神经网络(Neural Network)是一种模仿生物神经网络构造的数学模型。很多文章喜欢从生物的神经元结构方面入手,展开对人工神经网络的介绍。但那样会引入更多意味不明的单词,比如突触,树突,轴突……所以这里并不会深入的介绍生物的神经网络是怎么工作的,只会说明为什么人工神经网络要构造成这样。本文按照时间顺序依次介绍神经网络中的几个重要概念,并在当中穿插一些思考,大致分为以下几个部分:
- MP神经元
- 感知机
- 多层前馈神经网络
- 误差逆传播算法(BP算法)
- 总结
1. MP神经元
MP神经元是神经网络的基本零部件,可以说神经网络就是神经元连接而成的网。理解神经网络,MP神经元是绕不开的。
MP神经元模型在1943年就提出了,这是一个非常古老而经典的神经元模型,直到今天,我们仍然在使用这个神经元模型。MP神经元是模仿生物的神经元设计的:
- 模拟生物神经元中其他神经细胞给该细胞的刺激,值越大刺激越大;
- 模拟该细胞不同来源的刺激的敏感度;
- 用阈值 来描述激活该神经元的难易程度,越大越难激活;
- 用 来计算神经元的兴奋程度;
- 为激活函数,用来计算神经元的输出;
- 在MP神经元中,激活函数为阶梯函数。兴奋函数大于阈值输出1,小于阈值输出0;
下图是MP神经元模型的示意图:
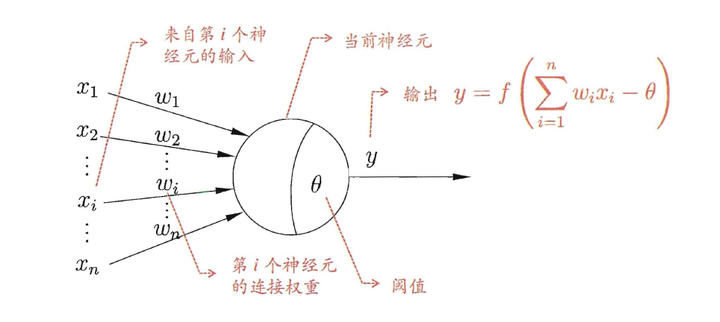 图1.来源:《机器学习》——周志华
图1.来源:《机器学习》——周志华
2. 感知机
由于MP神经元的输入来自于其他神经元,我们显然不能指望单独一个神经元就有什么功能。而多个神经元可以组成不同的结构,其中有一个叫做感知机。
感知机由输入和输出两层神经元组成,输入层有多个神经元,这些神经元只负责传递信号,没有任何其他功能;输出层只有一个MP神经元。这样的一个感知机可以用来做分类问题。
比如说它可以把 四个点分为两类。输入是一个坐标,所以输入神经元要有两个,这样的感知机结构图如下:
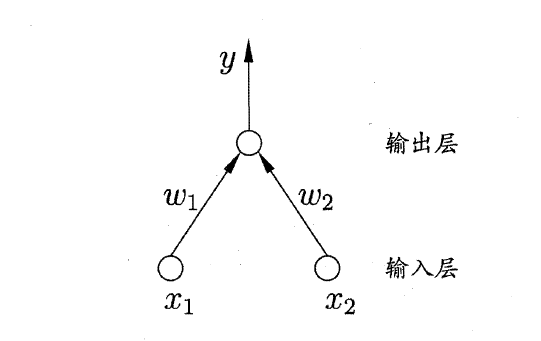 图2. 来源:《机器学习》——周志华
图2. 来源:《机器学习》——周志华
的感知机只在输入是 的时候激活。如果把0理解为假,1理解为真,那么这个感知机的功能就和与门是一样的,只有两个输入都是真的时候,输出真。而图像上,这个感知机实际上是一条线,把 分在一边,其他点分在另一边。
