导入外部数据
导入数据主要用到的四Pandas的pd.read_x()方法,x表示待导入文件的格式。
导入.xlsx文件
在Excel中导入.xlsx格式的文件很简单,双击打开即可。
在Python中导入.xlsx文件的方式是pd.read_excel()
基本导入
在导入文件时首先要指定文件路径,也就是在这个文件在电脑中的哪个文件夹下存着。

电脑中文件路径默认使用,这个时候需要在路径前面加一个r,表示原生字符串,避免路径里面的被转义。
也可以不加r,但是我们需要把路径中的改为/,这个规则在导入其他格式文件时也是一样的,我们一般选择在路径前面加r。
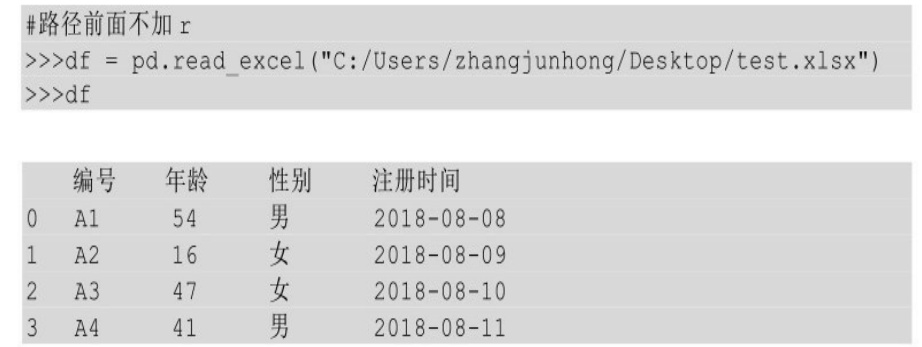
指定导入哪个Sheet
.xlsx格式的文件可以有多个Sheet,你可以通过设计sheet_name参数来指定要导入哪个Sheet的文件。

除了可以指定具体Sheet的名字,还可以传入Sheet的顺序,从0开始计数。

如果不指定sheet_name参数时,那么默认导入的都是第一个Sheet的文件。
指定行索引
将本地文件导入DataFrame时,行索引使用的从0开始的默认索引,可以通过设置index_col参数来设置

index_col表示用.xlsx文件中的第几列做行索引,从0开始计数。
指定列索引
将本地文件导入DataFrame时,默认使用源数据表的第一行作为列索引,也可以通过设置header参数来设置列索引。
header参数值默认为0,即用第一行作为列索引。也可以是其他行,只需要传入具体的那一行即可。
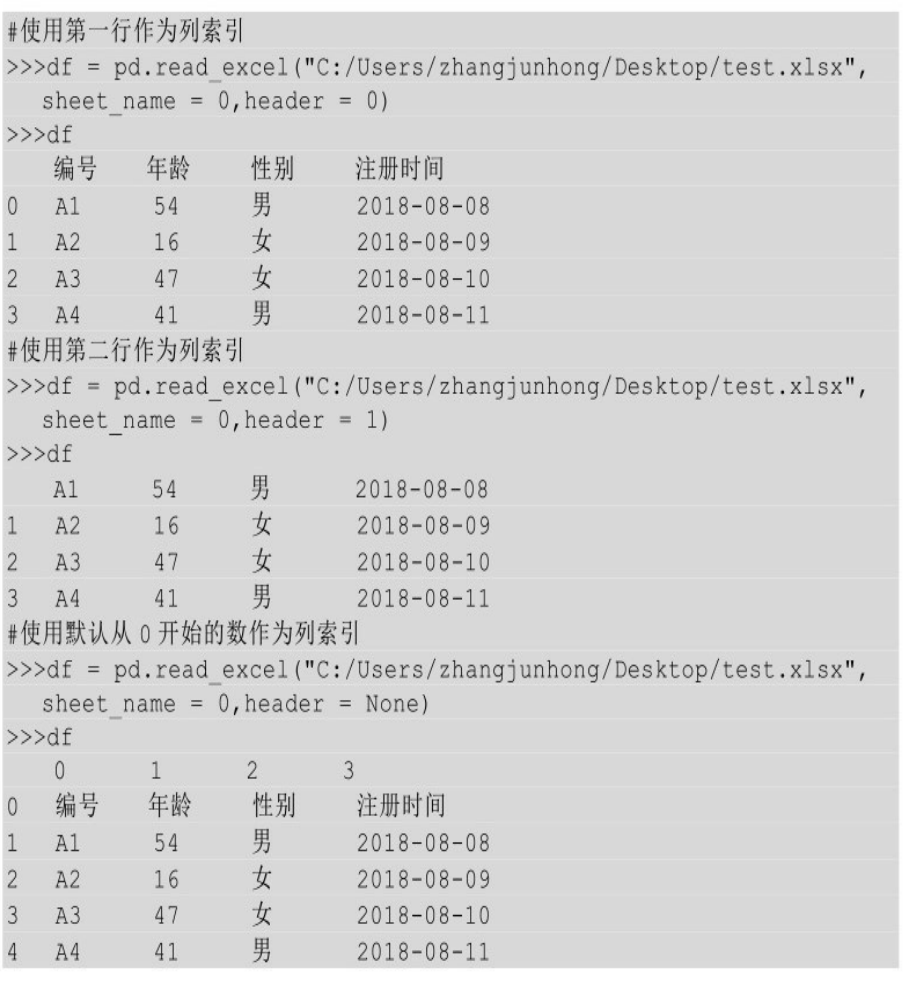
导入指定列
有的时候本地文件的列数太多,而我们又不需要那么多列时,可以通过设置usecols参数来指定要导入的列。

