数据的维度
维度:一组数据的组织形式

一维数据
一维数据由对等关系的有序或无序数据构成,采用线性方式组织
列表和数组:一组数据的有序结构
列表:数据类型可以不同 3.1413, 'pi', 3.1404, [3.1401, 3.1349], '3.1376' 数组:数据类型相同 3.1413, 3.1398, 3.1404, 3.1401, 3.1349, 3.1376
二维数据
二维数据由多个一维数据构成,是一维数据的组合形式
表格是典型的二维数据其中,表头是二维数据的一部分
多维数据
多维数据由一维或二维数据在新维度上扩展形成

高维数据
高维数据仅利用最基本的二元关系展示数据间的复杂结构
{ "firstName":"Tian", "lastName" :"Song", "adress" :{ "streetAddr":"中关村南大街5号", "city" :"北京市", "zipcode" :"100081" }, "prof" :["Computer System", "Security"] }
数据维度的Python表示
一维数据:列表和集合类型
[3.1398, 3.1349, 3.1376] 有序
{3.1398, 3.1349, 3.1376} 无序
二维数据:列表类型
[ [3.1398, 3.1349, 3.1376],
[3.1413, 3.1404, 3.1401] ]
多维数据:列表类型
高维数据:字典类型 或数据表示格式
dict = { "firstName":"Tian", "lastName" :"Song", }
Numpy是什么
NumPy(Numerical Python的缩写)是一个开源的Python科学计算库。使用NumPy,就可以很自然地使用数组和矩阵。NumPy包含很多实用的数学函数,涵盖线性代数运算、傅里叶变换和随机数生成等功能。如果你的系统中已经装有LAPACK,NumPy的线性代数模块会调用它,否则NumPy将使用自己实现的库函数。LAPACK是一个著名的数值计算库,最初是用ortran写成的,Matlab同样也需要调用它。从某种意义上讲,NumPy可以取代Matlab和Mathematica的部分功能,并且允许用户进行快速的交互式原型设计。
NumPy是一个开源的Python科学计算基础库,包含:
- 一个强大的N维数组对象 ndarray
- 广播功能函数
- 整合C/C++/Fortran代码的工具
- 线性代数、傅里叶变换、随机数生成等功能
NumPy是SciPy、Pandas等数据处理或科学计算库的基础
为什么使用Numpy
对于同样的数值计算任务,使用NumPy要比直接编写Python代码便捷得多。这是因为NumPy能够直接对数组和矩阵进行操作,可以省略很多循环语句,其众多的数学函数也会让编写代码的工作轻松许多。NumPy的底层算法在设计时就有着优异的性能,并且经受住了时间的考验。NumPy是开源的,这意味着使用NumPy可以享受到开源带来的所有益处。价格低到了极限——免费。虽然NumPy本身不能用来绘图,但是Matplotlib和NumPy两者完美地结合在一起,其绘图能力可与Matlab相媲美。
Numpy的数组对象:ndarry
为了更好的进行科学计算,需要理解numpy的构成原理以及其中最关键的对象ndarry。
N维数组对象:ndarray
Python已有列表类型,为什么需要一个数组对象(类型)?
通过一个实例进行上述问题的分析:
例:计算A^2+B^3
在python中计算
# calculae A^2+B^3 def pySum(): a = [0, 1, 2, 3, 4] b = [9, 8, 7, 6, 5] c = [] for i in range(len(a)): c.append(a[i]**2 + b[i]**3) return c print(pySum()) # 输出结果 [729, 513, 347, 225, 141]
在引入numpy之后计算
# calculae A^2+B^3 numpy import numpy as np # AB属于同一维度时,可以直接运算,否则会报错 def npSum(): a = np.array([0, 1, 2, 3, 4]) b = np.array([9, 8, 7, 6, 5]) c = a**2 + b**3 return c print(npSum()) # 输出结果 [729 513 347 225 141]
通过上述两种运算方式的比较,可以得出所提问题的解:
- 数组对象可以去掉元素间运算所需的循环,使一维向量更像单个数据
- 设置专门的数组对象,经过优化,可以提升这类应用的运算速度
- 科学计算中,一个维度所有数据的类型往往相同
- 数组对象采用相同的数据类型,有助于节省运算和存储空间
ndarray是一个多维数组对象,由两部分构成:
- 实际的数据
- 描述这些数据的元数据(数据维度、数据类型等)
ndarray数组一般要求所有元素类型相同(同质),数组下标从0开始
ndarray实例
ndarry中两个重要的概念:轴(axis): 保存数据的维度;秩(rank):轴的数量
# ndarray import numpy as np # ndarray在程序中的别名是 array # np.array()生成一个ndarray数组 a = np.array([[1, 2, 3],[4, 5, 6]]) b = np.array([7, 8, 9]) # np.array()输出成[]形式,元素由空格分割 print(a) # 输出结果 [[1 2 3] [4 5 6]] print(b) # 输出结果 [7 8 9]
ndarray对象的属性
| 属性 | 说明 |
|---|---|
| .ndim | 秩,即轴的数量或维度的数量 |
| .shape | ndarray对象的尺度,对于矩阵,n行m列 |
| .size | ndarray对象元素的个数,相当于.shape中n*m的值 |
| .dtype | ndarray对象的元素类型 |
| .itemsize | ndarray对象中每个元素的大小,以字节为单位 |
元素属性实例
import numpy as np a = np.array([[1, 2, 3],[4, 5, 6]]) print(a.ndim) # 2 print(a.shape) # (2,3) print(a.size) # 6 print(a.dtype) # int32 print(a.itemsize) # 4
ndarry数组的元素类型
ndarray的元素类型(1) (表格在Word210%显示下截图)