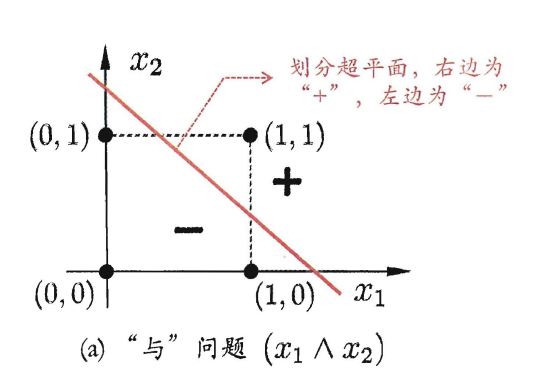 图3. 来源:《机器学习》——周志华
图3. 来源:《机器学习》——周志华
感知机的功能还挺强大的,才提出的时候,就可以用来对20*20像素的圆形,三角形以及正方形进行分类。那时候人工神经网络的研究可谓是风光无限,大量人员涌入,大量资本进入,就跟现在一样。
但感知机有一个巨大的缺陷。如果你仔细观察计算兴奋度的式子,就会发现它和最普通的线性模型几乎一样,只不过概念上使用了生物学的神经元模型来包装而已。实际上,感知机确实对非线性划分问题无能为力。
比如说异或计算问题:
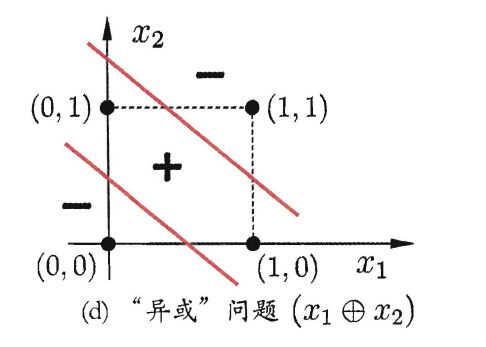 图4. 来源:《机器学习》——周志华
图4. 来源:《机器学习》——周志华
无论如何改变参数的值,都无法完成异或计算,这是因为无法在平面上找到一条直线把(0,1),(1,0)与(0,0),(1,1)分为两类。
所以说号称模拟生物神经元开发而来的人工MP神经元,连异或这种基本的非线性分类都做不到。这使得MP神经元的局限非常大,简直致命。而这个局限,被明斯基以一种充满敌意的方式呈现在了书中,直接导致神经网络的研究步入寒冬。
3. 多层前馈神经网络
说实话,现在往回看,研究停滞这件事的出现多少有点不可思议。
从生物学上来讲,绝大多数生物都拥有不止一个细胞,当单个MP神经元出现局限的时候,很自然的会想到在感知机的基础上加更多的神经元,看看是否会让感知机变得更加强大。
从逻辑计算的角度上来讲,已知感知机可以实现与、或、非门。那么用多个感知机构造一个异或门,讲道理不是什么难事。
而实际上只要在感知机的基础上再加一层神经元就可以进行异或的运算了。如下图:
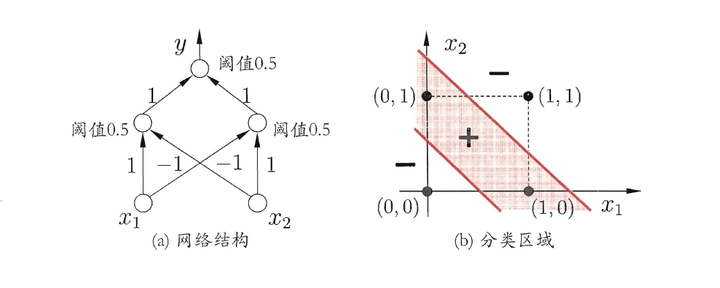 图5. 来源:《机器学习》——周志华
图5. 来源:《机器学习》——周志华
上面的这个网络结构,箭头上的1和-1是权重w,大家可以把四个点带进去试试,确实可以成功的进行异或运算。而这种在感知机上多加一层神经元组成的网络,就是我们的主角——多层前馈神经网络,简称神经网络。
功能上来看,这个神经网络已经足够强大了,不过这种结构下有两个问题是难以回答的:
- 这网络是什么意思?
- 参数如何训练?
