一:线性表
1.1:定义:零个或多个数据元素的有限序列
1.2:

线性表元素个数n定义为线性表的长度,n = 0称为空表,i 为数据元素ai在线性表中的位序。
1.3:满足线性表的条件:(1):有序,有限
(2):第一个元素无前驱,最后一个元素无后继
(3):数据类型相同
(4):元素之间首位相连
1.4:线性表两种存储结构:顺序存储结构和链式存储结构
二:线性表顺序存储结构
2.1:顺序存储(Sequence Storage)结构定义:指的是用一段地址连续的存储单元依次存储线性表的数据元素。
2.2:数据长度和线性表长度的区别:数组长度是存放线性表的存储空间的长度,一般不变。线性表长度是线性表中数据元素的个数,会随着插入和删除而改变。
2.3:线性表常用操作接口:


1 public interface IListDS<T> 2 { 3 int GetLength(); //求长度 4 void Clear(); //清空操作 5 bool IsEmpty(); //判断线性表是否为空 6 void Append(T item); //附加操作 7 void Insert(T item, int i); //插入操作 8 T Delete(int i); //删除操作 9 T GetElem(int i); //取表元 10 int Locate(T value); //按值查找 11 12 }
2.4:顺序表实现:类 SeqList<T>的实现说明如下
1 /// <summary> 2 /// 线性表的顺序存储结构 3 /// </summary> 4 /// <typeparam name="T"></typeparam> 5 public class SeqList<T> : IListDS<T> 6 { 7 private int maxsize;//顺序表的容量 8 private T[] data;//数组,用于存储顺序表中的数据元素 9 private int last;//指示顺序表最后一个元素的位置 10 11 //索引器 12 public T this[int index] 13 { 14 get 15 { 16 return data[index]; 17 } 18 set 19 { 20 data[index] = value; 21 } 22 } 23 24 //最后一个数据元素位置属性 25 public int Last 26 { 27 get 28 { 29 return last; 30 } 31 } 32 33 //容量属性 34 public int MaxSize 35 { 36 get 37 { 38 return maxsize; 39 } 40 set 41 { 42 maxsize = value; 43 } 44 } 45 46 //构造器 47 public SeqList(int size) 48 { 49 data = new T[size]; 50 maxsize = size; 51 last = -1; 52 } 53 54 //求顺序表的长度 55 public int GetLength() 56 { 57 return last + 1; 58 } 59 60 //清空顺序表 61 public void Clear() 62 { 63 last = -1; 64 } 65 66 //判断顺序表是否为空 67 public bool IsEmpty() 68 { 69 if (last == -1) 70 { 71 return true; 72 } 73 else 74 { 75 return false; 76 } 77 } 78 79 //判断顺序表是否为满 80 public bool IsFull() 81 { 82 if (last == maxsize - 1) 83 { 84 return true; 85 } 86 else 87 { 88 return false; 89 } 90 } 91 92 public void Append(T item) 93 { 94 if (IsFull()) 95 { 96 Console.WriteLine("List is full"); 97 return; 98 } 99 data[++last] = item; 100 } 101 102 //在顺序表的第i个数据元素的位置插入一个数据元素 103 public void Insert(T item, int i) 104 { 105 if (IsFull()) 106 { 107 Console.WriteLine("List is full"); 108 return; 109 } 110 111 if (i < 1 || i > last + 2) 112 { 113 Console.WriteLine("Position is error!"); 114 