注意力分数

刚刚的注意力权重,如何设计使得和我们现在的东西比较相像?里面一个东西叫做注意力分数。
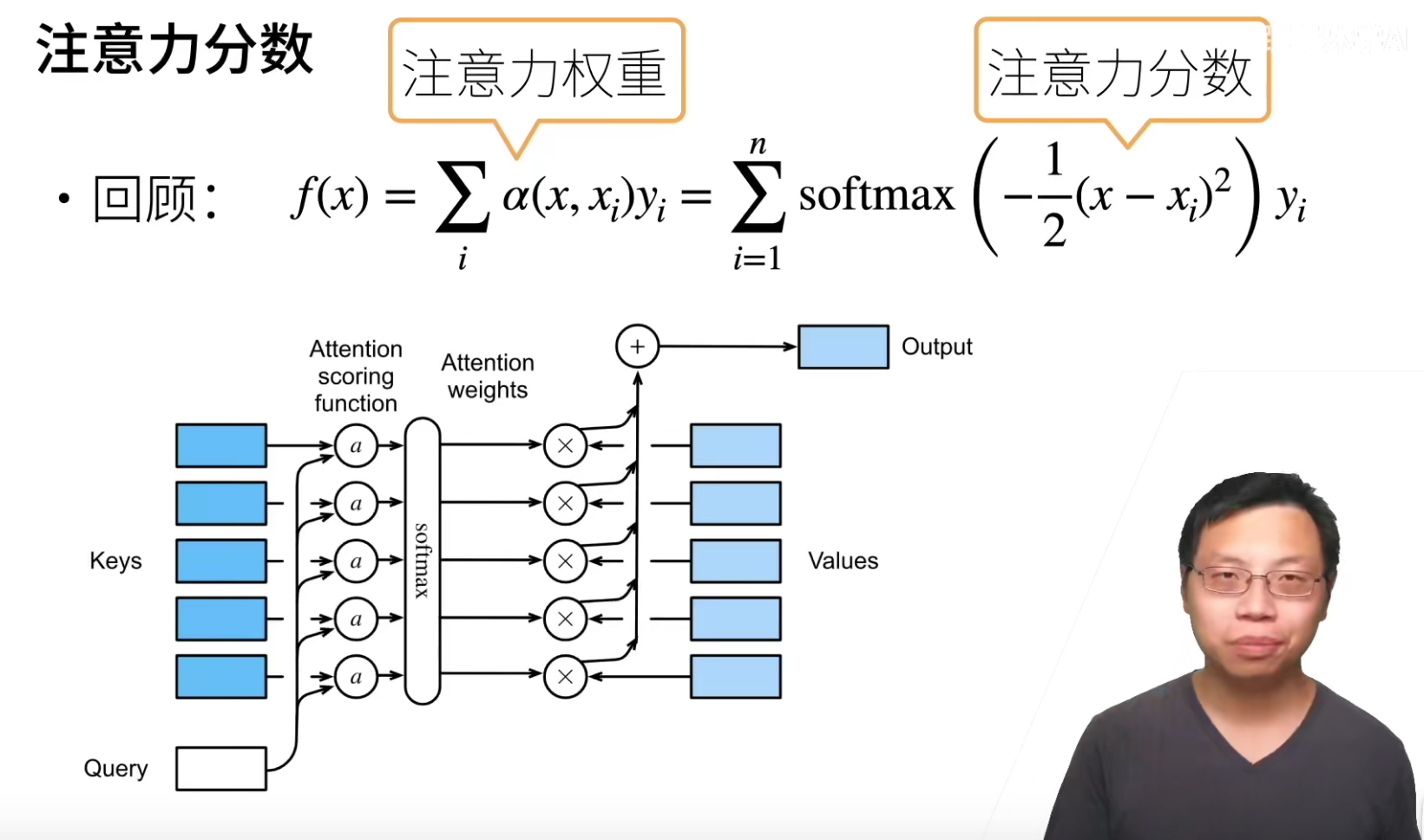
可以看看之前的使用过了高斯核的注意力。
上图有一堆key-value pair(训练时候的x和y),输入一个query(推理时候的x),然后query和每一个key做一个计算,得到一个注意力分数a,然后这些注意力分数a经过softmax得到注意力权重,然后(alpha(x,x_i)y_i)就可以得到一个注意力的输出。

拓展到高维度,就是这些向量可以是长度不同的,应该怎么处理呢?

可加性的注意力是什么意思?
k是长度为k的向量,q是长度为q的向量,那么(W_kk)会得到一个长度为h的向量,(W_qq)也会得到一个长度为h的向量,然后将两个向量加起来,再和长度为h向量v进行计算。
好处:key,value可以是任意的长度

如何query和key的长度一样,长度为d,那么最简单的方式就是不学东西,直接query和key进行内积,在除$sqrt{d} $
这个操作就是让其相对来说对参数没有那么敏感。
这个的好处是不用学习参数。

代码

QA
- 把之前的x和x_i换成了q和k_i吗?
是的,之前核方法的注意力那里使用的是x和x_i,这里换成了q和k_i。
沐神说干脆下次把书的公式进行统一,统一为q和k_i。