可以给usecols参数具体的某个值,表示要导入第几列,同样从0开始计数,也可以以列表的形式传入多个值,表示要传入哪些列。
导入.csv文件
在Excel中导入.csv格式的文件和打开.xlsx格式的文件一样,双击即可。
而在Python中导入.csv文件用的方法是pd.read_csv()。
直接导入
只需要指明文件路径。

指明分隔符号
在Excel和DataFrame中的数据都是很规整的排列的,这都是工具在后台根据某条规则进行切分的。
pd.read_csv()默认文件中的数据都是以逗号分开的,但是有的文件不是用逗号分开的,这个时候需要人为指定分隔符号,否则会报错。
使用参数sep指定分隔符。

使用正确的分隔符号以后,数据被规整地分好了。常见的分隔符号除了都逗号、空格,只有制表符 。
指明读取行数
假设现在有一个几百兆的文件,你先了解下这个文件里面有哪些数据,那么这个时候你就没有必要把全部的数据导入,只需要看前面的几行即可,因此只要设置 nrows 参数即可。

指定编码格式
Python用的比较多的两种编码格式是UTF-8和gbk,默认编码格式是UTF-8。
我们要根据导入文件本身的编码格式进行设置,通过设置参数encoding来设置导入的编码格式。
有的时候两个文件看起来一样,也是不一样的文件,比如把一个Excel文件另存为时会出现两个选项,虽然都是.csv文件,但是这两种格式代表两种不同的文件。
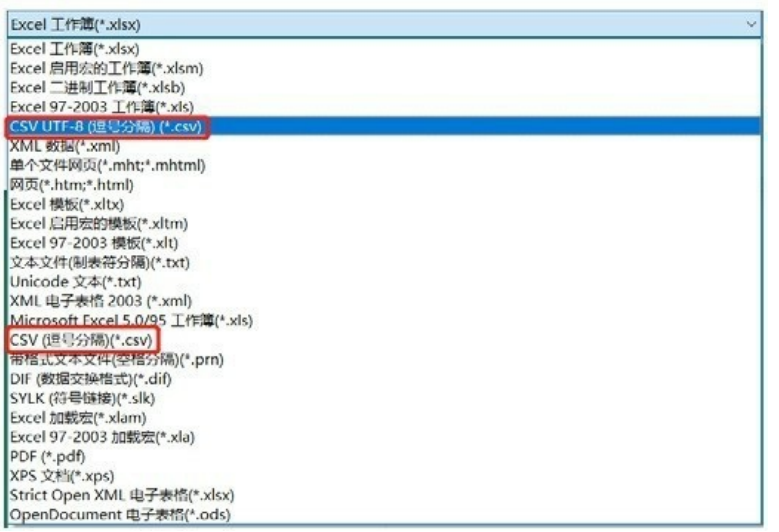
如果是前者,那么导入的时候可以不指定encoding,因为python默认的编码格式就是UTF-8。
但是如果是后者,那么encoding='gbk'。
engine指定
当文件路径或者文件名中包含中文时,如果还用上面的导入方式就会报错。