return; 115 } 116 117 if (i == last + 2)//在末尾插入 118 { 119 data[last + 1] = item; 120 } 121 else 122 { 123 for (int k = last; k >= i - 1; --k) 124 { 125 data[k + 1] = data[k]; 126 } 127 data[i - 1] = item; 128 } 129 ++last;//最后一个元素的位置加一 130 } 131 132 //删除顺序表的第i个数据元素,返回删除元素 133 public T Delete(int i) 134 { 135 T tmp = default(T); 136 if (IsEmpty()) 137 { 138 Console.WriteLine("List is empty"); 139 return tmp; 140 } 141 if (i < 1 || i > last + 1) 142 { 143 Console.WriteLine("Position is error!"); 144 return tmp; 145 } 146 if (i == last + 1)//末尾删除 147 { 148 tmp = data[last--]; 149 } 150 else 151 { 152 tmp = data[i - 1]; 153 for (int k = i; k <= last; ++k) 154 { 155 data[k - 1] = data[k]; 156 } 157 } 158 --last; 159 return tmp; 160 } 161 162 //获得顺序表的第i个数据元素 163 public T GetElem(int i) 164 { 165 if (IsEmpty() || (i < 1) || (i > last + 1)) 166 { 167 Console.WriteLine("List is empty or Position is error!"); 168 return default(T); 169 } 170 return data[i - 1]; 171 } 172 173 //在顺序表中查找值为value的数据元素 174 public int Locate(T value) 175 { 176 if (IsEmpty()) 177 { 178 Console.WriteLine("List is Empty!"); 179 return -1; 180 } 181 int i = 0; 182 for (i = 0; i <= last; ++i) 183 { 184 if (value.Equals(data[i])) 185 { 186 break; 187 } 188 } 189 if (i > last) 190 { 191 return -1; 192 } 193 return i; 194 } 195 196 }
2.5:优缺点:
优点: (1):无须为表示表中之间的逻辑关系而增加额外的存储空间
(2):可以快速的读取表中的任意位置的元素
缺点: (1):插入和删除操作需要移动大量元素
(2):当线性表长度变化较大时,难以确定存储空间的容量
(3):造成存储空间的"碎片"。
三:线性表的链式存储结构
3.1:链表定义:链表是用一组任意的存储单元来存储线性表中的数据元素(这组存储单元可以是连续的,也可以是不连续的)。
3.2:在存储数据元素时,除了存储数据元素本身的信息外,还要存储与它相邻的数据元素的存储地址信息。这两部分信息组成该数据元素的存储映像(Image),称为结点(Node)。把存储据元素本身信息的域叫结点的数据域(Data Domain),把存储与它相邻的数据元素的存储地址信息的域叫结点的引用域(Reference Domain)。
3.3:单链表
3.3.1:如果结点的引用域只存储该结点直接后继结点的存储地址,则该链表叫单链表(Singly Linked List)
3.3.2:单链表的的结点结构如下:
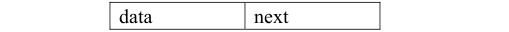
把单链表结点看作是一个类,类名为 Node<T>。单链表结点类的实现如下所示。
1 /// <summary> 2 /// 单链表节点类实现 3 /// </summary> 4 /// <typeparam name="T"></typeparam> 5 public class Node<T> 6 { 7 private T data;//数据域 8 private Node<T> next;//引用域 9 10 11 //构造器 12 public Node(T val, Node<T> p) 13 { 14 Data = val; 15 Next = p; 16 } 17 18 public Node(Node<T> p) 19 { 20 Next = p; 21 } 22 23 public Node(T val) 24 { 25 Data = val; 26 Next = null; 27 } 28 29 public Node() 30 { 31 Data = default(T); 32 Next = null; 33 } 34 35 public T Data { get; set; } 36 public Node<T> Next { get; set; } 37 }
