基础概念
列(Column):一个属性,有明确的类型,必须是原子类型(原子类型:不能再进一步分割,没有内部结构)
行(Row,Tuple,Record):一个记录
表(Table,Relation):记录的集合,每条记录之间无序
Schema:类型,一个表的类型由每个列的类型确定
Instance:具体取值,具体存储哪些记录,每个列的具体值
Schema只被定义一次,且一个Schema对应多个Instance
Key:唯一确定一个记录
Primary Key:唯一确定本表中的一个记录
Foreign Key:唯一确定另外一张表中的一个记录(是另外这张表的Primary Key)
主要关系运算:选择σ(Selection)、投影Π(Projection)、连接⋈(Join)选择:从一张表中提取一些行,如σMajor=‘计算机’(Student) 等于 select * from Student where Major = '计算机'
投影:从一张表中提取一些列,如ΠName,GPA(Student) 等于 select Name,GPA from Student
连接:已知两个表R和S,R表的a列和S表的b列,以R.a = S.b为条件的连接,找到两个表中互相匹配的记录,即R⋈R.a = S.bS,R.a与S.b被称为join key,如select * from R,S where R.a=S.b(等同于select * from R inner join S on R.a=S.b)
对于其他outer join方式而言on是建临时表用的,where则是在临时表上再次进行筛选
order by 列名:以指定列为标准进行排序,默认为升序(order by 列名 ASC),也可降序(order by 列名 DESC)
group by 列名:以指定列为基准进行分组统计,同时可以对其他列使用统计函数(如sum, count, avg, max, min)
Having:在group by的基础上再次进行选择,如having x>=2
系统架构
前端:SQL Parser
Query Optimizer
后端:Execution Engine Transaction management
Buffer Pool
Data Storage and Indexing
SQL Parser:SQL语句-》内部表达(如Parsing Tree)
语法解析,语法检查,表名、列名、类型检查
Query Optimizer: 内部表达-》执行方案(Query plan)
产生可行的query plan,并为其预估运行时间、空间代价,在多个可行的query plan中选择最佳的query plan
Data storage and indexing:在硬盘上存储数据,并高效的访问它们
Buffer pool:在内存中缓存硬盘的数据
Execution Engine: query plan-》执行得到结果
根据query plan完成相应的运算和操作,数据访问,关系型运算的实现
Transaction management:事务管理
实现ACID,写日志,加锁,保证事务正确性
文件系统与数据库的比较
| 文件系统 | 数据库 |
| 存储的是文件(file) | 存储的是表(table) |
| 通用的,可以存储任何数据和程序 | 专用的,针对关系型数据库进行存储 |
| 文件无结构,由一系列字节组成 | 表由记录组成,每个记录由多个属性组成 |
| 操作系统内核中实现 | 用户态程序中实现 |
| 提供基本编程接口(open,close,read,write) | 提供SQL接口 |
共同点:数据都存储在外存,会根据外存特征在存储上进行优化(如对硬盘而言,数据被分成定常的数据块)
数据在硬盘上的存储:
硬盘最小存储访问单位为:一个扇区(512B)
文件系统访问硬盘的单位通常为:4KB
RDBMS最小的存储单位为database page size,database page size通常为1-n个文件系统的page 如4KB 8KB 16KB ……等
对于一个database page 而言,其结构为: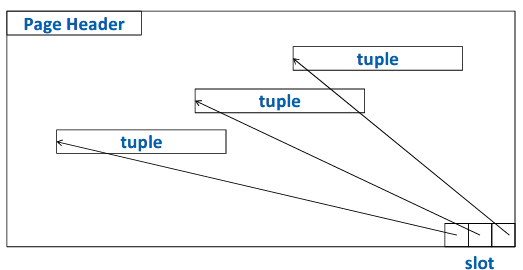
每个tuple都是一条记录,slot记录了每一个tuple相对于页头的偏移量,这样的设计方便存储变长记录,slot大小固定
对于一个page中的每一个tuple而言,其结构为:
len为这个tuple的长度,接着首先存储变长字段的偏移量(var off),再存储固定长度字段,再存储变长字段,这样可以最大化利用空间
如果在检索时,指定了检索特定条件的数据,那么就会顺序访问每一个page及其中的tuple,效率较低,此时可以使用索引来进行有选择的访问
常用索引包括:
Tree based index:有序,支持点查询和范围查询
Hash based index:无序,只支持点查询
Chained hash table:
在硬盘上存储时,每一个bucket都相当于一个page,若chain上平均bucket太多则加大header size,重新hash
B+ - Trees
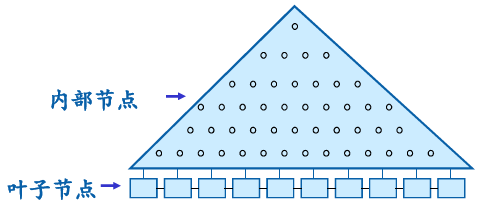