这个时候我们就可以通过设置engine参数来消除这个错误。(现在已经不存在这个错误了..)
这个错误产生的原因是当调用pd.read_csv()时,默认使用C语言作为解析语言,我们只需要把门口人的C更改为Python就可以了。
注意:如果使用Python,那个utf-8需要更改为 utf-8-sig

其他
.csv文件也涉及行、列索引设置以及指定导入某列或某几列,设定方法与导入.xlsx文件一致。
导入.txt文件
在Excel中导入.txt文件时,我们需要通过一次点击菜单栏中的 数据>获取外部数据>自文本,然后选择导入.txt文件所在路径。

选完路径以后会出现下图所示界面,预览文件就是我们要导入的文件,确认无误后按下一步即可。
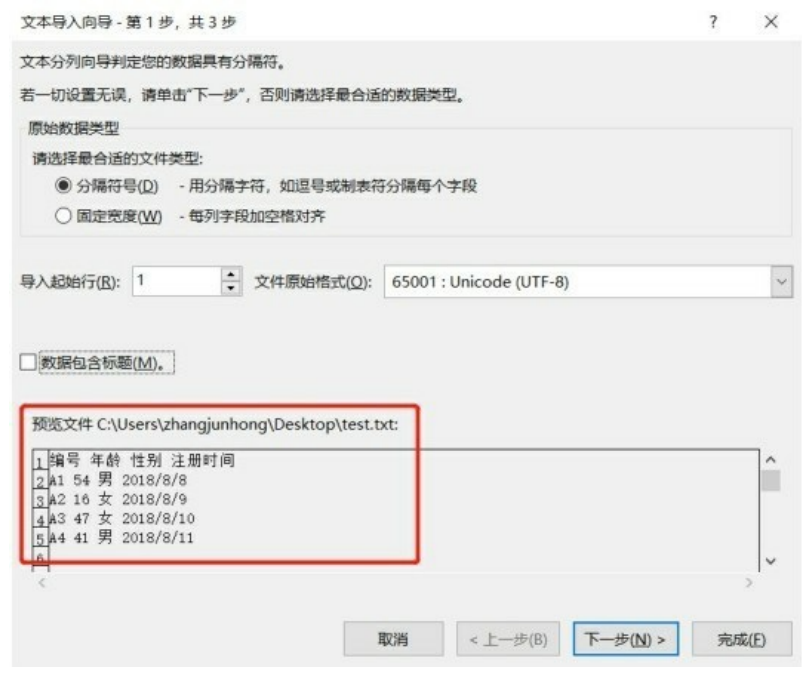
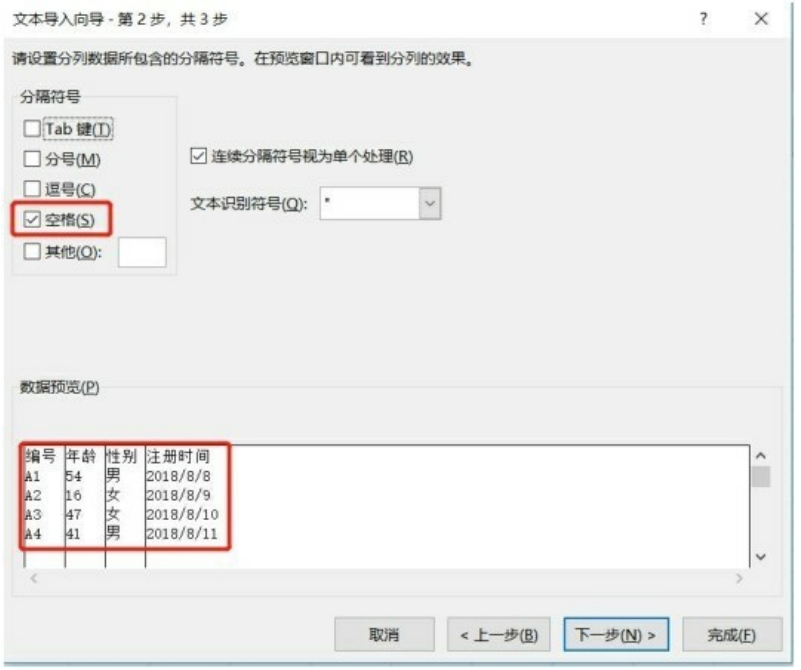
因为我们举例的.txt 文件是用空格分开的,所以在分隔符号项勾选空格复选框,如果待导入的.txt 文件是用其他分隔符号分隔的,那么选择对应的分隔符号,然后直接按完成按钮即可,如下图所示。