3.3.3:通常,我们把链表画成用箭头相连接的结点的序列,结点间的箭头表示引用域中存储的地址。为了处理上的简洁与方便,在本书中把引用域中存储的地址叫引用。单链表示意图如下:

由图可知单链表由头引用 H 唯一确定。头引用指向单链表的第一个结点,也就是把单链表第一个结点的地址放在 H 中,所以,H 是一个 Node 类型的变量。头引用为 null 表示一个空表。
3.3.4: 把单链表看作是一个类,类名叫 LinkList<T>。LinkList<T>类也实现了接口IListDS<T>。LinkList<T>类有一个字段 head,表示单链表的头引用,所以 head的类型为 Node<T>。由于链表的存储空间不是连续的,所以没有最大空间的限制,在链表中插入结点时不需要判断链表是否已满。因此,在 LinkList<T>类中不需要实现判断链表是否已满的成员方法。
单链表类 LinkList<T>的实现说明如下所示。
1 /// <summary> 2 /// //单链表类实现 3 /// </summary> 4 /// <typeparam name="T"></typeparam> 5 public class LinkList<T> : IListDS<T> 6 { 7 private Node<T> head; //单链表的头引用 8 9 public Node<T> Head //头引用属性 10 { 11 get 12 { 13 return head; 14 } 15 set 16 { 17 head = value; 18 } 19 } 20 21 public LinkList() 22 { 23 head = null; 24 } 25 26 //求单链表的长度 27 public int GetLength() 28 { 29 Node<T> p = head; 30 int length = 0; 31 while (p != null) 32 { 33 34 ++length; 35 p = p.Next; 36 37 } 38 return length; 39 40 } 41 42 //清空单链表 43 public void Clear() 44 { 45 head = null; 46 } 47 48 //判断单链表是否为空 49 public bool IsEmpty() 50 { 51 if (head == null) 52 { 53 return true; 54 } 55 else 56 { 57 return false; 58 } 59 } 60 61 //在单链表的末尾(空节点)添加新元素 62 public void Append(T item) 63 { 64 Node<T> q = new Node<T>(item); 65 Node<T> p = new Node<T>();//头结点 66 67 if (head == null) 68 { 69 head = q; 70 return; 71 } 72 73 p = head; 74 while (p.Next != null) 75 { 76 p = p.Next; 77 } 78 79 p.Next = q; 80 } 81 82 //在单链表的第i个结点的位置前插入一个值为item的结点 83 public void Insert(T item, int i) 84 { 85 86 if (IsEmpty() || i < 1) 87 { 88 Console.WriteLine(" List is empty or Position is error! "); 89 return; 90 } 91 92 if (i == 1) 93 { 94 Node<T> q = new Node<T>(item); 95 q.Next = head; 96 head = q; 97 return; 98 } 99 100 Node<T> p = head; 101 Node<T> r = new Node<T>(); 102 int curPosition = 1; 103 104 while (p.Next != null && curPosition < i) 105 { 106 r = p; 107 p = p.Next; 108 ++curPosition; 