ndarray的元素类型(2)

ndarray的元素类型(3)

ndarray为什么要支持这么多种元素类型?
- 对比:Python语法仅支持整数、浮点数和复数3种类型
- 科学计算涉及数据较多,对存储和性能都有较高要求
- 对元素类型精细定义,有助于NumPy合理使用存储空间并优化性能
- 对元素类型精细定义,有助于程序员对程序规模有合理评估
非同质ndarray对象无法有效发挥NumPy优势,尽量避免使用,实例如下
# ndarray非同质对象 import numpy as np x = np.array([[0,1],[2,3,4]]) print(x.shape) # (2,) print(x.dtype) # object print(x.size) # 2 print(x.ndim) # 1 print(x.itemsize) # 8 y = np.array([[0,1],[2,3]]) print(y.shape) # (2,2) print(y.dtype) # int32 print(y.size) # 4 print(y.ndim) # 2 print(y.itemsize) # 4
ndarry数组的变换ndarry数组的创建
- 从Python中的列表、元组等类型创建ndarray数组
- 使用NumPy中函数创建ndarray数组,如:arange, ones, zeros等

具体用法如下
# 创建numpy数组 import numpy as np x = np.arange(10) print(x) # 输出结果 [0 1 2 3 4 5 6 7 8 9] x = np.ones((3,6)) print(x) # 输出结果 [[1. 1. 1. 1. 1. 1.] [1. 1. 1. 1. 1. 1.] [1. 1. 1. 1. 1. 1.]] x = np.zeros((3,6)) print(x) # 输出结果 [[0. 0. 0. 0. 0. 0.] [0. 0. 0. 0. 0. 0.] [0. 0. 0. 0. 0. 0.]] x = np.ones((2,3,4)) print(x) # 输出结果 [[[1. 1. 1. 1.] [1. 1. 1. 1.] [1. 1. 1. 1.]] [[1. 1. 1. 1.] [1. 1. 1. 1.] [1. 1. 1. 1.]]] x = np.eye(5) print(x) # 输出结果 [[1. 0. 0. 0. 0.] [0. 1. 0. 0. 0.] [0. 0. 1. 0. 0.] [0. 0. 0. 1. 0.] [0. 0. 0. 0. 1.]]

具体用法如下
# 创建numpy数组 import numpy as np x = np.eye(5) print(x) # 输出结果 [[1. 0. 0. 0. 0.] [0. 1. 0. 0. 0.] [0. 0. 1. 0. 0.] [0. 0. 0. 1. 0.] [0. 0. 0. 0. 1.]] y = np.ones_like(x) print(y) # 输出结果 [[1. 1. 1. 1. 1.] [1. 1. 1. 1. 1.] [1. 1. 1. 1. 1.] [1. 1. 1. 1. 1.] [1. 1. 1. 1. 1.]] y = np.zeros_like(x) print(y) # 输出结果 [[0. 0. 0. 0. 0.] [0. 0. 0. 0. 0.] [0. 0. 0. 0. 0.] [0. 0. 0. 0. 0.] [0. 0. 0. 0. 0.]] y = np.full_like(x,5) print(y) # 输出结果 [[5. 5. 5. 5. 5.] [5. 5. 5. 5. 5.] [5. 5. 5. 5. 5.] [5. 5. 5. 5. 5.] [5. 5. 5. 5. 5.]]