在Python中带入.txt文件用的方法时pd.read_table(),pd.read_table()是利用分隔符分开的文件导入DataFrame的通用函数。它不仅可以导入.txt文件,还可以导入.csv文件。
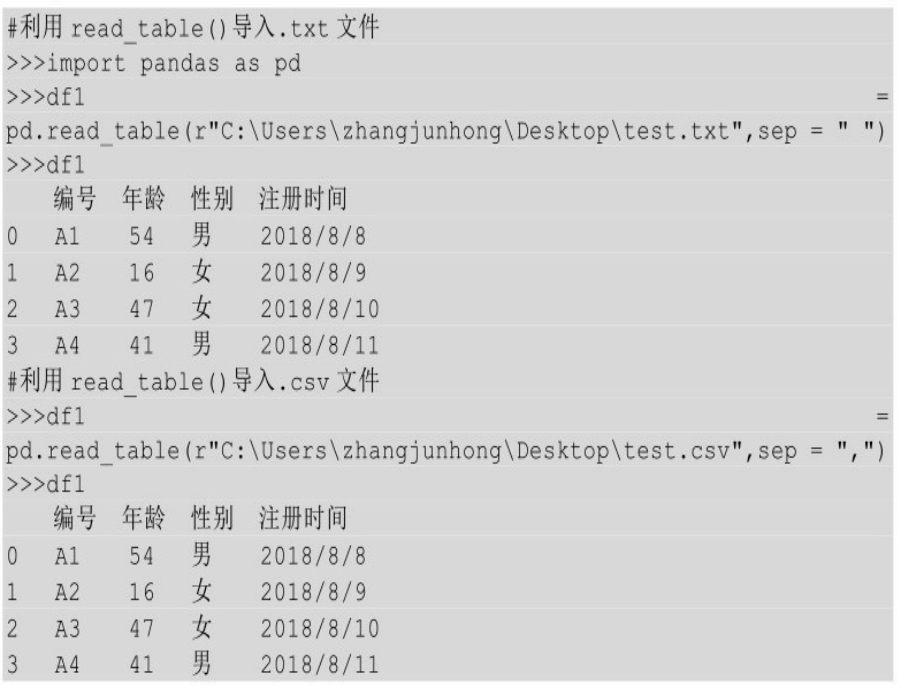
从上面的代码可以看出,函数在导入.csv文件时,与pd.read_csv()不同的是, 即使是逗号分隔的文件也需要用sep指明分隔符号。 pd.read_csv()如果是逗号分隔的话,则可以不写。
pd.read_table()与pd.read_csv()用法基本一致。
导入.sql文件
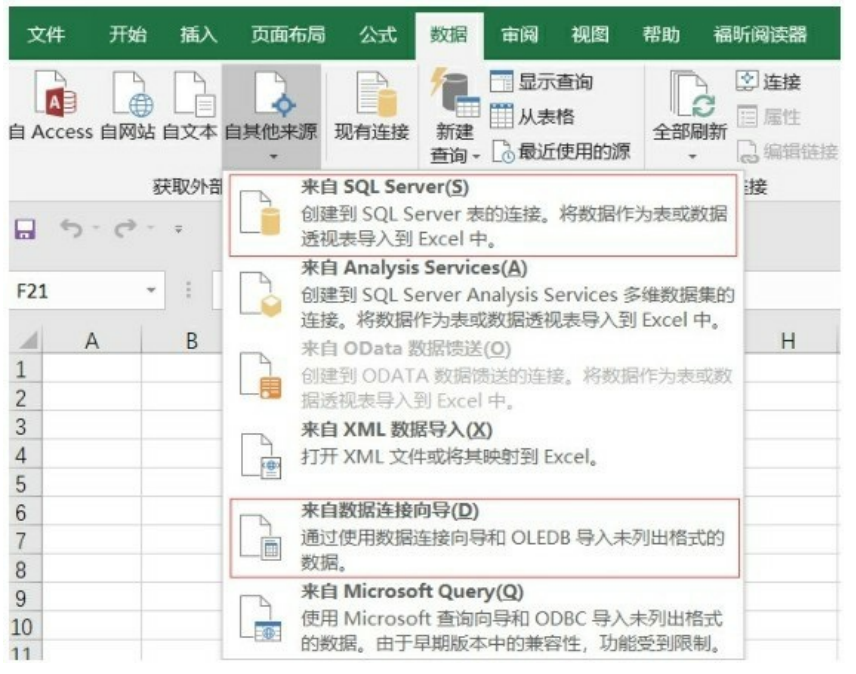
Excel 可以直接连接数据库,通过依次单击菜单栏中的数据>自其他 来源导入 sql文件。如果你的数据库是SQL Server,那么直接选择来自 SQL Server即可;如果是MySQL 数据库,那么你需要选择来自数据连接向导,然后通过建立数据向导来与MySQL连接,如下图所示。
Python导入sql文件主要分布两步,第一步将Python与数据库进行连接,第二部是利用Python执行sql查询语句。