109 } 110 111 if (curPosition == i) 112 { 113 Node<T> q = new Node<T>(item); 114 q.Next = p; 115 r.Next = q; 116 117 } 118 } 119 120 //在单链表的第i个结点的位置后插入一个值为item的结点 121 public void InsertPost(T item, int i) 122 { 123 if (IsEmpty() || i < 1) 124 { 125 Console.WriteLine(" List is empty or Position is error! "); 126 return; 127 } 128 129 if (i == 1) 130 { 131 Node<T> q = new Node<T>(item); 132 q.Next = head.Next; 133 head.Next = q; 134 return; 135 } 136 137 Node<T> p = head; 138 int curPosition = 1; 139 140 while (p != null && curPosition < i) 141 { 142 p = p.Next; 143 ++curPosition; 144 } 145 146 if (curPosition == i) 147 { 148 Node<T> q = new Node<T>(item); 149 q.Next = p.Next; 150 p.Next = q; 151 } 152 } 153 154 //删除单链表的第i个结点 155 public T Delete(int i) 156 { 157 if (IsEmpty() || i < 0) 158 { 159 Console.WriteLine(" List is empty or Position is error! "); 160 return default(T); 161 } 162 163 Node<T> q = new Node<T>(); 164 165 if (i == 1) 166 { 167 q = head; 168 head = head.Next; 169 return q.Data; 170 } 171 172 Node<T> p = head; 173 int curPosition = 1; 174 while (p.Next != null && curPosition < i) 175 { 176 q = p; 177 p = p.Next; 178 ++curPosition; 179 } 180 181 if (curPosition == i) 182 { 183 q.Next = p.Next; 184 return p.Data; 185 } 186 else 187 { 188 Console.WriteLine("The ith node is not exist!"); 189 return default(T); 190 } 191 192 } 193 194 //获得单链表的第i个数据元素 195 public T GetElem(int i) 196 { 197 if (IsEmpty()) 198 { 199 Console.WriteLine(" List is empty or Position is error! "); 200 return default(T); 201 } 202 203 Node<T> p = new Node<T>(); 204 p = head; 205 int curPosition = 1; 206 207 while (p.Next != null && curPosition < i) 208 { 209 p = p.Next; 210 ++curPosition; 211 } 212 213 if (curPosition == i) 214 { 215 return p.Data; 216 } 217 else 218 { 219 Console.WriteLine("The ith node is not exist!"); 220 return default(T); 221 } 222 } 223 224 //在单链表中查找值为value的结点 225 public int Locate(T value) 226 { 227 if (IsEmpty()) 228 { 229 Console.WriteLine(" List is empty or Position is error! "); 230 return -1; 231 } 232 233 Node<T> p = new Node<T>(); 234 p = head; 235 int curPosition = 1; 236 while (!p.Data.Equals(value) && p.Next != null) 237 { 238 p = p.Next; 239 ++curPosition; 240 } 241 242 return curPosition; 243 } 244 }
