(C、C++、Objective-C、Ada、Fortran、Java)。
提交上的区别:
在OJ提交的语言选项中,G++和C++都代表一种编译的方式。
选择C++意味着你将使用C++最标准的编译方式,也就是ANSI C++编译。
选择G++则意味这你使用GNU项目中适用人群最多的编译器(其实也就是我们熟悉的Code::Blocks 自带的编译器)。
类似的还有选择C和GCC,前者是标准的C编译器,后者则是用GCC来编译。
编译时的差异:
编译器优化不同:
举个栗子: ①: a++ ②: ++a
从标准C的角度看:①式是先调用,再自增。在调用过程中,会申请一个新的数据地址,用于存放临时的变量a’,然后在把a’加1,之后在把a’赋值给a。但是②式不会这么麻烦,因为它是先自增,后调用,也就省去了申请新地址的功夫。所以理论上,二者的时间消耗是有差异的。
而如果是使用GCC来编译,那么这两者基本上没有差异。
个人推荐还是使用++i,这样使用不同编译器(非GCC)的时候也能加快效率
精度缺省:
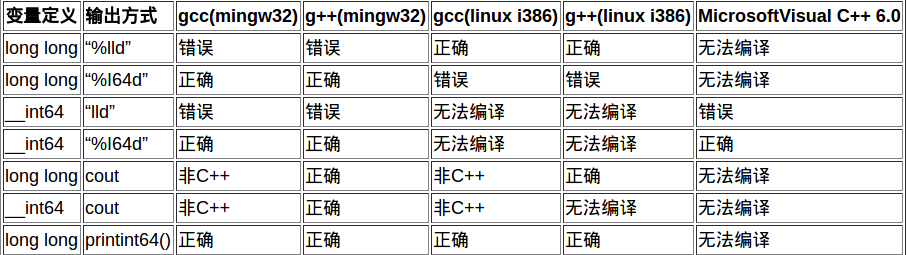
①long long类型,作为一个在C/C++11才被确认为基本数据类型的一个数据类型,在不同的环境下,他的类型标识符是不同的。也就是我们津津乐道的%lld 和 %I64d了。
②double类型也是一个有趣的类型。double类型其实准确地说是双精度型,他的内存长度一般是比float类型(单精度型)的多了一倍,有的时候很早的标准里是把double称为long float的。所以说就有了为什么float类型用%f,double用%lf。
在用scanf读数据时,为了与float区分,使用%lf。
在用printf写数据时,由于实质上,double和float是同一个类型,只不过内存占用有差异而已,他们的标识符都是%f,注意,这个和标准C不同,这里的都是%f。
列表:
double num G++提交 C++提交 最安全的方法 输入 scanf(“%lf”, &num); scanf(“%lf”, &num); cin >> num; 输出 printf(“%f”, num); printf(“%lf”, num); cout << num; 补充列表: