一:冒泡排序
时间复杂度:O(n2)
原理:
(1):相邻元素互相比较 如果第一个比第二个大 就交换两者的位置
(2):对每一对邻居做比较 从头走到尾 即走了一趟 最后一位元素即为最大的元素
(3):针对所有的元素重复以上步骤 除了最后一个(因为最后的一位元素已经选出来了 为最大的元素 不需要再比较)
(4):持续每次对越来越少的元素重复上面的步骤,直到没有任何一对数字需要比较,最后数列就是从大到小一次排列
例如:


无序的序列:[54,26,93,17,77,31,44,55,20] 第一次比较,54>26,交换:26,54, 93,17,77,31,44,55,20 第二次比较,54<93,不处理:26,54, 93,17,77,31,44,55,20 第三次比较,93>17, 交换:26,54, 17,93, 77,31,44,55,20 第四次比较,93>77, 交换:26,54, 17, 77, 93, 31,44,55,20 第五次比较,93>31, 交换:26,54, 17, 77, 31,93, 44,55,20 第六次比较,93>44, 交换:26,54, 17, 77, 31, 44,93, 55,20 第七次比较,93>55, 交换:26,54, 17, 77, 31, 44, 55,93, 20 第八次比较,93>20, 交换:26,54, 17, 77, 31, 44, 55, 20,93 小结:1、最大的数93排在了队列的末尾 2、列表的长度n = 9,我们比较了n-1次 重复上面的过程: 26, 17,54, 31, 44, 55, 20, 77,93 小结:1、比较了n-2次 2、77放在了无序列表尾部 继续: 17, 26, 31, 44, 54, 20,55, 77,93 # 比较了 n-3 ,把55放在了无序列表的尾部 17, 26, 31, 44, 20, 54,55, 77,93 # 比较了 n-4 ,把54放在了无序列表的尾部 17, 26, 31, 20, 44, 54,55, 77,93 # 比较了 n-5 ,把54放在了无序列表的尾部 17, 26, 20, 31, 44, 54,55, 77,93 # 比较了 n-6 ,把31放在了无序列表的尾部 17, 20, 26, 31, 44, 54,55, 77,93 # 比较了 n-7 ,把26放在了无序列表的尾部 17, 20, 26, 31, 44, 54,55, 77,93 # 比较了 n-8 ,得到一个有序的序列 总结: 相邻元素两两比较把最大值排在无序序列尾部这个过程,要循环n-1
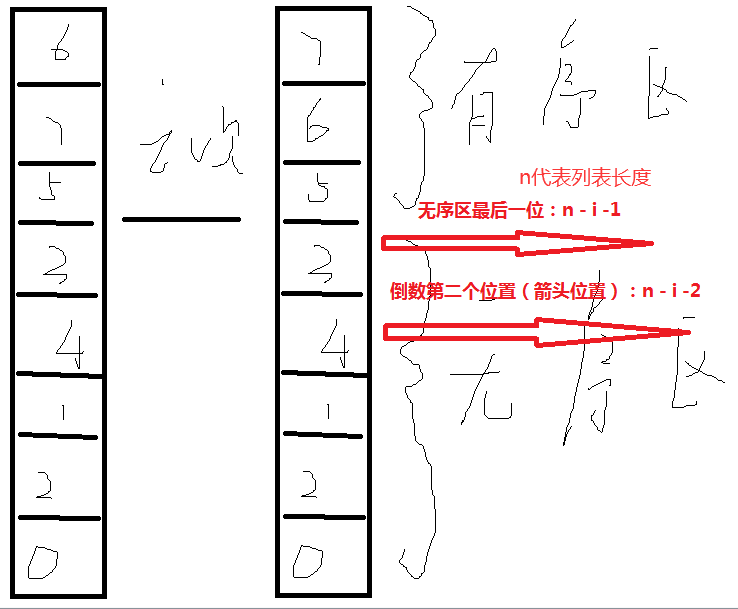
from cal_time import * import random @cal_time def bubble_sort(li): # li 传入的无序列表 for i in range(len(li) - 1): # i表示执行多少趟 for j in range(len(li) - i - 1): # 第i趟 无序区范围[0, n-i-1] j表示箭头即倒数第二个位置 0~n-i-2 n代表列表长度 if li[j] > li[ j + 1]: # 如果当前位置比邻居位置大 li[j] , li[j + 1] = li[j+1], li[j] return li li = list(range(100)) random.shuffle(li) print("pre:", li) bubble_sort(li) print("after:", li) 冒泡排序 冒泡排序
优化版本:当某一趟走完以后发现并没有进行数据交换,那么此时的数列已经排列好了,没有必要在进行下去。例如:极端情况下,数列本来已经排序好的,我们只需要走一趟即可完成排序。
from cal_time import * import random @cal_time def bubble_sort(li): # li 传入的无序列表 for i in range(len(li) - 1): # i表示执行多少趟 exchange = False # 交换标志 for j in range(len(li) - i - 1): # 第i趟 无序区范围[0, n-i-1] j表示箭头即倒数第二个位置 0~n-i-2 因为顾头不顾尾 因此范围为len - i - 1 n代表列表长度 if li[j] > li[ j + 1]: # 如果当前位置比邻居位置大 li[j] , li[j + 1] = li[j+1], li[j] exchange = True # 改变标志 if not exchange: return return li li = list(range(100)) random.shuffle(li) print("pre:", li) bubble_sort(li) print("after:", li) 优化版冒泡排序 优化版冒泡排序
二:选择排序
时间复杂度:O(n2)
原理:
(1)每次从列表中选出一个数作为比较的参数(最大或者最小),并且将其与其余数字进行比较
(2)若列表中的某个数字比选中的元素小 则二则交换位置
(3)依次将列表进行循环 选出最小的数 放在最左边
(4)重复上述步骤 直至完成排序
例如:
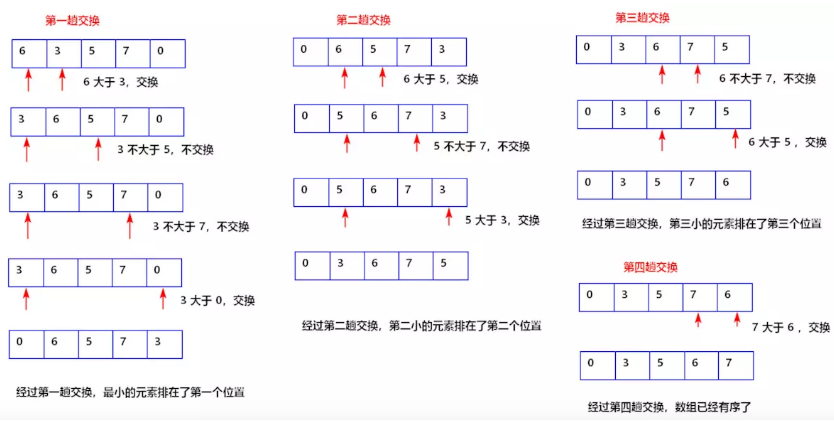
无序的序列:[54,26,93,17,77,31,44,55,20] 第一次,从无序序列中挑出一个最小值,放在有序序列的尾部: 17,54,26,93, 77,31,44,55,20 第二次,从无序序列中挑出一个最小值,放在有序序列的尾部: 17,20,54,26,93, 77,31,44,55 第三次,从无序序列中挑出一个最小值,放在有序序列的尾部: 17,20, 26,54, 93, 77,31,44,55 第四次,从无序序列中挑出一个最小值,放在有序序列的尾部: 17,20, 26, 31,54, 93, 77, 44,55 第五次,从无序序列中挑出一个最小值,放在有序序列的尾部: 17,20, 26, 31, 44,54, 93, 77, 55 第六次,从无序序列中挑出一个最小值,放在有序序列的尾部: 17,20, 26, 31, 44,54, 93, 77, 55 第七次,从无序序列中挑出一个最小值,放在有序序列的尾部: 17,20, 26, 31, 44,54, 55, 93, 77 第八次,从无序序列中挑出一个最小值,放在有序序列的尾部: 17,20, 26, 31, 44,54, 55, 77, 93
from cal_time import * import random # 选出最小元素的位置索引 def get_min_pos(li): min_position_index = 0 # 设置初始位置索引 for i in range(1, len(li)): # 循环列表 if li[i] < li[min_position_index]: # 比较循环出来的数值 与初始位置数值大小 min_position_index = i # 如果 循环出来的数值小于初始位置 则两则调换下位置 return min_position_index # 返回上述索引 @cal_time def select_sort(li): for i in range(len(li) - 1): # 循环n次或者n - 1次都可以 min_index = i # 记录循环开始最小的数值索引 # 此时无序区的范围为 [i - len(li)] 因为每次循环都会选出一个最小的放在最左边 下次开始在一个新的列表进行循环 for j in range(i + 1, len(li)): # 新的列表开始位置为i 自己不需要与自己比 因此从 i + 1开始进行计算 if li[j] < li[min_index]: # 比较初始索引值 与循环出来的值大小 min_index = j # 如果上述条件成立 则循环出来的数小于初始值数 因此换下位置 li[i], li[min_index] = li[min_index], li[i] # 最后进行位置互换 data_list = list(range(100)) random.shuffle(data_list) # 打乱列表数据 print("pre:", data_list) select_sort(data_list) print("after:", data_list)