3.3.5: 算法的时间复杂度分析:从前插和后插运算的算法可知,在第 i 个结点处插入结点的时间主要消耗在查找操作上。由上面几个操作可知,单链表的查找需要从头引用开始,一个结点一个结点遍历,因为单链表的存储空间不是连续的空间。这是单链表的缺点,而是顺序表的优点。找到目标结点后的插入操作很简单,不需要进行数据元素的移动,因为单链表不需要连续的空间。删除操作也是如此,这是单链表的优点,相反是顺序表的缺点。遍历的结点数最少为 1 个,当 i 等于1 时,最多为 n,n 为单链表的长度,平均遍历的结点数为 n/2。所以,插入操作的时间复杂度为 O(n)。
因此,线性表的顺序存储和链式存储各有优缺点,线性表如何存储取决于使用的场合。如果不需要经常在线性表中进行插入和删除,只是进行查找,那么,线性表应该顺序存储;如果线性表需要经常插入和删除,而不经常进行查找,则线性表应该链式存储。
3.3.6:单链表的建立
单链表的建立与顺序表的建立不同,它是一种动态管理的存储结构,链表中的每个结点占用的存储空间不是预先分配,而是运行时系统根据需求而生成的。单链表的建立分为在头部插入结点建立单链表和在尾部插入结点建立单链表。
(1):在单链表的头部插入结点建立单链表。
1 //头部插入结点建立单链表的算法如下 2 public LinkList<int> CreateLListHead() 3 { 4 int d; 5 LinkList<int> L = new LinkList<int>(); 6 d = Int32.Parse(Console.ReadLine()); 7 while (d != -1) 8 { 9 Node<int> p = new Node<int>(d); 10 p.Next = L.head; 11 L.head = p; 12 d = Int32.Parse(Console.ReadLine()); 13 } 14 return L; 15 }
(2):头部插入结点建立单链表简单,但读入的数据元素的顺序与生成的链表中元素的顺序是相反的。若希望次序一致,则用尾部插入的方法。因为每次是将新结点插入到链表的尾部,所以需加入一个引用 R 用来始终指向链表中的尾结点,以便能够将新结点插入到链表的尾部。
1 //在尾部插入结点建立单链表的算法如下: 2 public LinkList<int> CreateListTail() 3 { 4 Node<int> R = new Node<int>(); 5 int d; 6 LinkList<int> L = new LinkList<int>(); 7 R = L.head;//尾部结点 8 d = Int32.Parse(Console.ReadLine()); 9 while (d != -1) 10 { 11 Node<int> p = new Node<int>(d); 12 if (L.head == null) 13 { 14 L.head = p; 15 } 16 else 17 { 18 R.Next = p; 19 } 20 R = p; 21 d = Int32.Parse(Console.ReadLine()); 22 } 23 if (R != null) 24 { 25 R.Next = null; 26 } 27 return L; 28 }
(3):在上面的算法中,第一个结点的处理和其它结点是不同的,原因是第一个结点加入时链表为空,它没有直接前驱结点,它的地址存放在链表的头引用中;而其它结点有直接前驱结点,其地址放在直接前驱结点的引用域中。在头部插入结点建立单链表的算法中,头引用所指向的结点也是变化的。“第一个结点”的问题在很多操作中都会遇到,如前面讲的在链表中插入结点和删除结点。为了方便处理,其解决办法是让头引用保存的结点地址不变。因此,在链表的头部加入了一个叫头结点(Head Node)的结点,把头结点的地址保存在头引用中。这样,即使是空表,头引用变量也不为空。头结点的加入使得“第一个结点”的问题不再存在,也使得“空表”和“非空表”的处理一致。
头结点的加入完全是为了操作的方便,它的数据域无定义,引用域存放的是第一个结点的地址,空表时该引用域为空。带头结点的单链表空表和非空表的示意图如下:

单链表带头结点和不带头结点,操作有所不同,上面讲的操作都是不带头结点的操作。例如:带头结点的单链表的长度是不带头结点的单链表的长度加 1。在需要遍历单链表时,不带头结点的单链表是把头引用 head 赋给一个结点变量,即 p = head,p 为结点变量;而带头结点的单链表是把 head 的引用域赋给一个结点变量,即 p = head.Next,p 为结点变量。
