先看一下Buffer的定义或由来,曾经Node.js的官网上对Buffer有过这么一段解释
Prior to the introduction of TypedArray, the JavaScript language had no mechanism for reading or manipulating streams of binary data. The Buffer class was introduced as part of the Node.js API to enable interaction with octet streams in TCP streams, file system operations, and other contexts.
翻译一下,在typedArray类型出现之前,JavaScript并没有机制来读取或操作二进制数据流。为了能够在文件系统操作,TCP流等操作中和二进制数据流进行交互,Buffer类创建出来了。Buffer是用来和二进制数据流进行交互的。两个概念,二进制数据和流。
二进制数据,好理解一点,计算机中的所有数据都是以二进制形式存储在计算机中的。无论是数字,字符,还是图片等,在进行存储之前,都要先把它们转化成对应的二进制表现形式,然后才能进行存储。所以为了存储数据,计算机需要做的第一个事情就是把数据转化成它们的二进制表现形式。数字很好转化,因为是纯数学计算,十进制转化成二进制,就是除2取余,12 就转换成1100. 计算机中内嵌了这种计算,它自己能够很好地完成数字之间进制的转化。
但计算机中不仅只有数字,还有字符,图片,视频等。就拿字符来说吧,它要怎么才能转化成二进制呢?只能先把字符转化成数字,再把数字转化成它的二进制表现形式。字符转化成数字,就要规定哪一个字符对应哪一个数字,这就用到字符集(unicode), 比如unicode 和 ASCII, 它们都规定了字符和数字的一一对应关系。找到了对应的数字,就要数字转化成它的二进制表现形式,但到底用几个字节为表示一个数字呢?这就是字符编码(UTF-8, UTF-16)的由来。比如UTF-8就规定用一个字节来表示一个英文字符。同理,图片,视频,音频也都是有一些特定的规则来确定它们成功地转换成二进制。
Buffer中的二进制强调的就是所有数据都是以二进制形式存储到计算机中的,计算机中的所有数据都是二进制数据,它们在计算机中表现形式全都是0101010101010的组合。
流,简单一点,就是数据的流动,数据从一个地方流到另外一个地方。二进制数据流就是二进制数据从一个地方流到另外一个地方。这就很好理解了,因为计算机中的所有数据都是二进制数据,计算机中的操作都是二进制数据的流动。比如文件的复制,就是二进制数据从一个文件流到另外一个文件。复杂一点,就是数据从一个地方流到另外一个地方的过程中,是分块进行的。还是文件复制的例子,在文件复制的过程中,并不是把一个文件中的所有内容都复制完成,再拷贝到另外一个文件,而是先复制一部分数据到另外一个文件,再复制一部分到另外一个文件,直到整个文件复制完成。在整个数据流动的过程中,数据被分割成一块一块的(chunk),分批发送,接收者,也是一块数据一块数据地进处理。这样做有个好处就是提高效率,如果一个流(文件)中包含大量的数据,我们不用等到所有的数据都获取完毕才开始处理,可以先发送一部分,处理一部分,再发送一部分,处理一部分,还节省内存,因为只开辟这一部分的内存。
二进制数据和流都说完了,现在终于轮到Buffer了。Buffer 是怎么和二进制数据流进行交互的呢?或者说,在二进制数据流动的过程中,Buffer到底起到了什么作用?一般来说,数据在流动的过程中,我们通常都会做点什么,比如读和写。读文件,就是把文件数据读取到内存中(文件数据流向内存中),这时可以对文 件进行处理,比如把文 件中的小写字母转成大写字母。数据在读取(流动)的过程中,流会发送一块数据过来,数据读取有可能很慢,所以有可能发送的过来数据太少,假设是1kb,你说cpu 要不要处理,把这些数据转化成大写字母?很可能不会处理,数据太少了,达不到它的处理要求。写文件则相反,数据从内存中流向文件中,由于数据本来就在内存中,流能够一次发送大量的数据到文件中, 比10M, 但文件的写操作也慢,很可以一次处理不了这么多的数据。 多余的数据怎么办?数据太少了不处理,数据太多了又处理不了,正是由于这些目的地(destination)存在着对数据处理数量的最大值最小值的限制,我们需要一个地方把数据存起来,这个地方就是buffer. 数据发送过来的太少,我们就把这些先到的数据存在buffer 中,等下一次发送过来的数据,两者相加,看能不能达到最小数据的要求,如果能,就全部发送给cpu进行处理,如果不能,还是把数据放到buffer中,再等下一次发送过来的数据,直到达到cpu的最小数据要求,然后发送给cpu进行处理。数据大多,处理不了,那就把多余的数据放到buffer中,处理完了,再处理buffer中的数据。
