一、需求分析
利用java线程的相关知识实现
1)实现两个容器类 Path 和 PathContainer
JML规格⼊⻔级的理解和代码实现
2)实现容器类 Path 和数据结构类 Graph
JML规格进阶级的理解和代码实现、设计模式的简单实战,以及单元测试的初步使用尝试。
3)实现容器类 Path ,地铁系统类 RailwaySystem
二、思路分析
1、基于度量的程序结构分析
代码设计复杂度(利用MetricsReloaded插件)
ev(G)基本复杂度,用来衡量程序非结构化程度
iv(G)模块设计复杂度,用来衡量模块判定结构
v(G)独立路径条数
第一次
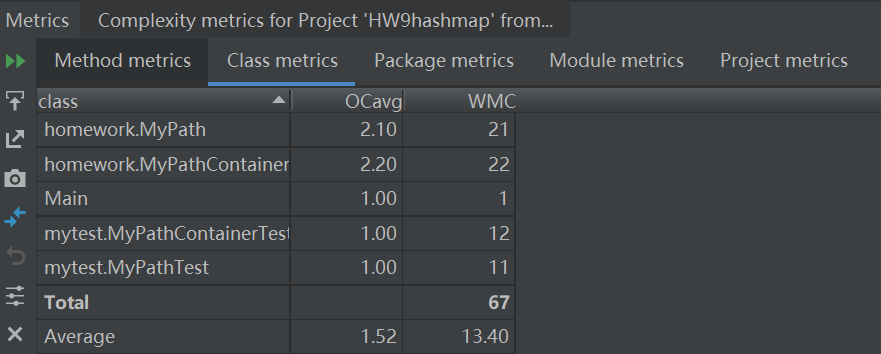
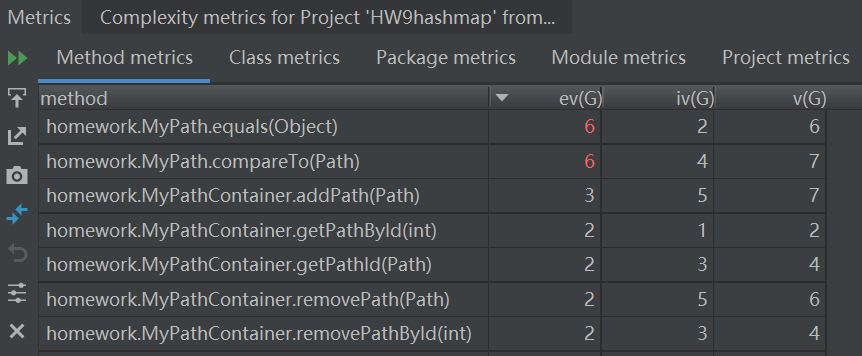
第二次
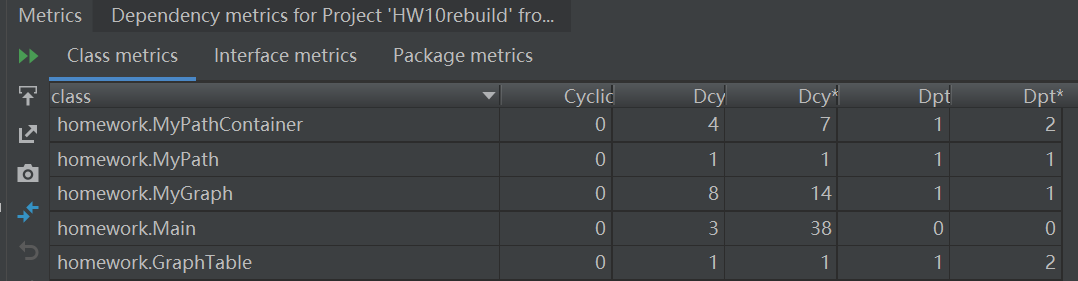
第三次


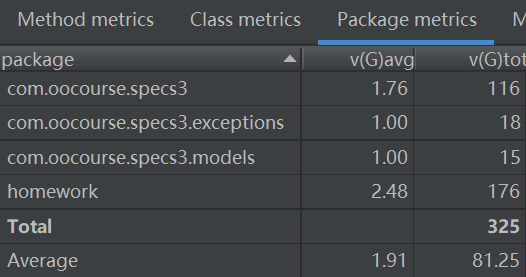
2、BUG分析
第一次:
强测中得分 100
互测:未被hack。未hack到别人。
坑点:
1、Integer是int的包装类,判断两个Integer类型相等不能直接通过“==”判断,而要用equals
身边有同学在第三次作业强测中才发现这个问题(第一次作业的bug带到了第三次。所以及早发现bug也是一件好事,避免扩展时候出现更惨烈的bug。
亡羊补牢,未为晚也。
2、关于compareTo方法的写法。
如果采用内置的字符串比较的写法的话,要注意不能直接相减,极端值会溢出导致相反的结果。直接用大于小于号判断即可。
第二次:
在强测中得分 100
互测:未被hack。未hack到别人。
坑点:
用hashmap存边时,如果remove一条边前这条边的键值为1(即无重边),则需要特判这种情况。
第三次:
在强测中得分 100
互测:未被hack。未hack到别人。
坑点:
龙宝宝判断一个容器为空时,直接用容器的指针==NULL来判断了。
3、架构分析
第一次:
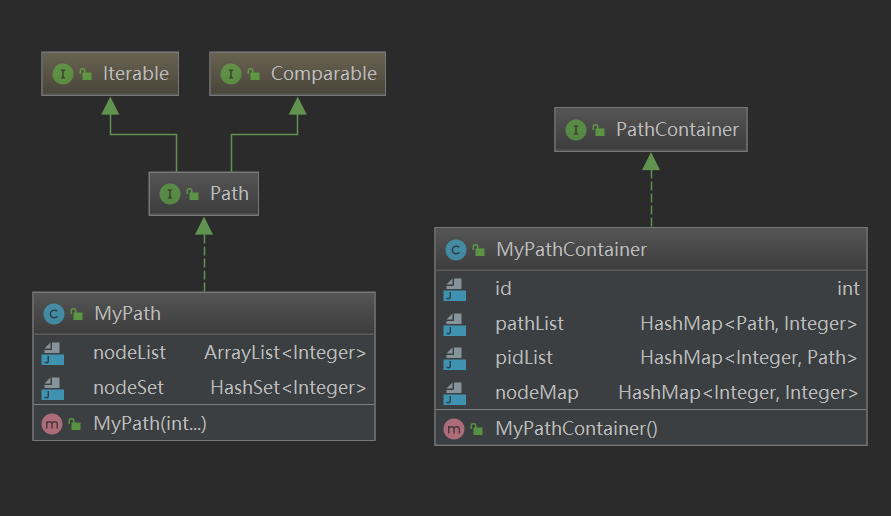
五容器大法
Path:
ArrayList保存边
HashSet处理本质不同边数计数的问题
关于容器的选择:
HashMap OR TreeMap?
参见赵博PPT
第二次:

相比第一次,加入了对于图的处理。
保存图:二维矩阵实现的邻接表,用arraylist套hashset来保存,能够有效地处理重边和自环的问题。
