什么是垃圾回收?
程序的运行必然需要申请内存资源,无效的对象资源如果不及时处理就会一直占有内存资源,最终将导致内存溢出,所以对内存资源的管理非常重要。
垃圾回收就是对这些无效资源的处理,是对内存资源的管理。
垃圾回收的算法?
- 引用计数法
引用计数是历史最悠久的一种算法,最早George E. Collins在1960的时候首次提出,50年后的今天,该算法依然被很多编程语言使用。
- 原理
假设有一个对象A,任何一个对象对A的引用,那么对象A的引用计数器+1,当引用失败时,对象A的引用计数器就-1,如果对象A的计数器的值为0,就说明对象A没有引用了,可以被回收。
-
优缺点
优点:
实时性较高,无需等到内存不够的时候,才开始回收,
运行时根据对象的计数器是否为0,就可以直接回收。
在垃圾回收过程中,应用无需挂起。如果申请内存时,内存不足,则立刻报outofmember 内存溢出错误
区域性,更新对象的计数器时,只是影响到该对象,不会扫描全部对象。
缺点:
每次对象被引用时,都需要去更新计数器,有一点时间开销。
浪费CPU资源,即使内存够用,仍然在运行时进行计数器的统计,更新值浪费资源
无法解决循环引用问题。(最大的缺点)
-
标记清除法
-
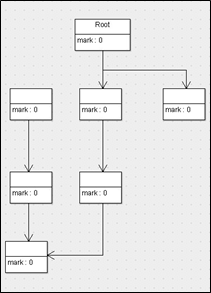
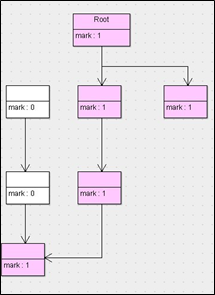
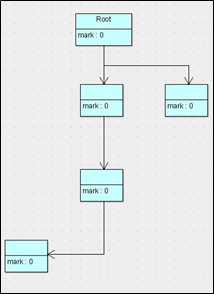
标记清除算法,是将垃圾回收分为2个阶段,分别是标记和清除。
- 标记:从根节点开始标记引用的对象。
- 清除:未被标记引用的对象就是垃圾对象,可以被清理
- 原理:
-
优缺点
- 优点
可以看到,标记清除算法解决了引用计数算法中的循环引用的问题,没有从root节点引用的对象都会被回收。
- 缺点:
效率较低,标记和清除两个动作都需要遍历所有的对象,并且在GC时,需要停止应用程序(有效内存耗尽时,JVM会停止应用程序的运行并开启GC线程,然后开始根据根搜索算法进行标记。标记需要遍历所有的对象,而对象一直动态变化,所以只能对某一个状态进行分析),对于交互性要求比较高的应用而言这个体验是非常差的。
通过标记清除算法清理出来的内存,碎片化较为严重,因为被回收的对象可能存在于内存的各个角落,所以清理出来的内存是不连贯的。
-
-
标记压缩算法
-
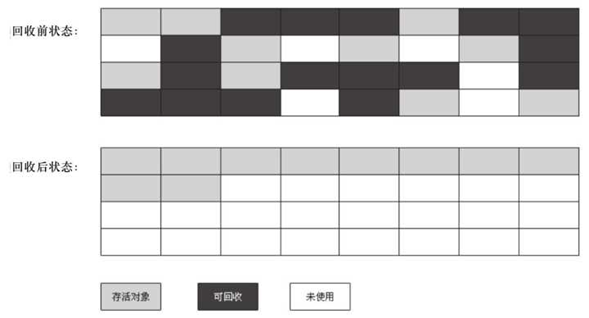
标记压缩算法是在标记清除算法的基础之上,做了优化改进的算法。和标记清除算法一样,也是从根节点开始,对对象的引用进行标记,在清理阶段,并不是简单的清理未标记的对象,而是将存活的对象压缩到内存的一端,然后清理边界以外的垃圾,从而解决了碎片化的问题。
- 原理
-
-
优缺点
- 优缺点同标记清除算法,解决了标记清除算法的碎片化的问题,同时,标记压缩算法多了一步,对象移动内存位置的步骤,其效率也有有一定的影响
-
复制算法
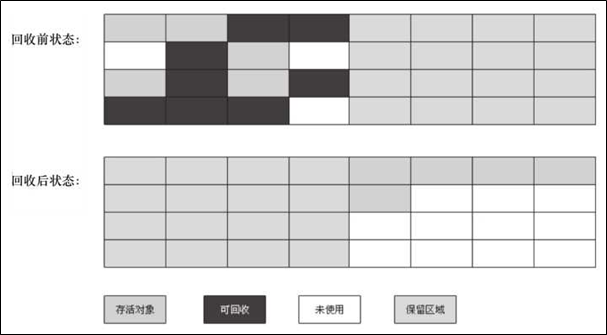
- 复制算法的核心就是,将原有的内存空间一分为二,每次只用其中的一块,在垃圾回收时,将正在使用的对象复制到另一个内存空间中,然后将该内存空间清空,交换两个内存的角色,完成垃圾的回收。
- 如果内存中的垃圾对象较多,需要复制的对象就较少,这种情况下适合使用该方式并且效率比较高。反之,则不适合。
-
JVM中年轻代内存(原理:复制算法)
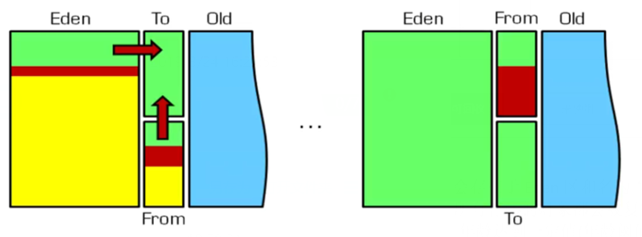
- 在GC开始的时候,对象只会存在于Eden区和名为"From"的Survivor区,Survivor区"To"是空的。
- 紧接着进行GC,Eden区中所有存活的对象都会被复制到"To",而在"From"区中,仍存活的对象会根据他们的年龄值来决定去向。年龄达到一定值(年龄阈值,可以通过-XX:MaxTenuringThreshold来设置)的对象会被移动到年老代中,没有达到阈值的对象会被复制到"To"区域,垃圾对象会停留。