三:插入排序
时间复杂度:O(n2)
原理:
(1):从第一个元素开始,该元素可以认为已经被排序
(2):取出下一个元素,在已经排序的元素序列中从后向前扫描
(3):如果被扫描的元素(已经排序元素)大于当前取出的元素 则将已经被扫描的元素向后挪
(4):重复步骤3,直到找到已排序的元素小于或者等于新元素的位置
(5):将新元素插入到该位置后
例如:
无序的序列:[54,26,93,17,77,31,44,55,20] 第一次插入:[20,54,26,93,17,77,31,44,55] 第二次插入:[20,54,55,26,93,17,77,31,44] 第三次插入:[20,44,54,55,26,93,17,77,31] 第四次插入:[20,31,44,54,55,26,93,17,77] 第五次插入:[20,31,44,54,55,77,26,93,17] 第六次插入:[17,20,31,44,54,55,77,26,93] 第七次插入:[17,20,31,44,54,55,77, 93,26] 第八次插入:[17,20,26,31,44,54,55,77, 93] 总结: 待排序序列元素数 : n 插入的次数: n-1

import random def insert_sort(li): for i in range( len(li) ): # 无序区域数据 temp = li[i] # 临时摸到的数字 j = i - 1 # 当前摸到的数字 左边的元素大小 while j >= 0 and li[j] > temp: # 保证左边的元素最起码有值 同时左边的元素大于当前摸到的数 li[j + 1] = li[j] # 当前的牌 与左边的牌换下位置 j = j - 1 # 然后j减去一 继续与有序区左边比 li[j + 1] = temp # 左边已经有序 右边为无序 即 左边有序去 + 1 data_list = list(range(30)) random.shuffle(data_list) # 打乱列表数据 print("pre:", data_list) insert_sort(data_list) print("after:", data_list)
四:快速排序
时间复杂度:平均O(nlogn)
原理:
(1):从数列中随机选取一个数作为基数
(2):使基数处于中间 比基数小的放在左边 比基数大的放在右边 与基数相等的放在左右都行
(3):递归完成上述操作 完成排序
例如:
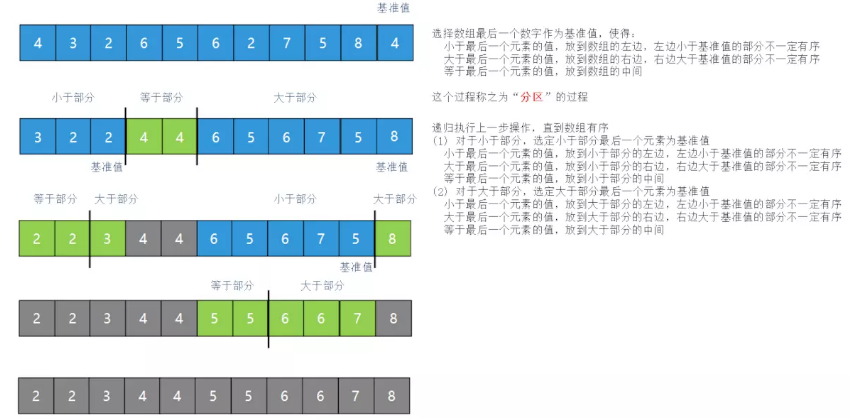
快速排序 无序的序列:[54,26,93,17,77,31,44,55,20] 第一次快速排序,那第一个元素54作为基准值,进行分割: [26,17,31,44,20,54, 93,77,55] 经过第一次分割排序,基准值左边的序列的所有元素都小于基准右边序列的所有元素 对54 左边的序列进行递归的分割: 拿26作为基准值,进行分割: [17,20,26, 31,44,54, 93,77,55] 对26 左边的序列进行递归的分割: 拿17作为基准值,进行分割: [17,20,26, 31,44,54, 93,77,55] 对17 右边的序列进行递归的分割: 右边序列只有一个元素20,不能在分割,返回 对26 右边的序列进行递归的分割: 拿31作为基准值,进行分割: [17,20,26, 31,44,54, 93,77,55] 31小于44,不处理 对54 右边的序列进行递归的分割: 拿93作为基准值,进行分割: [17,20,26, 31,44,54, 77, 55,93] 对93 右边的序列进行递归的分割: 拿77作为基准值,进行分割: [17,20,26, 31,44,54, 55, 77,93] 接下来,把整个序列进行排序: [17,20,26, 31,44,54, 55, 77,93]
import random def partition(li, left, right): ''' :param li: 排序的数组 :param left: 基数左边索引元素 :param right: 基数右边索引元素 :return: ''' temp = li[left] # 从左边选取一个基数 while left < right: while left < right and li[right] >= temp: # 右边小于左边 且右边值大于基数 right = right - 1 # 右边值大于基数 索引向向左边移动与基数比较 li[left] = li[right] # 此时左边有位置 将右边的元素移动到左边 while left < right and li[left] <= temp: # 判断左边值与基数的大小 left = left + 1 # 左边值小于基数 索引向右边移动继续与基数比较 li[right] = li[left] # 此时右边有位置 将左边的元素移动到右边 li[left] = temp # 将基数放到中间 return left # 返回基数索引 def quick_sort(li, left, right): ''' :param li: 排序的数组 :param left: 基数左边索引元素 :param right: 基数右边索引元素 :return: ''' if left < right: # 中止条件 排序区域至少 有两个元素 mid = partition(li, left, right) # 基数 quick_sort(li, left, mid - 1) # 循环排序基数左边 quick_sort(li, mid + 1, right) # 循环排序基数右边 if __name__ == '__main__': li = list(range(10)) random.shuffle(li) print("pre:", li) quick_sort(li,0,len(li) - 1) print("after:", li)
def quick_sort(li): if len(li) < 2: # 如果列表长度小于2 说明只有 0 或者1 一个元素没有办法比较 不需要再进行排序 return li temp = li[0] left = [v for v in li[1:] if v < temp] # 生成一个左边的列表 right = [v for v in li[1:] if v > temp] # 生成右边的列表 left = quick_sort(left) right = quick_sort(right) return left + [temp] + right # 进行拼凑
五:堆排序
堆:本质是一个完全二叉树 如果根节点的值是最小的值 则称之为小根堆 如果根节点的值为最大值 则称之为大根堆
时间复杂度:平均O(nlogn)
二叉树:度不超过二的数(节点最多有两个叉)

满二叉树:一个二叉树 每个节点都达到最大值

完全二叉树:叶节点只能出现在最下层和次下层 并且最下面一层的节点都集中在该层最左边的位置
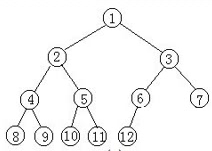
节点关系:

(1)父节点和左孩子节点索引关系
1:父节点(9)索引0 -----> 左边子节点(8)索引1 右边子节点(7)索引2 2:父节点(8)索引0 -----> 左边子节点(6)索引3 右边子节点(5)索引4 关系式: 父节点索引为i 左边子节点为 2 * i + 1 右边子节点为 2 * i + 2
子节点寻找父亲 (i - 1) // 2
原理:
(1):将待排序数据列表建立成堆结构(建立堆)
(2):通过上浮或者下沉等操作得到顶端最大的元素(大根堆为例)
(3):去掉顶部元素 将最后面的一个元素放到堆顶 再次进行调整 使得堆顶最大元素
(4):重复上述步骤 直到堆顶为空
import random def sift(li, low, high): temp = li[low] # 存放根节点 i = low # 根节点索引 j = 2 * i + 1 # 根节点对应左边孩子的索引 while j <= high: # j要小于最后一个元素 最后一个元素索引最大 如果大于high说明不在该堆 if j + 1 < high and li[j] < li[j + 1]: # 右节点必须有值 且比左节点大 j = j + 1 # 指向右节点 if li[j] > temp: # 比较当前元素与根节点大小 li[i] = li[j] # 当前节点大于根节点 则当前节点更改为根节点 i = j # 原来j的位置被更改为根节点 j = 2 * i + 1 else: # 否则说明本次 没有叶子节点大于根节点 结束循环 break li[i] = temp # 最后将被调整节点的值放到i节点上(空出的位置) def heap_sort(li): n = len(li) # 构造堆 for low in range((n - 2) // 2, -1, -1): ''' low:代表根节点 即最后一个元素的父节点 最后一个元素为n-1 带人到 (i-1)//2 可知根节点公式为(n - 2) // 2 到达-1 前包后不包 即到达最后一个位置 ''' sift(li, low, n - 1) # 挨个出数 for high in range(n - 1, -1, -1): ''' high : 代表最后一个元素 最后一个元素为n-1 ''' li[0], li[high] = li[high], li[0] # 将最后一个元素依次与根节点调换位置 sift(li, 0, high - 1) # 每次交换一个根节点 即high左边的为新的high data_list = list(range(100)) random.shuffle(data_list) # 打乱列表数据 print("pre:", data_list) heap_sort(data_list) print("after:", data_list)
六:归并排序
时间复杂度:O(nlogn)
原理:
(1):申请空间 使其大小为两个已经排序序列之和 该空间用来存放合并和的序列
(2):设定两个索引 最初位置都是为两个已经排序序列的起始位置
(3):比较两个指针所指向的元素,选择相对小的元素放入到合并空间,并移动指针到下一位置
(4):重复步骤3直到某一指针达到序列尾
(5):将另一序列剩下的所有元素直接复制到合并序列尾
import random def merger(li, low, mid, high): ''' :param li: 排序列表 :param low:列表开头位置 :param mid:中间分割 :param high:列表结束位置 :return: ''' i = low # 第一个列表开头索引 j = mid + 1 # 第二个列表开头索引 temp = [] while i <= mid and j <= high: # 分割列表有值才可以进行循环 if li[i] < li[j]: # 判断两个列表的首位大小 temp.append(li[i]) # 小的加入新的列表 i = i + 1 # 在原有的数值上 将索引右移 else: temp.append(li[j]) j = j + 1 while i <= mid: temp.append(li[i]) i = i + 1 # 在原有的数值上 将索引右移 while j <= high: # 左边分割有剩余 temp.append(li[j]) j = j + 1 li[low:high + 1] = temp # 最后将temp中的数写入到原来的列表中 def merger_sort(li,low,high): if low < high: # 至少有两个元素 mid = (low + high) // 2 merger_sort(li,low,mid) # 分割中间元素左边列表 merger_sort(li,mid + 1 ,high) # 分割中间元素右边列表 merger(li,low,mid,high) # 合并 data_list = list(range(100)) random.shuffle(data_list) # 打乱列表数据 print("pre:", data_list) merger_sort(data_list,0,len(data_list) - 1) print("after:", data_list)