3.4:双向链表
3.4.1:在结点中设两个引用域,一个保存直接前驱结点的地址,叫 prev,一个直接后继结点的地址,叫 next,这样的链表就是双向链表(Doubly Linked List)。双向链表的结点结构如下图:

双向链表结点的定义与单链表的结点的定义很相似,,只是双向链表多了一个字段 prev。双向链表结点类的实现如下所示
1 /// <summary> 2 /// 双向链表结点类的实现 3 /// </summary> 4 /// <typeparam name="T"></typeparam> 5 public class DbNode<T> 6 { 7 private T data;//数据域 8 private DbNode<T> prev;////前驱引用域 9 private DbNode<T> next;//后继引用域 10 11 //构造器 12 public DbNode(T val, DbNode<T> p) 13 { 14 Data = val; 15 Next = p; 16 } 17 18 public DbNode(DbNode<T> p) 19 { 20 Next = p; 21 } 22 23 public DbNode(T val) 24 { 25 Data = val; 26 Next = null; 27 } 28 29 public DbNode() 30 { 31 Data = default(T); 32 Next = null; 33 } 34 35 //数据域属性 36 public T Data { get; set; } 37 38 //前驱引用域属性 39 public DbNode<T> Prev { get; set; } 40 41 //后继引用域属性 42 public DbNode<T> Next { get; set; } 43 44 }
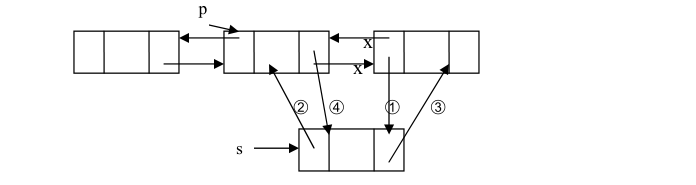
3.4.2:双向链表插入:由于双向链表的结点有两个引用,所以,在双向链表中插入和删除结点比单链表要复杂。双向链表中结点的插入分为在结点之前插入和在结点之后插入,插入操作要对四个引用进行操作。下面以在结点之后插入结点为例来说明在双向链表中插入结点的情况。设 p 是指向双向链表中的某一结点,即 p 存储的是该结点的地址,现要将一个结点 s 插入到结点 p 的后面。
操作如下:
➀ p.Next.Prev = s;
➁ s.Prev = p;
➂ s.Next = p.Next;
➃ p.Next = s;
注:引用域值的操作的顺序不是唯一的,但也不是任意的,操作➂必须放到操作➃的前面完成,否则 p 直接后继结点的就找不到了。
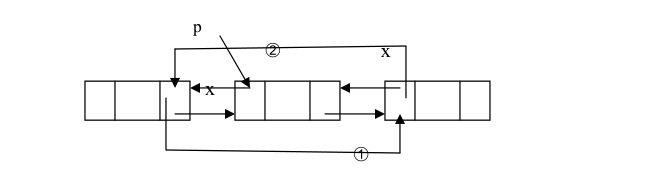
3.4.3:双向链表删除:以在结点之后删除为例来说明在双向链表中删除结点的情况。设 p 是指向双向链表中的某一结点,即 p 存储的是该结点的地址,删除该节点P如下图所示
操作如下:
➀ p.Next = P.Next.Next;
➁ p.Next.Prev = p.Prev;
3.5:循环链表
有些应用不需要链表中有明显的头尾结点。在这种情况下,可能需要方便地从最后一个结点访问到第一个结点。此时,最后一个结点的引用域不是空引用,而是保存的第一个结点的地址(如果该链表带结点,则保存的是头结点的地址),也就是头引用的值。带头结点的循环链表( Circular Linked List )
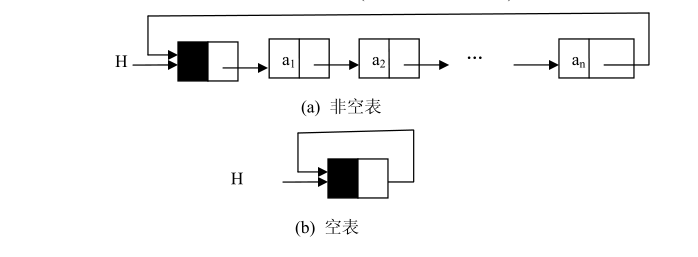
循环链表的基本操作与单链表大体相同,只是判断链表结束的条件并不是判断结点的引用域是否为空,而是判断结点的引用域是否为头引用,其它没有较大的变化。
四:c#中的线性表
4.1:C# 1.1 中只提供了非泛型 IList 接口,接口中项的类型是 object。非泛型 IList 接口是从 ICollection 接口继承而来,是所有线性表的基接口。
4.2:非泛型的 IList 接口的声明如下:
1 interface IList : ICollection,IEnumerable 2 { 3 //公有属性 4 bool IsFixedSize{get;} //只读,如果 IList 有固定大小, 5 //其值为 true,否则为 false。 6 bool IsReadOnly{get;} //只读,如果 IList 是只读的, 7 //其值为 true,否则为 false。 8 object this [T index] {get;set;} //索引器,得到或设置某个索引的项 9 //公有方法 10 int Add(object value); //添加某项到表中,返回被插入的新项 11 //在表中的位置。 12 void Clear(); //清空表。 