因为输出只有0和1,那么参数的变化并不一定会导致网络整体输出的变化。比如说,将上图的阈值0.5换为0.1甚至0.000001,他还是能够进行异或运算。这种改变了参数,输出却没有变化的情况,会对我们理解网络造成困难,进而导致模型训练困难。因为参数改变了结果也不变,那么在结果不理想的情况下,我们该如何调整参数?变大?还是变小?还是怎么办?这是一个问题。
造成这个问题的原因是阶梯函数是一个不连续不可导的函数,用他作激活函数使得输出只有0,1两种,很僵硬。解决起来也简单,换一个激活函数就好。
这里不能用线性函数,因为用线性函数作为激活函数的神经元,再多个,再多层,连接起来,最终网络的整体输出Y,一定可以写成一个关于输入X的线性函数。也就是说全部使用线性函数作为激活函数的神经网络,无论多少层都只是一个结构更加复杂的线性模型,实际功能上和感知机没有任何区别。
那应该使用什么函数呢?首先线性是行不通了,那他起码是一个非线性函数。而阶梯函数这种的又会导致理解困难,所以他最好还是一个连续的函数。回顾过往的研究,我们恰好有一个这样的函数,他就是Sigmoid函数。该函数有非常多的优点,它非线性,连续,可导,导数好求,求出来的结果还不复杂。表达式如下:
现在我们把图5中所有神经元的激活函数都换成Sigmoid函数,它所呈现的结构就是多层前馈神经网络的基本结构了。下面给出多层前馈神经网络的具体解释:
多层指的是:在输入层及输出层中间还有拥有激活函数的激活层,隐含层至少一层,也可以有多层,也就是说一个多层前馈神经网络最少有三层,多则没有上限。示意图如下:
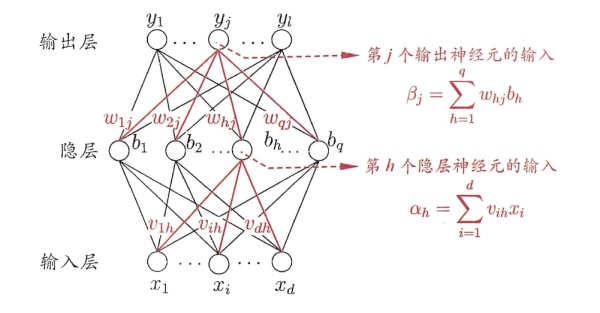 图6. 来源:《机器学习》——周志华
图6. 来源:《机器学习》——周志华
上图中的 代表隐层输入权重, 代表输出层输入权重,本文讨论的重点就是上图这种单隐含层神经元的网络,也叫三层神经网络。
前馈指的是:由于该网络每层神经元与下一层神经元全互连,同层神经元之间不互连,也不会跨层连接,所以信息只会按照信息只能按照输入—>隐藏—>输出的方向传递,得名前馈。
那么费劲半天,又是多加层神经元,又是寻找理想的激活函数,终于构造出这么个网络,有多牛逼?这些努力值得吗?
非常值,有理论证明,一个具有有限数目神经元的单隐层多层前馈神经网络可以以任意精度逼近任意复杂度的连续函数。换句话说,单隐层神经网络可以学习任意连续函数。如果我们把生活的问题全都理解为函数,中译英其实就是输入中文,输出英文的函数;P图就是输入原图,输出美图的函数;语音识别就是输入语音,输出文字的函数;那么单隐层网络,理论上,可以解决这些问题。有多牛逼?大概就是为所欲为的那种程度的牛逼吧。
理论很丰满,现实很骨干,这个理论上存在的参数该如何取得可是难为了人们好多年,直到BP算法的出现,训练的问题才算是找到了合理的解。
4. 误差逆传播算法(BP算法)
在介绍BP算法之前,我想先解释清楚为什么训练神经网络是一件难事。这对我们理解BP算法起到至关重要的作用。
和训练线性模型一样,训练神经网络本质上也是要找到一组参数 ,使得代价函数最小。通常来讲,都是用梯度下降法来解决这个问题。既然是梯度下降,那就求参数偏导数不就可以解决了吗,Sigmoid导数性质那么好,这又什么难度?