因为点的id在int范围内,而点数不多,故将点离散化。采用hashmap单独离散化,可以方便查找点是否存在。
每次修改的时候重构图,并求n次单源最短路。
关于最短路算法:
dijstra+边权为1==>bfs
第三次:
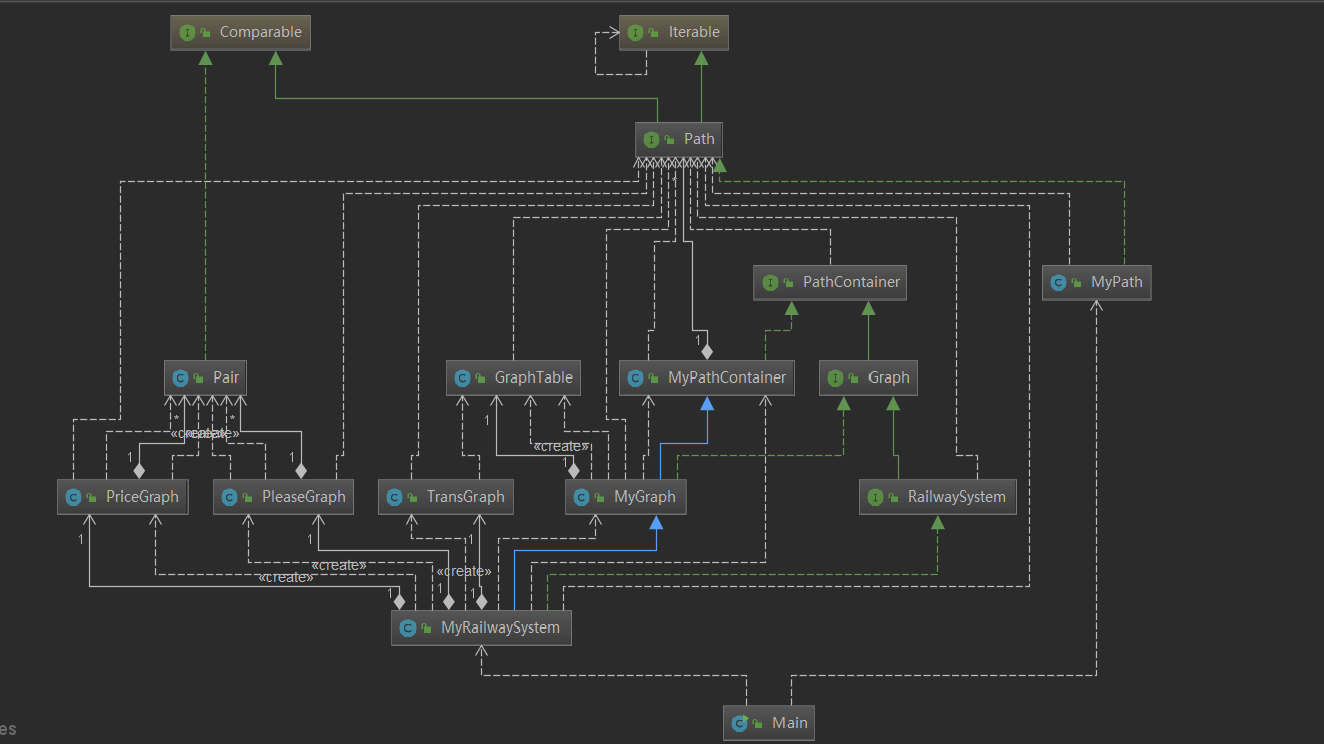
完全没有重构。
相比第二次,加入了一些算法来解决近似实际规模的问题。
对于第11次作业,其实就是一道算法题揉起来。大概是解决这几个问题: 最短路:普通边权1,换乘边权0
这样其实只需要跑4次最短路就好了。但是为了复用第10次作业的代码,我做出了如下调整:
最短路:
仍然bfs
最小换乘:
缩点,将每条线路看作一个点,可以换乘的线路间连线。这样也可以转化为bfs实现
但是统计答案的时候要知道每个点是属于那条线路的,所以nodetoPaths记录每个点属于哪条边。
int pathid = ptoid.get(p); for (int i = 0; i < p.size(); ++i) { nodetoPaths.get(map.get(p.getNode(i))).add(pathid); }
查询时查找点所在的路径集合中距离最小的即为答案:
Set<Integer> fromSet = getGt().getNodeidPaths(fromNodeId); Set<Integer> toSet = getGt().getNodeidPaths(toNodeId); int ans = Inf; //max=50 for (int fp : fromSet) { for (int tp : toSet) { int tmp = g1.getAns(fp, tp); if (tmp != -1 && tmp < ans) { ans = tmp; } } }
最小化函数式:
因为这里的k=2,所以就换乘站拆点 换乘权设为2。
举个例子,13号线的西二旗和昌平线的西二旗视为两个站 之间有一条权为2的边,正常的边权为1。
这个拆点是指,不同的线路、同一条线路不同点间需要区别开。 这样每次增加都要增加很多个点,(具体复杂度没时间写了就不展开计算了),这些点之间沟通只能相互连边,这样铁定会形成一个完全图。边数太多了,而求最短路的算法复杂度都与边有关,所以采用算法竞赛中常用的“建汇点”的方式,相当于建一个中转站,转化为菊花图。这样点数不变,但是边数会大大减小。