连接好数据库以后,使用sql查询语句,利用pd.read_sq()方法。

除了sql和con这两个关键参数,pd.read_csv()也有用来设置行索引的参数index_col,设置列索引的参数columns。

新建数据
这里的新建数据主要指新建DataFrame数据,在前面已经讲解过使用pd.DataFrame()进行新建。
熟悉数据
当我们有了数据源以后,先别着急分析,应该先熟悉数据,只有对数据充分熟悉了,才能更好地进行分析。
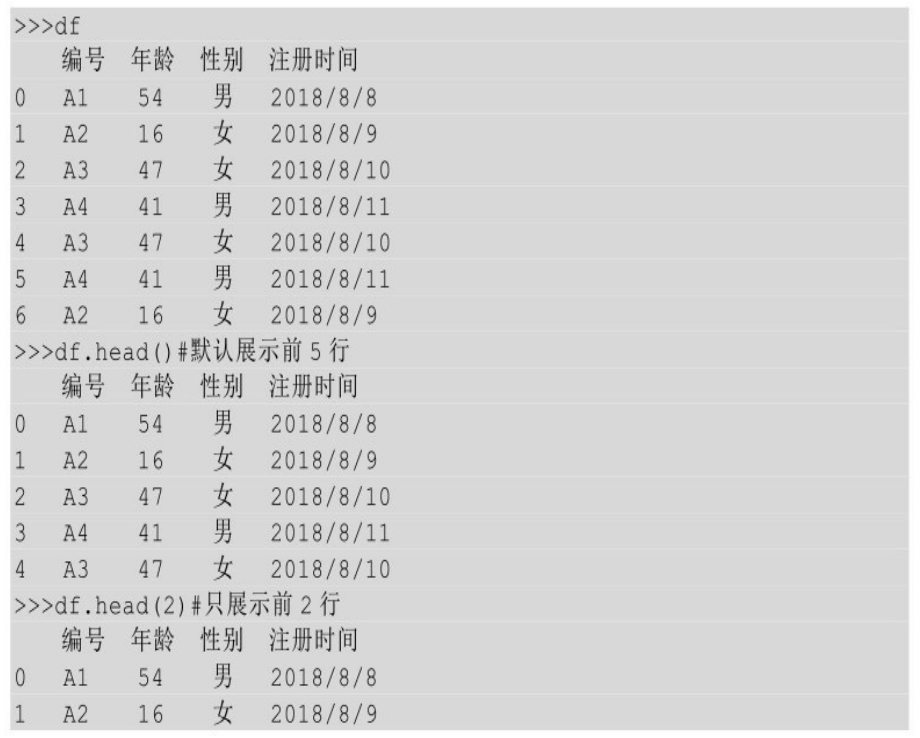
利用head预览前几行
当数据表中包含数据行数过多时,而我们又想看一下每一列数据都是什么样的数据时,就可以只把数据表中前几行数据显示出来进行查看。
Excel其实没有严格一样的显示前几行,当你打开一个数据表时,所有数据就全展示出来了,如果数据的行数过多,则可以通过滚动条来控制。
python中,当一个文件导入后,可以使用head()来控制要显示哪些行。只想要在head后面的括号中输入要展示的行数即可,默认显示5行。
利用shape获取数据表的大小
熟悉数据的第一点就是先看一下数据表的大小,即数据表又多少行,多少列。
在Excel中查看数据表有多少行,一般都是选中某一列,右下角就会出现在该表的行数。
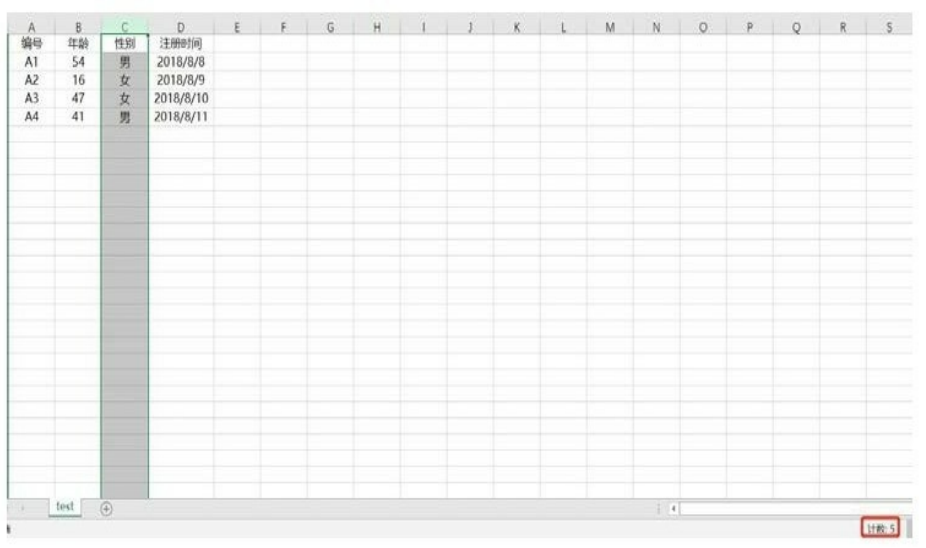
在Excel中选中某一行,右下角就会出现该表的列数。

在Python中查看数据表的行、列数利用的shape属性。

shape属性会以元组的形式返回行、列。
上面代码中的(4,4)表示df表有4行4列数据。
注意:Python中利用shape获取行数和列数时不会把行索引和列索引计算在内,而Excel中是把行索引和列索引计算在内的。
利用info获取数据类型
熟悉数据的第二点就是看一下数据类型,不同的数据类型的分析思路是不一样的,比如数值类型的数据可以求平均值,但是字符串类型的数据就没法求平均值了。
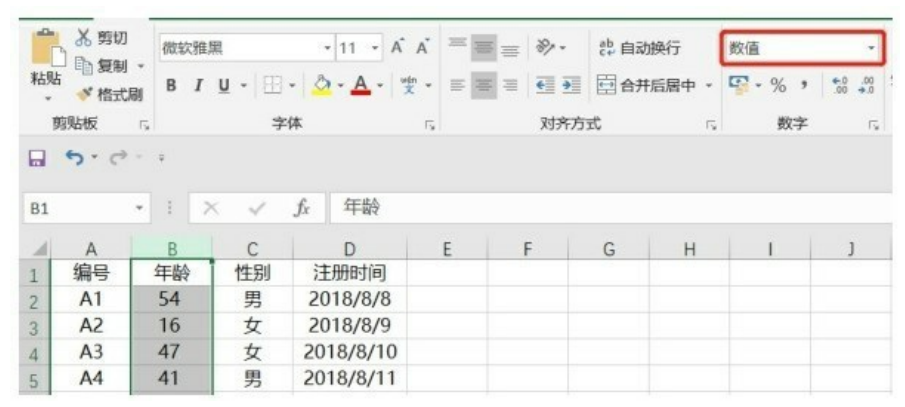
在Excel中,若想看某一列数据具体是什么类型的,只要把这一列选中,然后再菜单栏中的数字那一栏就可以看到这一列的数据类型。

