导出为.xlsx文件
设置文件导出路径
设置文件导出路径就是告诉Python要将这个文件导出到电脑的哪个文件夹里,且导出以后这个文件叫什么。通过调整参数excel_writer的值即可实现。

上面代码表示将表df导出到桌面,且导出以后的文件名为测试文档,导出以后的文档如下所示。
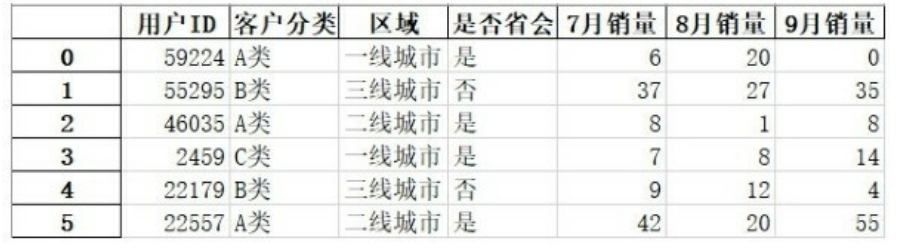
需要注意的是,如果同一导出文件已经在本地打开,则不能再次运行导出代码,会报错,需要将本地文件关闭以后再次运行导出代码。这有点类似于在本地修改文件名的操作,如果文件是打开的,即被占用的状态,那么不可以执行修改文件的操作。
设置Sheet名称
.xlsx格式的文件有多个Sheet,Sheet的默认命名方式是Sheet后加阿拉伯数字,通常从 Sheet1往上递增,我们也可以对默认的 Sheet 名字进行修改,只要修改sheet_name参数即可,具体实现如下所示。

运行上面代码以后,导出到本地文件的Sheet名字将从原来的Sheet1变成测试文档。
设置索引
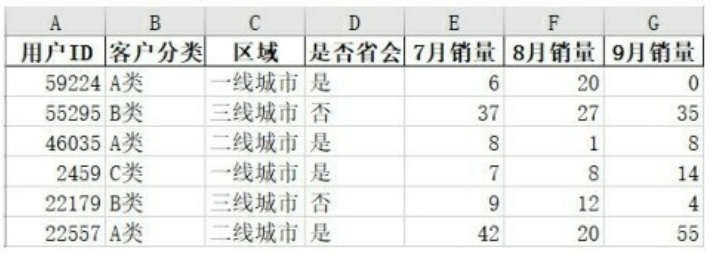
上面导出文件中关于索引的参数都是默认的,也就是没有对索引做什么限制,但是我们可以看到index索引使用的是从0开始的默认自然数索引,这种索引是没有意义的,设置参数index=False就可以在导出时把这种索引去掉,具体实现如下所示。

上面代码运行的结果如下图所示,从0开始的自然数索引没有被展示出来。
设置要导出的列
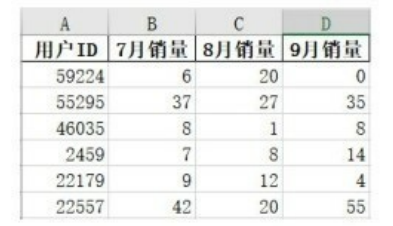
有的时候一个表的列数很多,我们并不需要把所有的列都导出,这个时候就可以通过设置columns参数来指定要导出的列,这和导入时设置只导入部分列的原理类似,代码如下所示。

下图为只导出用户ID、7月销量、8月销量、9月销量的结果文件。
设置编码格式
我们在导入文件时需要设置编码格式,导出文件的时候同样也需要,修改编码格式的参数与导入文件时的一致,也使用的encoding,encoding参数值一般选择"utf-8"。

缺失值处理
虽然我们在前面的数据预处理过程中已经处理了缺失值,但是在数据分析过程中也可能会产生一些缺失值,如果在导出的时候,数据表中有缺失值,那么就要对表中的缺失值进行填充,使用的参数为na_rep,具体实现如下所示。

无穷值处理
无穷值(inf)与缺失值(Nan)都是异常数据,当你用一个浮点数除以0时,就会得到一个无穷值,无穷值的存在会导致接下来的计算报错,所以需要对无穷值进行处理。
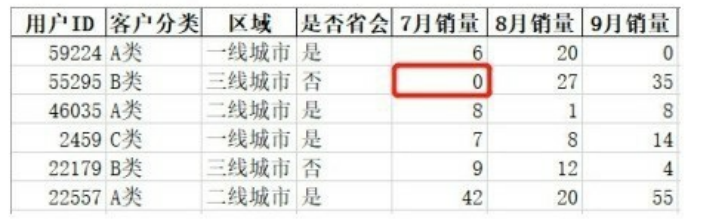
下面的数据表中含有inf值,要把inf值替换掉,就要设置参数inf_rep的值。

把inf_rep的值填充为0,具体实现如下所示。

下图为导出到本地的文档,可以看到inf值已经被替换成0了。
导出为.csv文件
设置文件导出路径
设置.csv 文件的导出路径时,与设置.xlsx 文件的导出路径一样,但是参数不一样,.csv文件的导出路径需通过path_or_buf参数来设置。

导出.csv文件时的注意事项与导出.xlsx文件时的注意事项一致:如果同一导出文件已经在本地打开,则不能再次运行导出代码,那样会报错,需要将本地文件关闭以后再运行导出代码。
设置索引
导出.csv 文件时与导出.xlsx 文件时对索引的设置是一致的,可以通过设置 index参数,让从0开始的默认自然数索引不展示出来。

设置要导出的列
导出.csv文件时也可以设置要导出哪些列,用的参数同样是columns。

设置分隔符
分隔符号就是用来指明导出文件中的字符之间是用什么来分隔的,默认使用逗号分隔,常用的分隔符号还有空格、制表符、分号等。用参数sep来指明要用的分隔符号。

设置编码格式
在Python 3中,导出为.csv文件时,默认编码为UTF-8,如果使用默认的UTF-8编码格式,导出的文件在本地电脑打开以后中文会乱码,所以一般使用utf-8-sig或者gbk编码。

缺失值处理
导出.csv文件时用的缺失值处理方法与导出.xlsx文件时用的缺失值处理方法是一样的,也是通过参数na_rep来指明要用什么填充缺失值。

将文件导出为多个sheet
有的时候一个脚本一次会生成多个文件,可以将多个文件分别导出成多个文件,也可以将多个文件放在一个文件的不同 Sheet 中,这个时候要用 ExcelWriter()函数将多个文件分别导出到不同Sheet中,具体方法如下:

小结
导出为xlsx
to_excel()
参数 excel_writer 保存路径
参数 sheet_name 修改sheet表名
参数 index (False/True) 设置为False 则不导出索引(如果要索引的话,一般先 reset_index)
参数 columns 设置要导出的列
参数 encoding='utf-8'
参数 na_rep=0 处理缺失值
参数 inf_rep=0 处理无穷值
导出为csv
to_csv()
参数 path_or_buf 保存路径
参数 index (False/True) 设置为False 则不导出索引(如果要索引的话,一般先 reset_index)
参数 encoding='utf-8'
参数 columns 设置要导出的列
参数 na_rep=0 处理缺失值
参数 inf_rep=0 处理无穷值
参数 sep=',' 设置分隔符
导出为多个Sheet
pd.ExcelWriter()