13 int IndexOf(object value); //如果表中有与 value 相等的项, 14 //返回其在表中的索引,否则,返回-1。 15 bool Contains(object value); //如果表中有与 value 相等的项, 16 //返回 true,否则为 false。 17 void Insert(int index,object value); //把值为 value 的项插入到索 18 //引为 index 的位置。 19 void Remove(object value); //删除表中第一个值为 value 的项。 20 void RemoveAt(int index); //删除表中索引 index 处的项。 21 }
4.3:NET 框架中的一些集合类实现了 IList 接口,如 ArrayList、ListDictionary、StringCollection、StringDictionary。下面以 ArrayList 为例进行说明,其它类的具体情况读者可参看.NET 框架的有关书籍。ArrayList 类使用数组来实现 IList 接口,所以 ArrayList 可看作顺序表。ArrayList 的容量可动态增长,通常情况下,当 ArrayList 中的元素满时,容量增加一倍,把原来的元素复制到新的空间中。当在 ArrayList 中插入一个元素时,该元素被添加到 ArrayList 的尾部,元素个数自动加 1。另外,需要注意的是,ArrayList 中对元素的操作前提是 ArrayList 是一个有序表,但 ArrayList 本身并不一定是有序的。所以,在对 ArrayList 中的元素进行操作之前,应该对 ArrayList进行排序。
4.4:在 C# 2.0 中不仅提供了非泛型的 Ilist 接口,而且还提供了泛型 Ilist 接口。泛型 Ilist 接口是从 Icollection 泛型接口继承而来,是所有的泛型表的基接口。实现泛型 Ilist 接口的集合提供类似于列表的语法,包括在列表中任意点访问个别项以及插入和删除成员等操作。
4.5:型的 Ilist 接口的声明如下:
1 public inrterface Ilist<T> : Icollection<T>,Ienumerable<T>, 2 Ienumerable 3 { 4 //公有属性 5 T this [int index] {get;set;} //索引器,得到或设置某个索引的项 6 //公有方法 7 int IndexOf(T value); //如果表中有与 value 相等的项,返回 8 //其在表中的索引,否则,返回-1。 9 Void Insert(int index,T value); //把值为 value 的项插入到索 10 //引为 index 的位置。 11 Void Remove(T value); //删除表中第一个值为 value 的项。 12 }
4.6:List<T>优点
List<T>是 ArrayList 在泛型中的替代品。List<T>的性能比 ArrayList 有很大改变,因为动态数组是.NET 程序使用的最基本的数据结构之一,它的性能影响到应用程序的全局。例如,以前 ArrayList 默认的 Capacity 是 16,而 List<T>的默认 Capacity 是 4,这样可以尽量减小应用程序的工作集。另外,List<T>的方法不是虚拟方法(ArrayList 的方法是虚拟方法),这样可以利用函数内联来提高性能(虚函数不可以被内联)。List<T>也不支持问题很多的 Synchronized 同步访问模式。
五:总结
线性表是最简单、最基本、最常用的数据结构,线性表的特点是数据元素之间存在一对一的线性关系,也就是说,除第一个和最后一个数据元素外,其余数据元素都有且只有一个直接前驱和直接后继。
线性表有两种不同的存储结构,即顺序存储结构和链式存储结构。顺序存储的线性表称为顺序表,顺序表中的存储单元是连续的,在 C#语言中用数组来实现顺序存储。链式存储的线性表称为链表,链表中的存储单元不一定是连续的,所以在一个结点有数据域存放数据元素本身的信息,还有引用域存放其相邻的数据元素的地址信息。单链表的结点只有一个引用域,存放其直接后继结点的地址信息,双向链表的结点有两个引用域,存放其直接前驱结点和直接后继结点的地址信息。循环链表的最后一个结点的引用域存放头引用的值。
对线性表的基本操作有查找、插入、删除等操作。顺序表由于具有随机存储的特点,所以查找比较方便,效率很高,但插入和删除数据元素都需要移动大量的数据元素,所以效率很低。而链表由于其存储空间不要求是连续的,所以插入和删除数据元素的效率很高,但查找需要从头引用开始遍历链表,所以效率很低。因此,线性表采用何种存储结构取决于实际问题,如果只是进行查找等操作而不经常插入和删除线性表中的数据元素,则线性表采用顺序存储结构;反之,采用链式存储结构。