难度来自于神经网络的特殊结构。神经网络的全互联结构,使得神经网络有着数量庞大的参数总量,这无疑会降低网络训练速度。而神经网络的层级结构,使得它的输出y是一个复合了好几次的复合函数。如果我们直接求导,那么根据链式求导的规则,每一个参数的偏导数会写成一个看起来就很复杂的式子,中间不仅有乘法,有括号,还有求和符号 ,毫无疑问这样的公式算起来效率是很低的。所以问题不是别的,就是求各个参数的偏导太慢了。因此我们需要一个更加高效的方法来求偏导,而这个高效的方法就是BP算法。
BP算法:英文名:Error Back Propagation。译文:误差逆传播算法。由于其缩写是BP算法,所以也有称这个为反向传播算法的。
在解释BP算法为什么快之前,首先让我们回归问题本源:找到一组参数 使得整体的输出值与实际值的误差最小。
在这句话中默认了一个条件:有一组理想化的参数 可以使得误差最小。而现在之所以有这么大的误差,就是因为目前这组 和理想的 之间不一样。但是整体上的认知并没有什么意义,我们想知道每一个参数偏差了多少,便于我们调整。说起来这个过程,特别像比赛结束后的分锅大会,赛后采访教练团说的“这次比赛失利是教练组和全体队员的失利”,这种结论是毫无营养的,观众更希望分锅到户。
讨论如何分锅就必须要分析锅从何而来,整体分析是困难的,不妨从单独一个参数入手进行分析,比如说:在图6中,如果 的值与理想值不同,假设差异为 ,这里的误差会造成隐层第h个神经元的输出 产生 的误差。而 又是所有输出层神经元的输入,所以会影响到所有输出层神经元的输出,最终造成总代价产生 的误差。
对于每个参数来说都是如此,本身的误差会它连接的神经元开始,一层一层的向前传递,传到输出层,最终导致代价函数的值产生变化。既然锅是一层一层的传过来的,那么在分锅的时候,就自然而然的会想到反向一层一层的把锅分回去。而每一层的误差确实可以用上一层(上指的是更靠近输出端)的误差来表示。我们只要从输出层开始往回一层一层捋,捋一遍就可以把锅分明白。这就是反向传播的基本思想。
但是这和快速求导有什么关系?这是因为偏导数可以看成误差的度量。
现在思考这样一个问题,已知一组 的值,并且知道此时代价函数的值,我们可以人为的调整其中某个参数的值来降低代价,该怎样做?根据上面的式子 ,我们只需要将 的符号与参数偏导的符号设置成相反的,就可以降低代价。在 一定时,偏导数越大,代价变化越大,偏导数越小,代价变化越小。在这种情境下,我们可以把参数的偏导看作误差的度量。因为偏导越大,产生的误差就越大。
所以说偏导数的计算也可以按照分锅的思路,从代价函数->输出层->隐层,一层一层反向传播,每一层的偏导数都用上一层的偏导数来表示,以此通过一次反向传播就把所有参数的偏导数都求解出来。这就是BP算法快速求导的原理。
至于公式推导这里就不抄书了,有兴趣的可以看看《机器学习》中的推导。
实际上关于BP算法还可以从编程的角度上来解释,把求导理解为寻路,说不定理解起来更加轻松,具体的解释知乎中就有,大家可以自行搜索。
这里执意使用误差来解释,一是因为大部分学习资料没有覆盖到这种解释,而不解释的推导看起来和链式法则直接求导没有什么区别,这给BP算法的理解造成了不小的困扰;二是因为这种解释可以更深入的了解神经网络。比如说,都说梯度爆炸和消失会导致网络训练困难,但是这是为什么?而理解了误差,就可以解释了,因为梯度爆炸会导致该参数对代价函数产生极大的影响,而梯度消失则意味着该参数无法对代价函数产生影响。
偏导数计算出来后,训练就是梯度下降法,这里的梯度下降和线性回归中的没什么区别,如果你对此不太了解,可以参照这个连接:https://wasedamagina.github.io/archives/。
5. 总结
- MP神经元是神经网络的基本单元。
- 虽然感知机无法处理非线性问题,但是在感知机的基础上再加一层神经元就可以了。这种多层的结构,就是神经网络的雏形。
- 多层前馈神经网络指的是有至少一个隐含层,且每层神经元与下一层神经元全互连,同层神经元之间不互连,也不会跨层连接的神经网络。神经网络一般指代这种网络。
- BP算法是一种快速求导的方法。
- 误差是一层一层向前传递的,所以也可以反向逐层表示。
- 可以把偏导数理解为误差的度量,按照误差逆传播的思想来逐层计算偏导数。