- 经过这次GC后,Eden区和From区已经被清空。这个时候,"From"和"To"会交换他们的角色,也就是新的"To"就是上次GC前的"From",新的"From"就是上次GC前的"To"。不管怎样,都会保证名为To的Survivor区域是空的。
- GC会一直重复这样的过程,直到"To"区被填满,"To"区被填满之后,会将所有对象移动到年老代中。
-
优缺点
-
优点:
在垃圾对象多的情况下,效率较高(存活对象少,就复制的少,直接清空)
清理后,内存无碎片
-
缺点:
在垃圾对象少的情况下,不适用,如:老年代内存
分配的2块内存空间,在同一个时刻,只能使用一半,内存使用率较低
-
-
分代算法
- 前面介绍了多种回收算法,每一种算法都有自己的优点也有缺点,谁都不能替代谁,所以根据垃圾回收对象的特点进行选择,才是明智的选择。
- 分代算法其实就是这样的,根据回收对象的特点进行选择,在jvm中,年轻代(存在时间短,垃圾多)适合使用复制算法,老年代(存活的长的多,垃圾少)适合使用标记清除(碎片多,更快)或标记压缩算法(碎片少,更慢)
垃圾收集器
垃圾收集器,就是垃圾回收算法的具体实现。Jvm中垃圾收集器有很多的种类。
|
public class TestGC { /** * 不断产生新的对象,并随机的销毁(产生垃圾) */ public static void main(String[] args) { List<Object> list = new ArrayList<Object>(); while (true) { int sleep = new Random().nextInt(100);//随机产生100以内的数字 if (System.currentTimeMillis() % 2 == 0) { //当前时间戳是偶数 list.clear();//list的clear就是遍历集合元素,将其指向null } else { //为奇数 for (int i = 0; i < 10000; i++) { Properties properties = new Properties(); properties.put("key_" + i, "value_" + System.currentTimeMillis() + i); list.add(properties); } } try { Thread.sleep(sleep); } catch (Exception e) { e.printStackTrace(); } } } } |
-
串行垃圾收集器
- 串行垃圾收集器,是指使用单线程进行垃圾回收,垃圾回收时,只有一个线程在工作,并且java应用中的所有线程都要暂停,等待垃圾回收的完成。这种现象称之为STW(Stop-The-World)。
- 对于交互性较强的应用而言,这种垃圾收集器是不能够接受的。
- 一般在Javaweb应用中是不会采用该收集器的
|
java -XX:+UseSerialGC -XX:+PrintGCDetails -Xms16m -Xmx16m cn.lky.gc.TestGC |
|
[GC (Allocation Failure) [DefNew: 4927K->511K(4928K), 0.0063194 secs] 11935K->9964K(15872K), 0.0065987 secs] [Times: user=0.02 sys=0.00, real=0.01 secs] [GC (Allocation Failure) [DefNew: 4927K->4927K(4928K), 0.0001924 secs][Tenured: 9452K->6549K(10944K), 0.0146686 secs] 14380K->6549K(15872K), [Metaspace: 2786K->2786K(1056768K)], 0.0160833 secs] [Times: user=0.01 sys=0.00, real=0.02 secs] [Full GC (Allocation Failure) [Tenured: 10943K->10943K(10944K), 0.0210919 secs] 15871K->14689K(15872K), [Metaspace: 2793K->2793K(1056768K)], 0.0217457 secs] [Times : user=0.02 sys=0.00, real=0.02 secs] [GC(垃圾回收的原因,Allocation Failure分配失败)] |
GC日志信息解读:
年轻代的内存GC前后的大小:
-
DefNew
- 表示使用的是串行垃圾收集器。
-
4416K->512K(4928K)
- 表示,年轻代GC前,占有4416K内存,GC后,占有512K内存,总大小4928K
-
0.0046102 secs
- 表示,GC所用的时间,单位为毫秒。
-
4416K->1973K(15872K)
- 表示,GC前,堆内存占有4416K,GC后,占有1973K,总大小为15872K
-
Full GC
- 表示,内存空间全部进行GC(年轻代、老年代、元数据全部做垃圾回收)
-
并行垃圾收集器
- 并行垃圾收集器在串行垃圾收集器的基础之上做了改进,将单线程改为了多线程进行垃圾回收,这样可以缩短垃圾回收的时间。(这里是指,并行能力较强的机器)
- 当然了,并行垃圾收集器在收集的过程中也会暂停应用程序(STW),这个和串行垃圾回收器是一样的,只是并行执行,速度更快些,暂停的时间更短一些
-
ParNew垃圾收集器(并行垃圾收集器)
- ParNew垃圾收集器是工作在年轻代上的,只是将串行的垃圾收集器改为了并行。
- 通过-XX:+UseParNewGC参数设置年轻代使用ParNew回收器,老年代使用的依然是串行收集器。
|
java -XX:+UseParNewGC -XX:+PrintGCDetails -Xms16m -Xmx16m cn.lky.gc.TestGC |
|
[GC (Allocation Failure) [ParNew: 4928K->512K(4928K), 0.0037657 secs] 11768K->9834K(15872K), 0.0041742 secs] [Times: user=0.00 sys=0.00, real=0.01 secs] [GC (Allocation Failure) [ParNew: 4928K->4928K(4928K), 0.0001995 secs][Tenured: 9322K->6778K(10944K),0.0141677 secs] 14250K->6778K(15872K), [Metaspace: 2786K->2786K(1056768K)], 0.0153509 secs] [Times: user=0.01 sys=0.00, real=0.02 secs] [Full GC (Allocation Failure) [Tenured: 10943K->10943K(10944K), 0.0312995 secs] 15871K->14892K(15872K), [Metaspace: 2793K->2793K(1056768K)], 0.0321568 secs] [Times : user=0.03 sys=0.00, real=0.03 secs] |
ParNew: 使用的是ParNew收集器。其他信息和串行收集器一致。
-
ParallelGC垃圾收集器(并行垃圾收集器)
- ParallelGC收集器工作机制和ParNewGC收集器一样,只是在此基础之上,新增了两个和系统吞吐量相关的参数,使得其使用起来更加的灵活和高效。
-
相关参数如下:
-
-XX:+UseParallelGC
- 年轻代使用ParallelGC垃圾回收器,老年代使用串行回收器。
-
-XX:+UseParallelOldGC
- 年轻代使用ParallelGC垃圾回收器,老年代使用ParallelOldGC垃圾回收器(ParallerGC并行收集器)。
-
-XX:MaxGCPauseMillis
- 设置最大的垃圾收集时的停顿时间,单位为毫秒
- 需要注意的是,ParallelGC为了达到设置的停顿时间,可能会调整堆大小或其他的参数,如果堆的大小设置的较小,就会导致GC工作变得很频繁,反而可能会影响到性能。
- 该参数使用需谨慎。
-
-XX:GCTimeRatio不常用
- 设置垃圾回收时间占程序运行时间的百分比,公式为1/(1+n)。
- 它的值为0~100之间的数字,默认值为99,也就是垃圾回收时间不能超过1%
-
-XX:UseAdaptiveSizePolicy不常用
- 自适应GC模式,垃圾回收器将自动调整年轻代、老年代等参数,达到吞吐量、堆大小、停顿时间之间的平衡。
- 一般用于,手动调整参数比较困难的场景,让收集器自动进行调整
-
|
java -XX:+UseParallelGC -XX:+UseParallelOldGC -XX:MaxGCPauseMillis=100 -XX:+PrintGCDetails -Xms16m -Xmx16m cn.lky.gc.TestGC |
|
[GC (Allocation Failure) [PSYoungGen: 3456K->1440K(3584K)] 12369K->11697K(14848K), 0.0030692 secs] [Times: user=0.00 sys=0.00, real=0.00 secs] [Full GC (Ergonomics) [PSYoungGen: 1440K->0K(3584K)] [ParOldGen: 10257K->7438K(11264K)] 11697K->7438K(14848K), [Metaspace: 2792K->2792K(1056768K)], 0.0256233 secs] [Times: user=0.20 sys=0.00, real=0.03 secs] |
以上信息可以看出,年轻代和老年代都使用了ParallelGC垃圾回收器
CMS垃圾收集器
- 串行、并行垃圾收集器都会进行暂停(并行只是短),但CMS解决了停顿问题,垃圾回收时程序也能继续执行
- CMS全称 Concurrent Mark Sweep,是一款并发的、使用标记-清除算法的垃圾回收器,
- 该回收器是针对老年代垃圾回收的(默认ParNew),通过参数-XX:+UseConcMarkSweepGC进行设置。
-
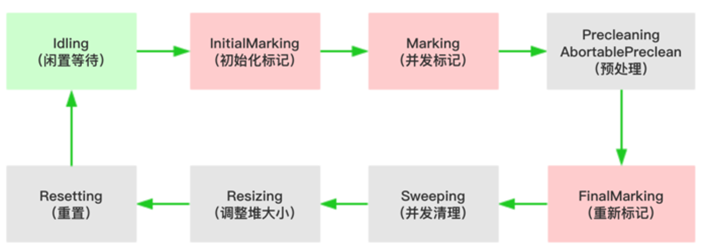
CMS垃圾回收器的执行过程如下:
- 初始化标记(CMS-initial-mark) ,标记root,会导致stw;
- 并发标记(CMS-concurrent-mark),与用户线程同时运行;
- 预清理(CMS-concurrent-preclean),与用户线程同时运行;
- 重新标记(CMS-remark) ,最终标记会标记过程中新的对象,会导致stw;
- 并发清除(CMS-concurrent-sweep),与用户线程同时运行;
- 调整堆大小,设置CMS在清理之后进行内存压缩,目的是清理内存中的碎片;
- 并发重置状态等待下次CMS的触发(CMS-concurrent-reset),与用户线程同时运行
|
java -XX:+UseConcMarkSweepGC -XX:+PrintGCDetails -Xms16m -Xmx16m cn.lky.gc.TestGC |
|
#运行日志 [GC (Allocation Failure) [ParNew: 4928K->512K(4928K), 0.0055245 secs] 9083K->7112K(15872K), 0.0060417 secs] [Times: user=0.00 sys=0.00, real=0.01 secs] #第一步,初始标记 [GC (CMS Initial Mark) [1 CMS-initial-mark: 6600K(10944K)] 7200K(15872K), 0.0017557 secs] [Times: user=0.00 sys=0.00, real=0.00 secs] #第二步,并发标记 [CMS-concurrent-mark-start] [CMS-concurrent-mark: 0.001/0.001 secs] [Times: user=0.02 sys=0.00, real=0.00 secs] #第三步,预处理 [CMS-concurrent-preclean-start] [CMS-concurrent-preclean: 0.000/0.000 secs] [Times: user=0.00 sys=0.00, real=0.00 secs] #同上,此阶段的目的是使cms gc更加可控一些,作用也是执行一些预清理,以减少下一个stw阶段(最终标记)造成应用暂停的时间 [CMS-concurrent-abortable-preclean-start] #当cms gc进行时,此时有新的对象要进入old代,但是old代空间不足造成的整个应用暂停(fullGC) (concurrent mode failure): 9081K->3100K(10944K), 0.0112849 secs] 14009K->3100K(15872K), [Metaspace: 2787K->2787K(1056768K)], 0.0128308 secs] [Times: user=0.02 sys=0.00, real=0.01 secs] #第四步,最终标记 [GC (CMS Final Remark) [YG occupancy: 3428 K (4928 K)][Rescan (parallel) , 0.0007407 secs][weak refs processing, 0.0000387 secs][class unloading, 0.0002319 secs][scrub symbol table, 0.0004188 secs][scrub string table, 0.0001608 secs][1 CMS-remark: 6910K(10944K)] 10339K(15872K), 0.0042667 secs] [Times: user=0.00 sys=0.00, real=0.00 secs] #第五步,并发清理 [CMS-concurrent-sweep-start] [CMS-concurrent-sweep: 0.004/0.004 secs] [Times: user=0.00 sys=0.00, real=0.00 secs] #第六步,重置 [CMS-concurrent-reset-start] [CMS-concurrent-reset: 0.000/0.000 secs] [Times: user=0.00 sys=0.00, real=0.00 secs] |
|
有2种情况会触发full gc,在full gc时,整个应用会暂停
|
G1垃圾收集器
- G1垃圾收集器是在jdk1.7中正式使用的全新的垃圾收集器,oracle官方计划在jdk9中将G1变成默认的垃圾收集器,以替代CMS
-
G1的设计原则就是简化JVM性能调优,开发人员只需要简单的三步即可完成调优:
1. 第一步,开启G1垃圾收集器
2. 第二步,设置堆的最大内存
3. 第三步,设置最大的停顿时间
-
G1中提供了三种模式垃圾回收模式,Young GC、Mixed GC 和 Full GC,在不同的条件下被触发。
-
原理
G1垃圾收集器相对比其他收集器而言,最大的区别在于它取消了年轻代、老年代的物理划分,取而代之的是将堆划分为若干个区域(Region),这些区域中包含了有逻辑上的年轻代、老年代区域。
这样做的好处就是,我们再也不用单独的空间对每个代进行设置了,不用担心每个代内存是否足够

在G1划分的区域中,年轻代的垃圾收集依然采用暂停所有应用线程的方式,将存活对象拷贝到老年代或者Survivor空间,G1收集器通过将对象从一个区域复制到另外一个区域,完成了清理工作。(复制算法,完成垃圾回收同时还进行了内存压缩)
这就意味着,在正常的处理过程中,G1完成了堆的压缩(至少是部分堆的压缩),这样也就不会有cms内存碎片问题的存在了。
在G1中,有一种特殊的区域,叫Humongous区域。如果一个对象占用的空间超过了分区容量50%以上,G1收集器就认为这是一个巨型对象。
这些巨型对象,默认直接会被分配在老年代,但是如果它是一个短期存在的巨型对象,就会对垃圾收集器造成负面影响。为了解决这个问题,G1划分了一个Humongous区,它用来专门存放巨型对象。如果一个H区装不下一个巨型对象,那么G1会寻找连续的H分区来存储。为了能找到连续的H区,有时候不得不启动Full GC
Young GC
- Young GC主要是对Eden区进行GC,它在Eden空间耗尽时会被触发。
- Eden空间的数据移动到Survivor空间中,如果Survivor空间不够,Eden空间的部分数据会直接晋升到年老代空间。
- Survivor区的数据移动到新的Survivor区中,也有部分数据晋升到老年代空间中。最终Eden空间的数据为空,GC停止工作,应用线程继续执行。
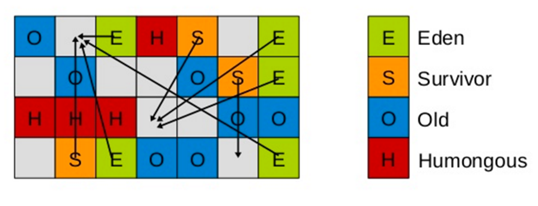
Remembered Set(已记忆集合)
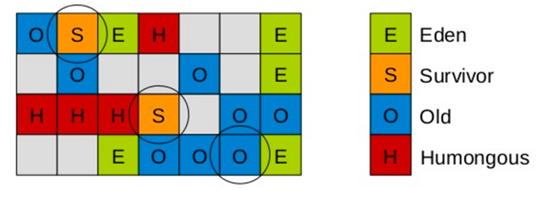
- 在GC年轻代的对象时,我们如何找到年轻代中对象的根对象呢?
- 根对象可能是在年轻代中,也可以在老年代中,那么老年代中的所有对象都是根么?不一定,根年轻代、老年代都有可能。
- 如果全量扫描老年代,那么这样扫描下来会耗费大量的时间。
- 于是,G1引进了RSet的概念。它的全称是Remembered Set,其作用是跟踪指向某个堆内的对象引用。
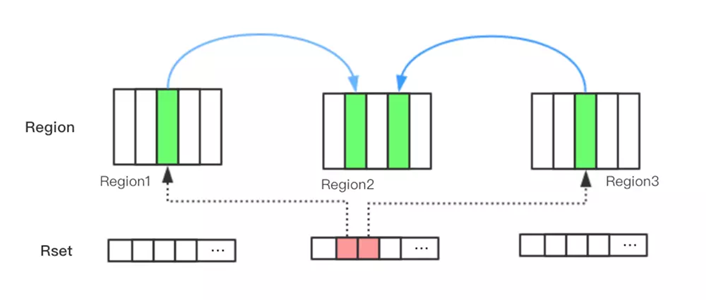
- 每个Region初始化时,会初始化一个RSet,该集合用来记录并跟踪其它Region指向该Region中对象的引用,每个Region默认按照512Kb划分成多个Card,所以RSet需要记录的东西应该是 xx Region的 xx Card。
Mixed GC
- 当越来越多的对象晋升到老年代old region时,为了避免堆内存被耗尽,虚拟机会触发一个混合的垃圾收集器,即Mixed GC,该算法并不是一个Old GC,除了回收整个Young Region,还会回收一部分的Old Region。
- 这里需要注意:是一部分老年代,而不是全部老年代,可以选择哪些old region进行收集,从而可以对垃圾回收的耗时时间进行控制。
- 也要注意的是Mixed GC 并不是 Full GC。
- MixedGC什么时候触发? 由参数 -XX:InitiatingHeapOccupancyPercent=n 决定。默认:45%,该参数的意思是:当老年代大小占整个堆大小百分比达到该阀值时触发。
- 它的GC步骤分2步:
1. 全局并发标记(global concurrent marking)
2. 拷贝存活对象(evacuation)
全局并发标记(只是标记,并没有对垃圾进行处理)
-
全局并发标记,执行过程分为五个步骤:
- 初始标记(initial mark,STW)
标记从根节点直接可达的对象,这个阶段会执行一次年轻代GC,会产生全局停顿。
- 根区域扫描(root region scan)
G1 GC 在初始标记的存活区扫描对老年代的引用,并标记被引用的对象。
该阶段与应用程序(非 STW)同时运行,并且只有完成该阶段后,才能开始下一次 STW 年轻代垃圾回收。
- 并发标记(Concurrent Marking)
G1 GC 在整个堆中查找可访问的(存活的)对象。该阶段与应用程序同时运行,可以被 STW 年轻代垃圾回收中断。
- 重新标记(Remark,STW)
该阶段是 STW 回收,因为程序在运行,针对上一次的标记进行修正。
- 清除垃圾(Cleanup,STW)
清点和重置标记状态,该阶段会STW,这个阶段并不会实际上去做垃圾的收集,等待evacuation阶段来回收。
拷贝存活对象(这个阶段才是垃圾处理)
- Evacuation阶段是全暂停的。该阶段把一部分Region里的活对象拷贝到另一部分Region中,从而实现垃圾的回收清理
G1收集器相关参数
-
-XX:+UseG1GC
- 使用 G1 垃圾收集器
-
-XX:MaxGCPauseMillis
- 设置期望达到的最大GC停顿时间指标(JVM会尽力实现,但不保证达到),默认值是 200 毫秒。
-
-XX:G1HeapRegionSize=n
- 设置的 G1 区域的大小。值是 2 的幂,范围是 1 MB 到 32 MB 之间。目标是根据最小的 Java 堆大小划分出约 2048 个区域。
- 默认是堆内存的1/2000。
-
-XX:ParallelGCThreads=n
- 设置 STW 工作线程数的值。将 n 的值设置为逻辑处理器的数量。n 的值与逻辑处理器的数量相同,最多为 8。
-
-XX:ConcGCThreads=n
- 设置并行标记的线程数。将 n 设置为并行垃圾回收线程数 (ParallelGCThreads)的 1/4 左右。
-
-XX:InitiatingHeapOccupancyPercent=n
- 设置触发标记周期的 Java 堆占用率阈值。默认占用率是整个 Java 堆的 45%。
|
java -XX:+UseG1GC -XX:MaxGCPauseMillis=100 -XX:+PrintGCDetails -Xmx256m cn.lky.gc.TestGC |
|
#日志 [GC pause (G1 Evacuation Pause) (young), 0.0063506 secs]#youngGC还有mixedGC等 [Parallel Time: 4.7 ms, GC Workers: 8] [GC Worker Start (ms): Min: 170418.4, Avg: 170418.5, Max: 170418.6, Diff: 0.2] #扫描根节点 [Ext Root Scanning (ms): Min: 0.0, Avg: 0.1, Max: 0.2, Diff: 0.2, Sum: 1.0] #更新RS区域所消耗的时间(已记忆集合) [Update RS (ms): Min: 0.0, Avg: 0.3, Max: 1.9, Diff: 1.9, Sum: 2.5] [Processed Buffers: Min: 1, Avg: 1.3, Max: 2, Diff: 1, Sum: 10] [Scan RS (ms): Min: 0.0, Avg: 0.0, Max: 0.0, Diff: 0.0, Sum: 0.1] [Code Root Scanning (ms): Min: 0.0, Avg: 0.0, Max: 0.0, Diff: 0.0, Sum: 0.0] #对象拷贝 [Object Copy (ms): Min: 2.3, Avg: 3.9, Max: 4.1, Diff: 1.8, Sum: 30.9] [Termination (ms): Min: 0.0, Avg: 0.0, Max: 0.0, Diff: 0.0, Sum: 0.0] [Termination Attempts: Min: 1, Avg: 1.4, Max: 2, Diff: 1, Sum: 11] [GC Worker Other (ms): Min: 0.0, Avg: 0.0, Max: 0.0, Diff: 0.0, Sum: 0.2] [GC Worker Total (ms): Min: 4.2, Avg: 4.3, Max: 4.4, Diff: 0.2, Sum: 34.7] [GC Worker End (ms): Min: 170422.8, Avg: 170422.8, Max: 170422.8, Diff: 0.0] [Code Root Fixup: 0.0 ms] [Code Root Purge: 0.0 ms] [Clear CT: 0.6 ms]#清空CardTable [Other: 1.0 ms] [Choose CSet: 0.0 ms] #选取CSet [Ref Proc: 0.4 ms]#弱引用、软引用的处理耗时 [Ref Enq: 0.0 ms]#弱引用、软引用的入队耗时 [Redirty Cards: 0.4 ms] [Humongous Register: 0.0 ms]#大对象区域注册耗时 [Humongous Reclaim: 0.0 ms]#大对象区域回收耗时 [Free CSet: 0.0 ms] [Eden:67.0M(67.0M)->0.0B(63.0M)Survivors:4096.0K->7168.0KHeap:106.5M(126.0M)->42.3M(12 6.0M)] #年轻代的大小统计 [Times: user=0.00 sys=0.00, real=0.02 secs] |
G1垃圾收集器优化建议
-
年轻代大小(不存在物理划分)
- 避免使用 -Xmn 选项或 -XX:NewRatio 等其他相关选项显式设置年轻代大小。
-
固定年轻代的大小会覆盖暂停时间目标。
-
暂停时间目标不要太过严苛(默认200ms)
- G1 GC 的吞吐量目标是 90% 的应用程序时间和 10%的垃圾回收时间。
- 评估 G1 GC 的吞吐量时,暂停时间目标不要太严苛。目标太过严苛表示你愿意承受更多的垃圾回收开销,而这会直接影响到吞吐量
GC Easy -可视化GC日志分析工具
-
前面通过-XX:+PrintGCDetails可以对GC日志进行打印,我们就可以在控制台查看,这样虽然可以查看GC的信息,但是并不直观,可以借助于第三方的GC日志分析工具进行查看。
-
在日志打印输出涉及到的参数如下:
- ‐XX:+PrintGC 输出GC日志
- ‐XX:+PrintGCDetails 输出GC的详细日志
- ‐XX:+PrintGCTimeStamps 输出GC的时间戳(以基准时间的形式)
- ‐XX:+PrintGCDateStamps 输出GC的时间戳(以日期的形式,如 2013‐05‐04T21:53:59.234+0800)
- ‐XX:+PrintHeapAtGC 在进行GC的前后打印出堆的信息
- ‐Xloggc:../logs/gc.log 日志文件的输出路径
|
java -XX:+UseG1GC -XX:MaxGCPauseMillis=100 -Xmx256m -XX:+PrintGCDetails -XX:+PrintGCTimeStamps -XX:+PrintGCDateStamps -XX:+PrintHeapAtGC -Xloggc:D://WorkSpaces//IDEAworkspace//JVM_base//cnlkyjvm//src//main//log//lkygc.log TestGC |
然后,去http://gceasy.io/ 网站上传你的.log文件进行分析
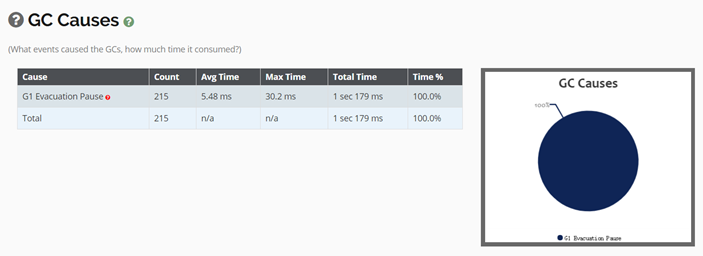
堆的内存分析:

GC吞吐量(90%就达标了)
暂停时间

像fullGC GC原因都是很重要的部分,如下图内容就是大量对象拷贝(youngGC和mixedGC)导致的GC