这时,可以看到,buffer就是计算机内存中开辟的一块空间,在数据流的处理过程中,数据暂时在这里收集,等待,最后被发送出去处理。buffer就是用来暂时存储二进制数据的。
我们可以把整个流(stream)和buffer的处理过程看成一个汽车站。汽车只有达到特定的人数或特定的时间才能出发,乘客则从不同的地方赶来,有的来的早,有的来的晚,有的速度快,有的速度慢。汽车站控制不了乘客到来的时间和速度。这时就存在两种情况,一种是乘客来早了,汽车并没有满员,早来的乘客只能等待汽车的启程,另一种是,乘客都到了,但汽车却满员了,装不下了,只能先来的乘客坐车出发,剩下的乘客只能等下一辆汽车。无论哪一种情况,都有一个等待区(候车区),这个候车区就相当于Node.js 中的buffer. Node.js 控制不了数据到来的时间或速度(数量),控制不了流的速度,这些都是操作系统的控制的。Node.js只能控制总量或时间,只要到时间了或到量了,Node.js 就把数据发送出去处理。 如果不到时间,或不到量,Node.js 就先把数据放到buffer中。
另外一个例子就是在网上看视频,如果网络很好,视频就很流畅,如果网络不好,视频就很卡。这就是流和buffer起的作用,看视频就相当于数据从服务器流向客户端,网络好,每一次流入的数据量就大,cpu有可能都处理不过来,多余放到buffer中,如果快看完了,cpu直接从buffer去读取,速度快,你肯定没有感觉,非常流畅。网络不好,每一次流入的数据都不够cpu 处理的,所以都放到buffer 中,并不处理,等待更多的数据流入,可能流入了5次,才能够cpu 处理一次,那5次之间的时间,我们只能等待,视频就很卡了。
Node.js在处理文件操作,HTTP请求等TCP流的时候,会自动创建buffer来处理二进制数据。那么我们能不能自己创建buffer,来处理二进制数据,和二进制数据打交道?当然可以,那就是Buffer API. buffer是计算机内存中的一片空间,Buffer API使我们能够操作这片内存空间,比如,开辟空间,存储数据和读取数据。开辟空间,创建buffer 有两个主要方式:Buffer.alloc() 和Buffer.from(). alloc() 就是分配的意思,因此该方法接受一个必要的参数,就是这个buffer的大小,来告诉计算机要在内存中开辟(分配)多大的空间,参数值是一个整数,单位是字节。比如
Buffer.alloc(5);
就是在内存中开辟了5个字节大小的空间,为什么以字节为单位呢?因为操作的是计算机的内存(存储),计算机的最小存储单元就是字节,没有比它更小的了。
可以想到,操作buffer,就是操作字节。把Buffer.alloc()的返回值赋值成一个变量,就可以通过变量来操作这片内存空间了。
const firstBuffer = Buffer.alloc(5);
以Buffer.alloc(5) 这种方式创建buffer的时候,默认情况下,开辟的空间中存储的值全是二进制的0. 如果想在创建buffer时,不使用默认值,而是使用自定义的值进行填充,那就要用到alloc() 的第二个参数,用什么数据来填充整个buffer
const filledBuf = Buffer.alloc(5, 1);
这时filledBuf指向的内存空间中,值全是二进制的1. 尽管参数写的是十进制的1,但计算机会把它转化成二进制进行存储。填充字符可不可以?也可以
const stringBuf = Buffer.alloc(5, 'a');
但这里要注意,字符‘a’ 怎么转化成二进制进行存储。buffer中存储的全都是二进制的数字,无论填充什么,它最终都要转化成二进制数据。由于数字是计算机自动转化,所以填充数字的时候,没有考虑转化问题,但字符不行,计算机不认识字符。你可能想到了字符编码,字符转化成数字,数字再转化成二进制形式。数字(字符)怎么转化成二进制,占多少个字节,是由字符编码决定的。默认情况下,当你使用字符来初始化一个buffer的时候,buffer中字符是utf-8 编码。上面中的‘a’,就是按照utf-8 编码的形式转化成二进制,存储到计算机(buffer) 中。如果不想使用utf-8, 那也没有关系,使用第三个参数encoding 指定字符编码。
const utf16Buf = Buffer.alloc(5, 'a', 'utf-16le'); // UTF-16
字符‘a’ 按照utf-16 编码转化成二进制数据存储到buffer中。如果你想使用已有的数据创建buffer,或者把已有的数据转化成buffer,那怎么办?使用buffer.from().