def merger(l1,l2): ''' :param l1: 列表1 :param l2: 列表2 :return: ''' li = [] i = 0 j = 0 while i < len(l1) and j < len(l2): if l1[i] < l2[j]: li.append(l1[i]) i = i + 1 else: li.append(li[j]) j = j + 1 while i < len(l1): li.append(l1[i]) i = i + 1 while j < len(l2): li.append(l2[j]) j += 1 return li
七:希尔排序
原理:
(1):先选取一个小于n(列表长度)的整数d1作为第一个增量,所有的数据全部记录分组 把所有距离为d1倍数的数据放在一个组
(2):在各组内先进行排序
(3):取第二个增量d2<d1重复上述的分组和排序,直至所取的增量 =1( < …<d2<d1),即所有记录放在同一组中进行直接插入排序为止。
import random def shell_sort_gap(li,gap): n = len(li) for i in range(gap,n): temp = li[i] # 当前分割元素 j = i - gap # 当前分割元素左边位置 while j >= 0 and li[j] > temp: # 左边位置必须有值 且比当前分割元素大 li[j + gap] = li[j] # 则左边元素右移 j = j - gap # 继续比较左边元素 li[j + gap] = temp def shell_sort(li): gap = len(li) // 2 while gap > 0: shell_sort_gap(li,gap) gap = gap//2 data_list = list(range(100)) random.shuffle(data_list) # 打乱列表数据 print("pre:", data_list) shell_sort(data_list) print("after:", data_list)
PS:此排序比较鸡肋 比插入排序快 比快排慢
八:基数排序
时间复杂度:平均、最好、最坏都为O(k*n),其中k为常数,n为元素个数
原理:
(1):基数排序的思想就是先排序好个位,十位依次类推一直便利到最大位置 排序结束
(2):基数排序不是比较排序 而是通过分配和收集的过程来实现排序
(3):初始化是个捅(固定的) 下标记为0-9
(4):通过得到待排序的十百位数字 把这个数字放到对应的item中
import random def get_digit(num, i): ''' 输入0 ---> 拿到个位 输入1 ---> 拿到十位 一次类推 例如: num = 12345 i = 0 当i等于0的时候 10 ** i = 1 12345 整除1得到12345 在取余数得到5 即个位数 当i等于1的时候 10 ** i = 10 12345 整除10得到1234 在取余数得到4 即十位数 ''' return num // (10 ** i) % 10 def radix_sort(li): max_num = max(li) i = 0 while (10 ** i <= max_num): buckets = [[] for _ in range(10)] # 生成 0 - 9 的桶 for value in li: digit = value // (10 ** i) % 10 # 此代码看上面的函数 buckets[digit].append(value) # 将取出来的数字加入对应的桶中 li.clear() # 清空原表 for bucket in buckets: for value in bucket: li.append(value) i = i + 1 # 每次加一获取十位 百位 data_list = list(range(100)) random.shuffle(data_list) # 打乱列表数据 print("pre:", data_list) radix_sort(data_list) print("after:", data_list)