1 public void buildGraph(Set<Path> paths, HashMap<Integer, Integer> map) { 2 //对图进行初始化,大概拆点的写法会拆出5000个点,原本的点有120个。我开大了一点,防止RE。 3 graph = new ArrayList<>(); 4 for (int i = 0; i < 6000; ++i) { 5 graph.add(new HashSet<>()); 6 } 7 for (int i = 0; i < 300; i++) { 8 for (int j = 0; j < 6000; j++) { 9 dis[i][j] = -1; 10 } 11 } 12 13 nodeNum = map.size(); 14 this.map = map; 15 int nodeId = nodeNum; 16 for (Path p : paths) { 17 HashMap<Integer, Integer> pathMap = new HashMap<>();//存储菊花图中每个点对应的汇点id 18 int fi = p.getNode(0);//先取出i=0的点来,i>=1的点分别处理与前一个点的边。 19 pathMap.put(fi, ++nodeId);//因为汇点是另外添加的,要给其赋值id,而不能改变原图总结点数nodeNum 20 //++nodeNum; 21 int flowerid = map.get(fi);//菊花图中每个“花瓣”点。 22 graph.get(flowerid).add(new Pair(pathMap.get(fi), 16));//花瓣与汇点连接,边权为1/2的换乘代价。 23 graph.get(pathMap.get(fi)).add(new Pair(flowerid, 16)); 24 int bi = 0; 25 for (int i = 1; i < p.size(); i++) { 26 bi = p.getNode(i); 27 if (!pathMap.containsKey(bi)) { 28 pathMap.put(bi, ++nodeId); 29 //++nodeNum; 30 flowerid = map.get(bi); 31 graph.get(flowerid).add(new Pair(pathMap.get(bi), 16)); 32 graph.get(pathMap.get(bi)).add(new Pair(flowerid, 16)); 33 } 