对于b+树而言,每个节点都是一个page,所有key存储在叶子节点,内部节点只作索引用

对于叶子节点而言,key之间都从小到大排列,叶子节点之间右sibling pointer相连接,前一个的sibling 存储的是下一个叶子节点的page id,每个ptr存储的是每一条记录的id(record id)
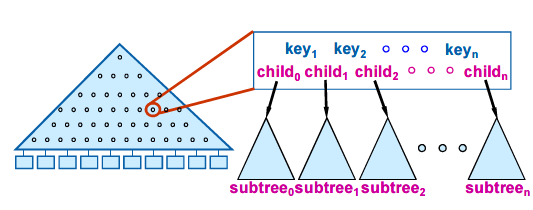
对于内部节点而言,有subtree0<key1<subtree1<key2<……<keyn
主索引与二级索引:
主索引:索引中存储了记录,且索引顺序与记录的存储顺序相同
二级索引:索引的顺序与记录的存储顺序不同,索引的值存储的不是记录,而是记录的位置(包括page id 和页内的tuple slot id)
顺序访问与二级索引访问对比:对于顺序访问而言,需要顺序读取每一个page并处理其中的每一个tuple对比是否符合检索条件,如果用二级索引则会随机读相关的page并有选择的处理相关的tuple
如何选择使用顺序访问查找还是二级索引查找呢?这取决于index selectivity、硬盘顺序读/随机读性能,通过预估两种方式的执行时间来选择其中所需时间较短的方案,这个任务由query optimizer完成
Buffer Pool
数据访问具有局部性:
时间局部性:同一数据可能在一段时间内被多次访问(使用Buffer Pool将其暂时存储在内存中)
空间局部性:位置相近的数据可能会被一起访问(以Page为单位进行读写)
为了适应这两个特性,Buffer Pool被设计为由和Page相同大小的frame组成,每个frame可以存储一个page
常见替换策略:random、FIFO、LRU
LRU(最近最少使用):

实现放法2:将buffer head做成一链表,每次访问过的page都将其移动到表头,则当需要替换时,只需要替换最后一个page,此时代价为O(1),但移动及多线程需要更多代价
Clock算法:
当一个页装入内存时,其R赋值为1,移动指针
若访问到的页值为1则将其置为0,移动指针
如果遇到R=0的则意味着这个page一直没被访问,则替换掉它
运算的实现
query plan将最终表现为一颗operate tree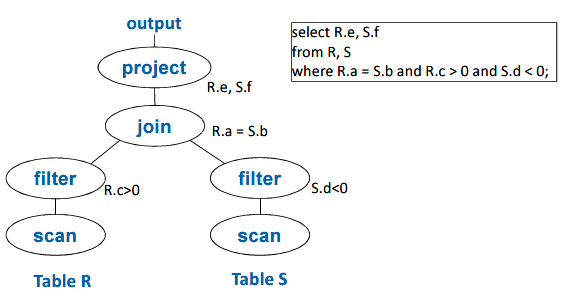
每个节点代表一个运算,运算的输入来自于该节点的孩子节点,运算产生结果后送往其父节点
pull:每个operator都实现了open、close、getnext等方法,父节点调用子节点的GetNext取得子节点的输出
push:子节点将输出放入缓冲区,通知父节点去读取
join的实现:nested loop、hashing、sorting
1、nested loop join
若R有MR个Page,S有MS个Page,每个Page有B个记录
如果都扫描一遍,则总共需要读取:MR+MRMSB次,很费IO
Block nested loop join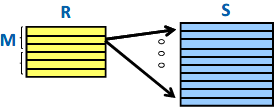
每次读取M行记录 到缓存中,然后读取一次S,这样减少了读取R中记录的次数
此时总的读取page次数为:MR+(MR/M)MS次,减少了一定的IO次数
Index nested loop join
查两个表中的index来寻找匹配
Hash join:
Simple hash join
首先读取R,为其建立hash table,再读S,将与指定的join key相同join key的条目进行hash,然后去之前为R构造的hash table进行探测找到匹配
GRACE Hash Join
若内存不够大,无法放下其hash table,则可以将其hash结果分块(mod 一个partition number),同样的,对S每个匹配的条目hash后也mod partition nuber,这样就能去R的hash table的对应块中进行探测,来寻找匹配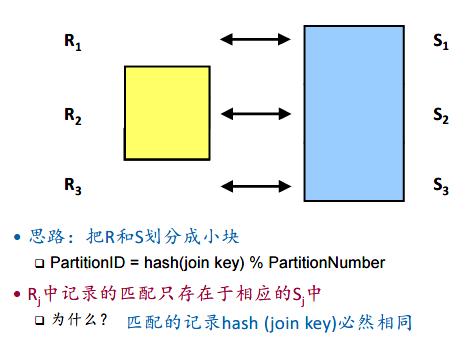
若R有MR个Page,S有MS个Page,每个Page有B个记录
则对R和S进行hash时,读MR+MS个Page,构建hash table时写MR+MS个Page,进行匹配时又读了一遍MR+MS,所以总代价为读2(MR+MS)个Page,写MR+MS个Page
Sort Merge Join
首先将R和S按照其join key(如R.a,S.b)排序,然后对其结果进行混合,之后对其进行排序,那么相同的joinkey则会被排在一起
通常代价比Hash join稍高,当表已经按照join key有序时会使用此方法
事务处理
ACID:
Atomicity(原子性):要么完全执行,要么完全没有执行
Consistency(一致性):从一个正确状态转换到另一个正确状态
Isolation(隔离性):每个事务与其他并发事务互不影响
Durability(持久性):transaction commit 后,结果持久有效,crash也不消失
如何判断一组transaction正确执行:存在一个顺序,按照这个顺序依次串行执行这些transactions,得到的结果与并行执行相同(可串行化,即并行执行结果=某个顺序的串行执行结果)