具体用法如下
import numpy as np a = np.linspace(1, 10, 4) print(a) # 输出结果 [ 1. 4. 7. 10.] b = np.linspace(1, 10, 4, endpoint=False) # 不包含最后一个元素10,分成5份 print(b) # 输出结果 [1. 3.25 5.5 7.75] c = np.concatenate((a, b)) print(c) # 输出结果 [ 1. 4. 7. 10. 1. 3.25 5.5 7.75]
- 从字节流(raw bytes)中创建ndarray数组
- 从文件中读取特定格式,创建ndarray数组
ndarray数组的变换
对于创建后的ndarray数组,可以对其进行维度变换和元素类型变换
ndarray数组的维度变换
|
方法 |
说明 |
|
.reshape(shape) |
不改变数组元素,返回一个shape形状的数组,原数组不变 |
|
.resize(shape) |
与.reshape()功能一致,但修改原数组 |
|
.swapaxes(ax1,ax2) |
将数组n个维度中两个维度进行调换 |
|
.flatten() |
对数组进行降维,返回折叠后的一维数组,原数组不变 |
实例如下
# numpy数组变化 import numpy as np a = np.ones((2,3,4)) print(a) # 输出结果 [[[1. 1. 1. 1.] [1. 1. 1. 1.] [1. 1. 1. 1.]] [[1. 1. 1. 1.] [1. 1. 1. 1.] [1. 1. 1. 1.]]] b = a.reshape((3,8)) print(b) # 输出结果 [[1. 1. 1. 1. 1. 1. 1. 1.] [1. 1. 1. 1. 1. 1. 1. 1.] [1. 1. 1. 1. 1. 1. 1. 1.]]
ndarray数组的类型变换
# numpy数组元素类型变化 import numpy as np a = np.ones((2,3), dtype=np.int) print(a) # 输出结果 [[1 1 1] [1 1 1]] b = a.astype(np.float) print(b) # 输出结果 [[1. 1. 1.] [1. 1. 1.]]
ndarry数组的操作
# numpy数组的操作 import numpy as np a = np.arange(24).reshape(2,3,4) print(a) # 输出结果 [[[ 0 1 2 3] [ 4 5 6 7] [ 8 9 10 11]] [[12 13 14 15] [16 17 18 19] [20 21 22 23]]] print(a[1,2,3]) # 23 print(a[0,1,2]) # 6 print(a[-1,-2,-3]) # 17
数组的切片
print(a[:,1,-3]) # [ 5 17] print(a[:,1:3,:]) # 1:3 左闭右开,包含1,不包含3 # 输出结果 [[[ 4 5 6 7] [ 8 9 10 11]] [[16 17 18 19] [20 21 22 23]]] print(a[:,:,::2]) # 输出结果 [[[ 0 2] [ 4 6] [ 8 10]] [[12 14] [16 18] [20 22]]]
ndarry数组的运算
数组与标量之间的运算
# numpy数组的运算 import numpy as np a = np.arange(24).reshape(2,3,4) print(a.mean()) # 11.5 a = a/a.mean() print(a) # 输出结果 [[[0. 0.08695652 0.17391304 0.26086957] [0.34782609 0.43478261 0.52173913 0.60869565] [0.69565217 0.7826087 0.86956522 0.95652174]] [[1.04347826 1.13043478 1.2173913 1.30434783] [1.39130435 1.47826087 1.56521739 1.65217391] [1.73913043 1.82608696 1.91304348 2. ]]]
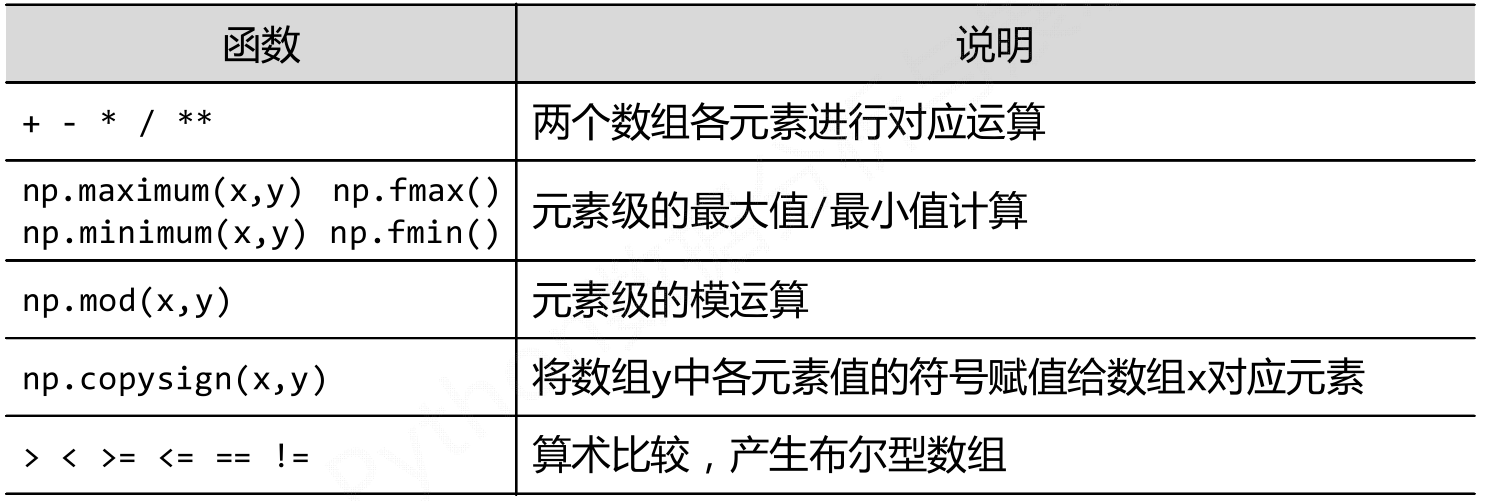
Numpy的运算函数
NumPy一元函数


NumPy二元函数