34 int uv = Integer.max(p.getUnpleasantValue(fi), 35 p.getUnpleasantValue(bi));//调用开源接口中提供的getUnpleasantValue方法,不需要自行定义 36 graph.get(pathMap.get(fi)).add(new Pair(pathMap.get(bi), uv)); 37 graph.get(pathMap.get(bi)).add(new Pair(pathMap.get(fi), uv)); 38 fi = bi; 39 } 40 } 41 }
a.线性函数:
这个拆点之后边权都为1,所以也可以用bfs直接解决。
b.最小不满意度:
这个拆点之后边权不为1,所以用dijkstra。查询答案时用到了缓存的思想。
1 public int getAns(int from, int to) { 2 if (from == to) { 3 return 0; 4 } 5 int fro = map.get(from); 6 int go = map.get(to); 7 if (dis[fro][go] != -1) {//这里我用到了缓存的思想,如果dis==-1判断两点间的距离之前有无计算过,若计算过则直接取出,否则跑一边最短路。从隔壁os查找tlb学来的。 8 return dis[fro][go] - 32; 9 } 10 11 int[] dist = Dij(fro); 12 //System.out.println("nodeNum="+nodeNum); 13 for (int i = 1; i <= nodeNum; i++) {//无向边的小优化 14 dis[fro][i] = dist[i]; 15 dis[i][fro] = dist[i]; 16 } 17 return dis[fro][go] - 32;//由建图方法可知,跑最短路得到的结果会多算2个1/2的换乘代价,故询问答案时减去。 18 19 }
整体架构与容器选择:
为了方便,我对于上述四个问题开了四个类来分别计算。
GraphTable 用来完成基本的最短路的计算、联通块的计数。(gt)
private TransGraph g1; private PriceGraph g2; private PleaseGraph g3;
为了方便不同类间变量的传递,我没有想到更好的方法,所以写了一个不是那么oo的方式,把整个容器作为参数传递到需要用到它的地方..