在Python中我们可以利用info()方法查看数据表中的数据类型,而不需要一列一列的查看。
调用info()以后就会输出整个表中所有列的数据类型。
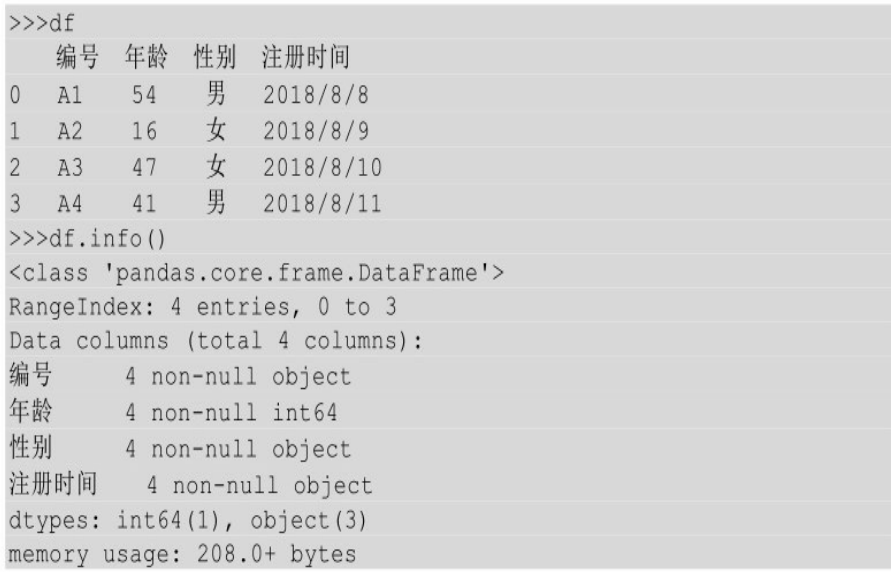
通过info()方法可以看出表df的行索引index是0~3,总共4columns,分别是编号、年龄、性别及注册时间,且4columns中只有年龄是int类型,其他columns都是object类型,共占用内存208bytes。
利用describe获取数值分布情况
数据数据的第三点就是掌握数值的分布情况,即平均值是多少,最值是多少,方差及分位数分别又是多少。
在Excel中如果想看某列的数值分布情况,那么手动选中这一列,在Excel的右下角就会显示出这一列的平均值、计数及求和,且只显示这三个指标。如果想了解其他指标,后面会进行介绍。
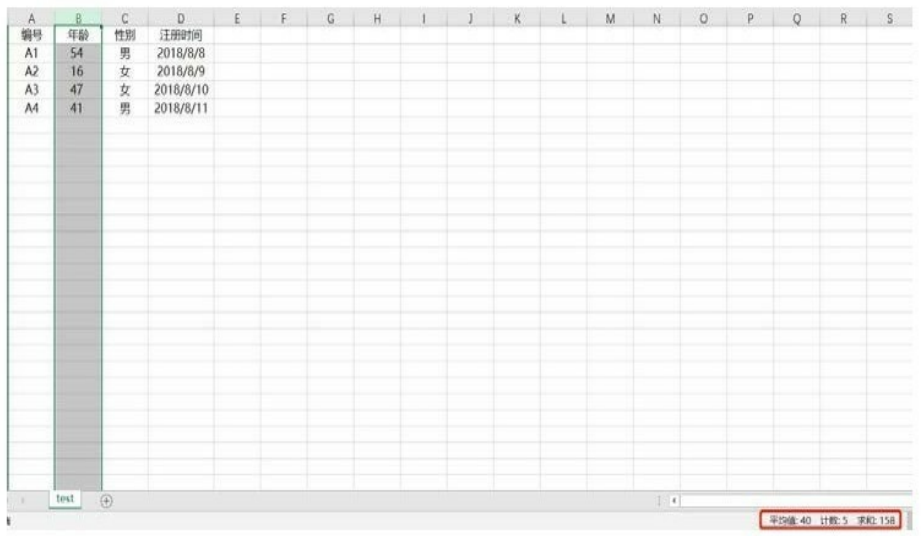
在Python中只需要利用describe()就可以获取所有数值类型字段的分布值。
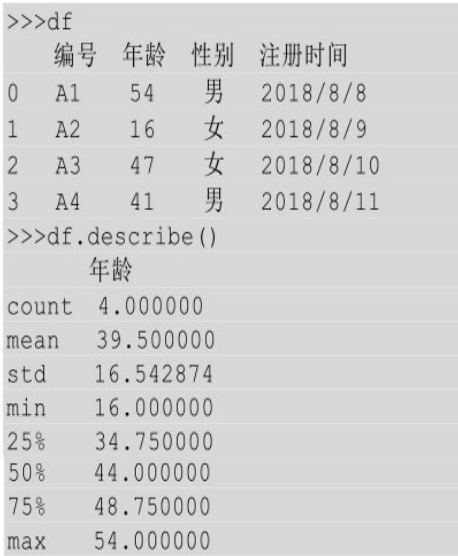
表df只有年龄这一列是数值类型,所以调用describe()时,只计算了年龄这一列的相关数值分布情况。我们可以想见新建一个含有多列数字类型字段的DataFrame。
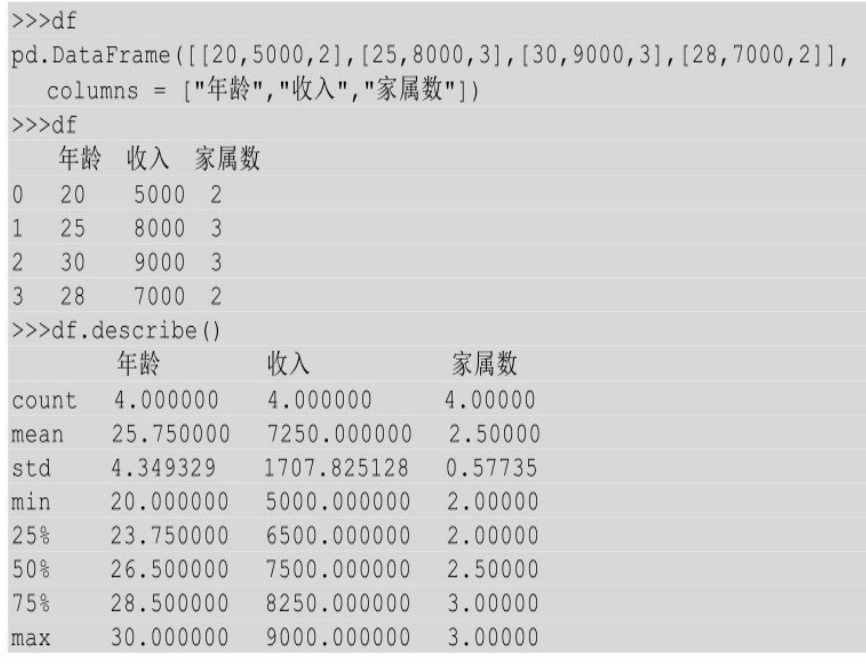
上面的表df中年龄、收入、家属数都是数字类型,所以在调用describe()的时候,会同时计算着三列的数值情况。
小结
Pandas导入外部文件
导入xlsx pd.read_excel()
指定sheet 参数 sheet_name="Sheet1" | sheet_name=0 # 指定sheet名字或sheet的下标
指定列 参数usecols 传入一个列表,表示要用哪几列
指定列索引 header 默认值0 表示使用第一行作为列索引
指定行索引 index_col 传入下标 指定那个列作为行索引
导入csv pd.read_csv()
指定前几行 nrows
指定分隔符 sep
指定解析引擎 engine (基本不用)
指定编码格式 encoding
指定行、列索引,指定哪几列数据 与导入xlsx文件一致
导入txt pd.read_table()
pd.read_table() 和 pd.read_csv() 基本没有差别,只不过前者一定要指定sep,后者默认sep=','
导入sql pd.read_sql()
pd.read_sql(sql,con)
# sql是要执行的sql语句
# con是数据库连接对象 con=pymysql.connect(...)
熟悉数据
查看前几行数据 head() # 默认为5
查看行数、列数 属性shape
查看字段数据类型 info()
查看数值分布(仅数值类型字段) describe()