已有的数据包含,数组,字符串,ArrayBuffer, 另一个buffer。先看数组
const arrayBuffer = Buffer.from([2,3]);
这里要注意的是数组元素的取值。使用数组创建buffer时,首先要开辟空间,数组有多少项,就开辟多少个字节的内存空间,然后把数组中的每一项对应放到每一个字节中,这时,你就发现问题了,一个字节只有8个bit, 一个bit只有0,1两种形式,所以8个bit的排列组合是256. 一个字节存储的最大值是256,一个字节存储范围是0-255。buffer中的字节都是无符号的(an unsigned 8-bit value), buffer中没有负数,因为它的由来是操作文件等字符的,字符没有负数一说。所以数组中元素的取值0-255.
使用字符串来创建buffer
const stringBuf = Buffer.from('My name is sam');
还是字符编码,默认字符编码utf-8,按照字符编码把'My name is sam' 转化成二进制数据,转化了多少个字节,就开辟多少个字节的内存空间,然后把它存储进去。
使用已有buffer创建一个buffer,相当于复制了
const asciiBuf = Buffer.alloc(5, 'a', 'ascii'); const asciiCopy = Buffer.from(asciiBuf);
buffer创建完毕,也存储了数据,那它在内存中是怎么存储数据的呢?怎么才能读到里面的数据呢?buffer 存储数据,就像数组一样,每一个数据都有序排列。可以console.log() 一下
const stringBuffer = Buffer.from('abc'); console.log(stringBuffer); // <Buffer 61 62 63>
61, 62, 63是十六进制,对应成十进制是97,98,99,正好是字符a,b,c 的unicode码点,可以看到数据的有序排列。因此读取buffer中数据的第一种方式,就是使用数组索引的方式一个字节一个字节来进行读取。
const stringBuffer = Buffer.from('abc'); console.log(stringBuffer[0]); // 97 console.log(stringBuffer[1]); // 98 console.log(stringBuffer[2]); // 99
分别输出了每一个字节中存储的二进制数据,不过是转化成了对应的十进制进行输出。如果读取buffer 中不存在的数据呢,比如
console.log(stringBuffer[3]);
简单输出undefined.
除了一个字节一个字节地读取buffer中的数据,还可以把buffer作为一个整体进行读取,那就toString() 和toJSON() 方法。toString() 就是把buffer中的字节(数字)都转成字符串,默认还是按照utf-8 进行转化。
const stringBuffer = Buffer.from('abc'); console.log(stringBuffer.toString()); //'abc'
如果不想使用默认的utf-8, 可以给toString() 指定一个编码参数
const stringBuffer = Buffer.from('abc'); const stringAccii = stringBuffer.toString('ascii'); // 指定ascii码 console.log(stringAccii); // abc
toJSON() 返回的则是整个buffer中,每一个字节所对应的整数表现形式, 也是以十进制进行输出
const stringBuffer = Buffer.from('abc'); console.log(stringBuffer.toJSON()) // { type: 'Buffer', data: [ 97, 98, 99 ] }
toJSON() 输出的结果中,永远都有一个type属性,并且它的值永远都是'Buffer', data属性才是整个buffer数据的整数展示形式,type主要是为了和其它JSON对象进行区分。
创建和读取说完了,再说一下修改。和读取数据一样,既可以一个字节一个字节地修改buffer内容, 也可以整体修改buffer内容。一个字节一个字节地修改,就像修改数组元素的值一样。把 abc中的a改成A, 可能想像下面一样进行操作
const stringBuffer = Buffer.from('abc'); stringBuffer[0] = 'A';
调用toString()方法把stringBuffer转化成字符串,看一看修改有没有成功
console.log(stringBuffer.toString()); // 'bc'
你会发现,只输出了'bc', 并没有修改成功,为什么呢?因为buffer中存储的都是二进制的数字,所以它只能接受数字,也就是说只能赋值整数,而不能赋值字符。’A‘的unicode 码是65,那就把65赋值成stringBuffer[0]
stringBuffer[0] = 65; console.log(stringBuffer.toString()); // 'Abc'
如果不小心修改了buffer中不存在的值,比如修改101位上的值
stringBuffer[100] = 65; console.log(stringBuffer.toString()); // 'abc'
buffer会忽略这个操作,它的内容不会有任何变化。如果想整体改变这个buffer的值,用write() 方法,它接受一个字符串,用于替换原buffer的内容。
stringBuffer.write('ABC'); console.log(stringBuffer.toString()); // 'ABC'
这个方法有一个返回值,表示write() 方法向buffer中写入了多少个字节的内容,在这里是3,在utf-8下,’ABC‘ 占三个字节。如果你写的内容多于原buffer的大小呢?多余的内容会被忽略
const num = stringBuffer.write('ABCDEF'); console.log(stringBuffer.toString(), num); // 'ABC' 3
只有'ABC'被写入到stringBuffer中,’DEF‘ 被忽略了。write()以有序的方式向buffer中写入数据,从buffer的起始位置开始写起,它先写'A', 替换掉了原buffer中的‘a’,再写'B', 替换掉原buffer中的‘b’,再写'C', 替换掉原buffer中的‘c‘,这时buffer 已经填充完毕,它就不继续写了,只有'ABC' 写入进去了。如果写入的内容少于原buffer 的内容呢?比如只写一个'A'
const stringBuffer = Buffer.from('abc'); stringBuffer.write('A'); console.log(stringBuffer.toString()); // 'Abc'
只替换掉了原buffer中的第一个字符,剩余的内容不会动。
除了write()方法,还有copy()方法,来修改buffer的值。copy()最简单的用法是source.copy(target). source中存在着我们想要复制的内容,target就是要复制到的buffer。只要哪个buffer中有想要的内容,那就用它来调用copy(),再给它传入需要这些内容的buffer。用大写替换小写,
const uppcaseBuffer = Buffer.from('ABC'); const lowercaseBuffer = Buffer.from('abc'); uppcaseBuffer.copy(lowercaseBuffer) console.log(lowercaseBuffer.toString()); // 'ABC'
copy() 把整个uppcaseBuffer中内容都复制到了lowercaseBuffer(), 当然也是执行的字节的替换。但有的时候,只想替换某一部分内容,只把’A‘ 复制过来替换’a‘,那就使用copy() 的复杂形式。
copy(target, targetStart, sourceStart, sourceEnd);
target: 要复制到的目的地buffer, targetStart: 目的地buffer的起始位置,把复制过来的内容从哪个位置开始替换target中的内容。sourceStart, sourceEnd, 就是表示要复制sourceStart 到sourceEnd 之间的容。
const uppcaseBuffer = Buffer.from('ABC'); const lowercaseBuffer = Buffer.from('abc'); uppcaseBuffer.copy(lowercaseBuffer, 0, 0, 1) console.log(lowercaseBuffer.toString()); // 'Abc'
总结一下:
buffer就是计算机内存中的一块空间,可以把它想像成数组,数组(buffer)中每一个元素的大小就是一个字节,每一个元素的值都是二进制数据,值的取值范围是0-255,没有负数。无论存储什么数据到buffer中,它都会变成二进制数据。Buffer.from('abc') 创建的buffer在内存中表现形式可以描述为 [01100001, 01100010, 01100011]。 当看到一个buffer的时候,应该看到的是0101... 的排列组合,它本身已经无法表示什么意义了。它具体什么意义,就看我们怎么读取了。还是Buffer.from('abc') 来举例
const anyBuffer = Buffer.from('abc'); console.log(anyBuffer.toString('utf16le')); // 扡 console.log(anyBuffer.toString('hex')); // 616263
toString('utf16le') 就是按照utf-16编码来读取该buffer。utf-16,每一个字符都占两个字节,所以它就读取buffer的前两个字节:01100001 01100010, utf16le对字节进行操作的时候调换了一个顺序,01100001 01100010 转化成了01100010 01100001, 01100010 01100001 对应的十进制是25185,25185对应的unicode字符是'扡', 使用浏览器的控制台进行如下操作
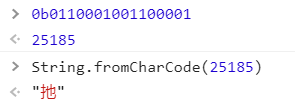
读完前两个字节,再往下读,还剩下一个字节, 因为不够两个字节,所以就不操作了。
toString('hex') 就是把这个buffer转化成十六进制,读取这个buffer的全部字节01100001 01100010 01100011, 然后转化成十六进制。可以先转化成十进制,01100001 01100010 01100011 转化成十进制是6382179, 6382179转化成十六进制是616263, 用浏览器的控制台进行如下操作
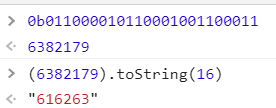
buffer的操作就是一个个字节的操作。