保存图:用二维数组实现邻接链表
ArrayList<HashSet<Integer>> nodetoPaths;
因为:如果用前向星(边集数组),不方便用二维数组实现,并且操作较为复杂,所需定义的变量多,邻接链表足以本题满足复杂度的要求。
GraphTable graph[i][j] 与第i个点(i为离散化后点的编号)相连的第j个点的编号。 不采用静态数组,而采用动态存储的ArrayList,内层套hashset将重边化为同一条边。 我认为这里用hashset比大多数人用的hashmap要更好一点,因为不用存每个点出现的次数作为键值,每次执行增删操作时重构图维护两点间连通性,写起来更加简洁。
dis[i][j]: 保存经过离散化后id为i的点与j的点当前的最短路径长度 在每次bfs或者dijkstra时更新,在被查重的getShortestPathLength方法内部直接返回结果即可。 将初始值设置为-1,为了与两点间距离为0的情况区分开,也不用考虑MAX_INT带来的各种奇怪问题。因此可以通过disi==-1来判断两点间不连通。
map: 因为点的编号在int范围内很大,但是distinct的点的个数却很少,所以考虑将点离散化。 其实可以用hashmap套hashmap保存上面所说的graph,但是这里将离散化单独进行,一是为了确保编简洁性与正确性,二是因为在查找点时可以直接通过map来判断某点是否存在。
标程架构学习:
应用设计模式
关于类的设计
三、知识技能总结
JML是一种规范java语言的程序,使用前置、后置和不变量等等约束,形成一种契约式设计。JML作为java的注释可以写入源文件,并且可以使用openJML进行检查。通过JML的规约来检查代码静态、动态时候的正确性。 **语法** `requires` 定义了一个先决条件 `ensures` 定义了一个后置条件 `signals` 定义了后续方法抛异常时的后置条件 `assignable` 定义了允许继续执行了后面方法的条件 `pure` 声明一个方法是没有副作用的 `invariant` 定义了一个方法的不变的属性 ` esult` 定义了返回值需要满足的要求 `old(expression)` 用于表示进入方法之前表达式的值 `(forall <decl>; <range-exp>; <body-exp>)` 全称量词 `(exists <decl>; <range-exp>; <body-exp>)` 存在量词 `a==>b` a推出b `a<==b` a隐含b `a<==>b` a当且仅当b 以及,JML注释可以访问Java对象,方法和运算符。对象和方法对于JML有一定的可见性,同样可以通过关键字例如`spec_public`来规定。
1、JML语言的理论基础、应用工具链情况:
- pure方法
任何情况下,如果当前类或所依赖的类已经提供了相应pure方法, 则应直接使用相应方法来构造当前的方法规格
作业中的示例:
public /*@pure@*/ int getUnpleasantValue(Path path, int fromIndex, int toIndex); public /*@pure@*/int getDistinctNodeCount(); //在容器全局范围内查找不同的节点数
