今天收获满满吧,竟然一天时间可以把那个论文弄得差不多了,最后晚上导师把论文过了一遍感觉也清楚了逻辑,也知道了哪里需要学习的地方。基本明天可以学python,写代码了。
1.self-attention机制,可以描述为将query和一组key-value对映射到输出,其中query、key、value和输出都是向量。输出为value的加权和,其中分配给每个value的权重通过query与相应key的兼容函数来计算。
具体来说:有3个关键的向量Q,K,V初始时随机生成的,X向量是单词通过word2vec转换的向量。其步骤 :第一步,将query 与key进行点积计算得到权重,对应相乘。第二步,将权重进行softmax化。第三步,将value与权重对应相乘并进行相加得到attention
2.多头注意力机制,即在self-attention机制中的Q,W,K可以分别设置多个不同w的参数(线性变换),可以并行运行,最后连接,然后线性化。问了导师,导师的意思将维度增加。这样做的好处是:可以使不同的表示子空间内学习到相关的信息。
3.X--->(n,512) 8个头,Q(n,64),K(n,64),V(n,64)----------维度这里没有搞明白到底怎么计算的,多层的时候怎么计算的
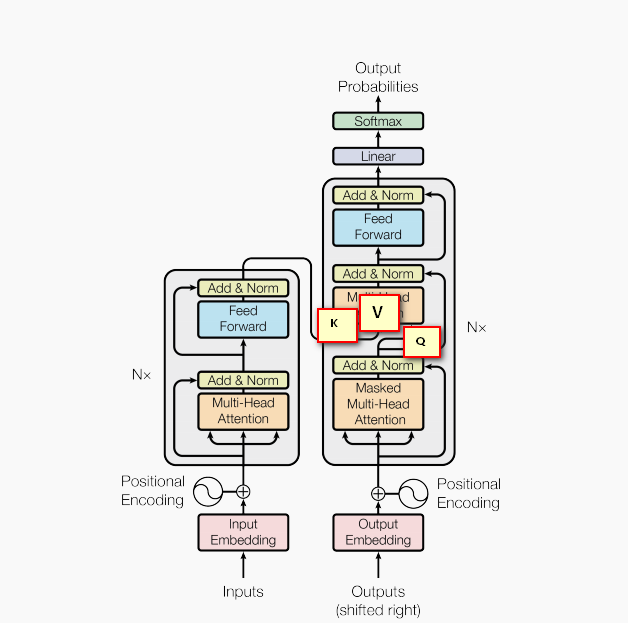
4. 上图大体,是Encoder部分,Decoder部分。在Encoder部分,首先,得到了X输入序列,进行位置编码,然后进入多头自我注意,每两层用到了残差连接,进行相加和规范化。然后进行反馈网络,然后残差连接。将输出的序列以及K,V传到Decoder部分。Decoder部分,将目标端的序列进行attention,然后残差连接,与Encoder传来的参数,并将Q传到下一部分进行multi-head attention,然后残差连接,最后线性化,并归一化。
5.要学习的position-encoding,embedding,前馈网络,损失函数,Dropout,label smoothing,正则化------打包回家
感觉写下来,嗯没有表达完。。。。。。。。。。