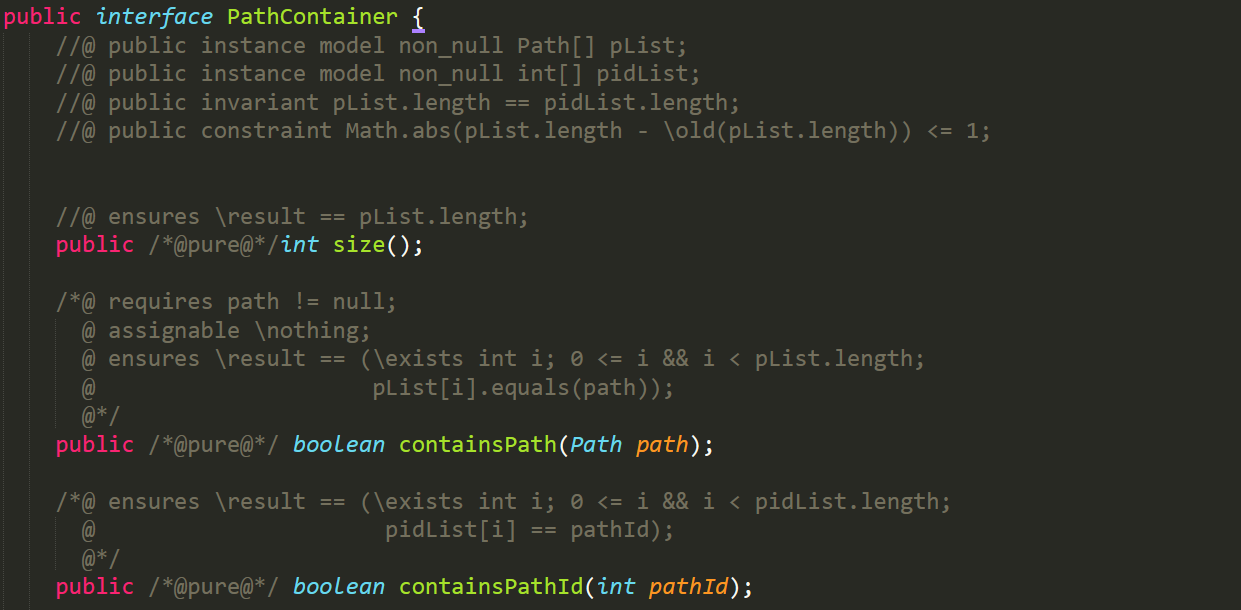
- 通过repOK来进行运行时检查:把不变式实现为一个判定方法
1 /*@ ensures: esult==invariant(this). 2 */ 3 IntSet: 4 public boolean repOK(){ 5 if(els == null) return false; //els <> null 6 for (int i=0; i<els.size();i++){ 7 Object x = els.get(i); 8 if(!(x instanceof Integer)) return false; //els[i] is an Integer 9 for(int j = i+1; j<els.size();j++) if(x.equals(els.get(j)))return false; //els[i] <>els[j] for i<j 10 } 11 return true; 12 }
子类的repOK应该调用父类的repOK来检查父类rep是否满足父类的不变式要求,并增加专属于子类的不变式检查逻辑
1 MaxIntSet{ 2 public boolean repOK(){ 3 int i; 4 boolean existed = false; 5 if (!super.repOK())return false; 6 for(int i=0;i<size();i++){ 7 if(biggest < getAt(i)) return false; 8 if(biggest == getAt(i)) existed = true; 9 } 10 if(i==0) return true; 11 return existed; 12 } 13 }
- LSP替换原则
在任何父类型对象出现的地方使用子类对象都不会破坏user程序的行为
- 迭代方法与生成器
Java提供的Iterator接口定义了三个操作
public Interface Iterator { public boolean hasNext(); public Object next() throws NoSuchElementException; public void remove() throws IllegalStateException, UnsupportedOperationException; }
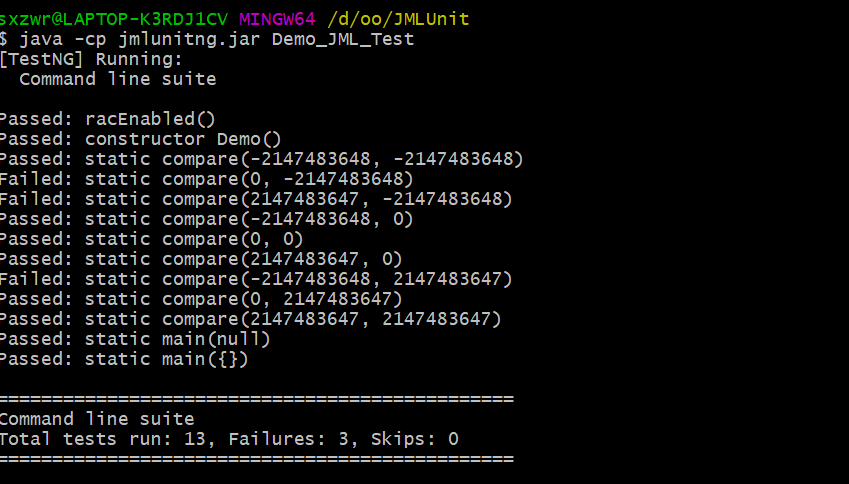
2、部署JMLUnitNG/JMLUnit,针对Graph接口的实现自动生成测试用例, 并结合规格对生成的测试用例和数据进行简要分析
我的执行过程与结果如下:

![]()

![]()
3、JUnit实现单元测试
我的研讨课课件,里面有单元测试的代码和测试过程,以及我对单元测试的理解:传送门
第一次作业单元测试程序的度量:
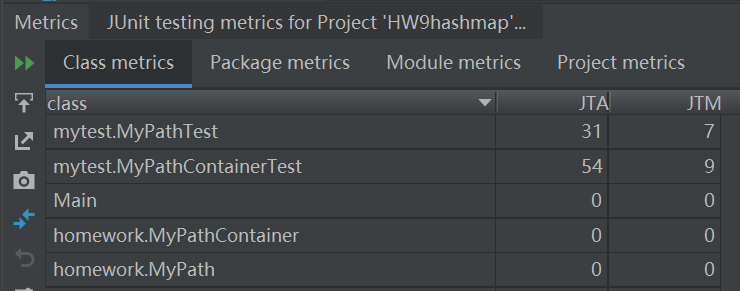
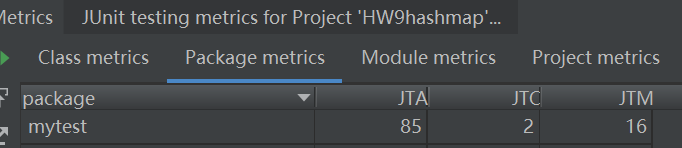
四、心得体会(自己的一些感性理解)
1、规格撰写: