Redis集群是Redis提供的分布式数据库方案,集群通过分片来进行数据共享,并提供复制和故障转移功能 。
一个redis集群一般由多个节点构成,节点和节点之间的关联通过CLUSTER MEET指令进行实现。
初始化三个redis节点

查看三个节点的对外地址

执行「docker inspect redis-node1」得到 redis-node1 ip 信息为:172.17.0.2
执行「docker inspect redis-node2」得到 redis-node2 ip 信息为:172.17.0.3
执行「docker inspect redis-node3」得到 redis-node3 ip 信息为:172.17.0.4
进入某一个容器 docker exec -it redis-node1 /bin/bash
组建集群,10.211.55.4为当前物理机的ip地址 redis-cli --cluster create 10.211.55.4:6379 10.211.55.4:6380 10.211.55.4:6381 --cluster-replicas 0

简单测试一下
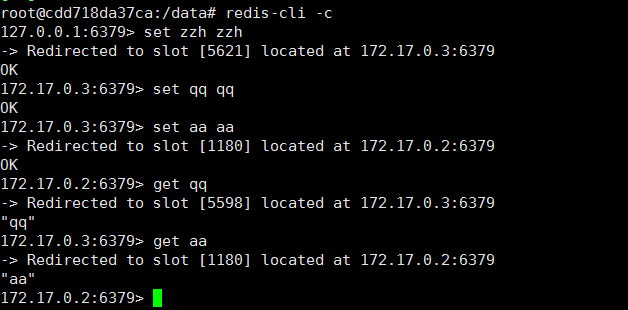
这样就算一个docker的spdemo完成了。
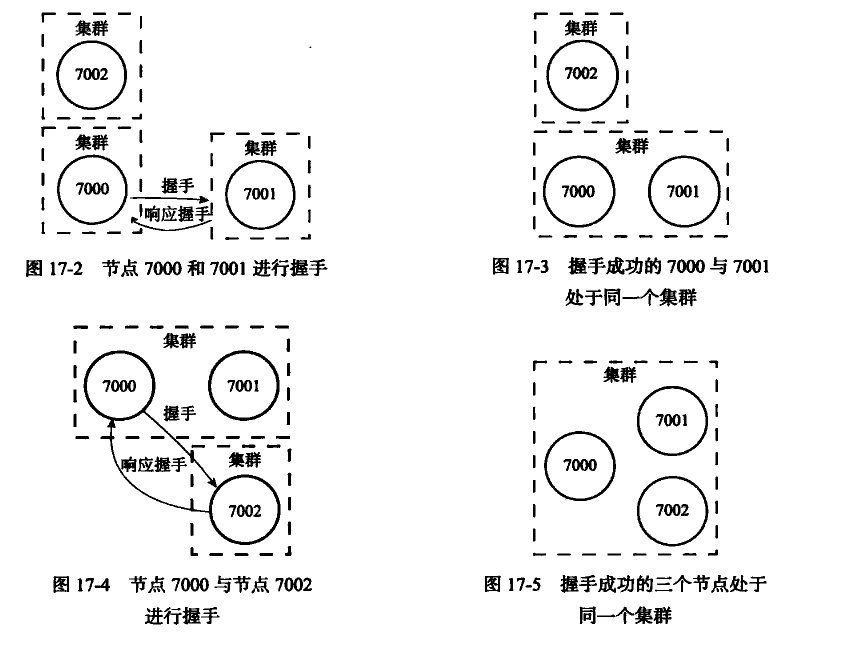
当你是用CLUSTER MEET的时候,会让节点和指定的ip:port的节点进行握手连接。形成一个新的集群。
一个节点就是运行在集群模式下的Redis服务器,在服务器启动的时候会根据cluster-enabled配置选项是否为yes,来决定是否开启服务器的集群模式
在集群模式下的redis依然可以做一个普通redis服务器能做的事情,依然可以进行指令的接收和返回。会继续执行ServerCron函数来进行RDB检查等操作,同时也会调用集群模式特有的ClusterCron函数(向其他的节点发送Group问候,对下线的节点进行自动故障转移等)包括持久化以及发布和订阅都会正常的进行。
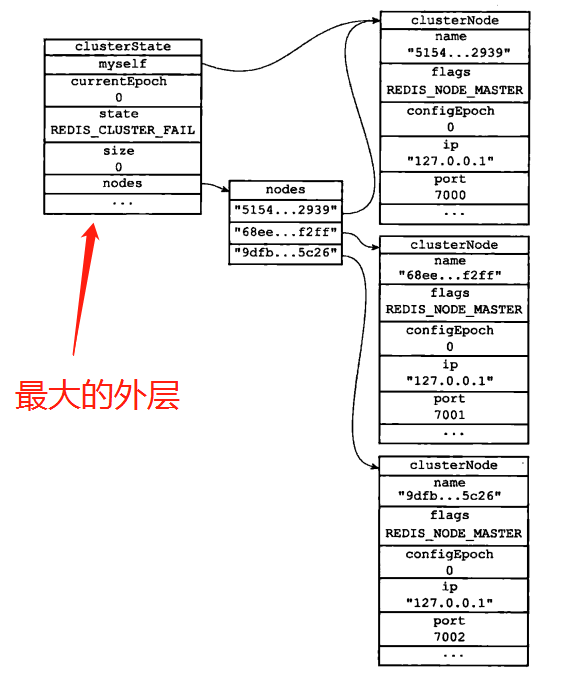
在集群模式下,对应的信息会被存储在服务器的cluster.h这个文件的结构中
clusterNode结构保存了一个节点当前的状态,比如节点的创建时间,节点的名字,节点当前的配置纪元,节点的IP和端口号。

clusterNode结构中的link属性是一个clusterLink结构,保存了所需的相关信息,比如套接字描述,输入缓冲区,输出缓冲区。

clusterLink中的中的套接字和缓冲区是用来连接节点的,而RedisClient中的是用来连接客户端的。
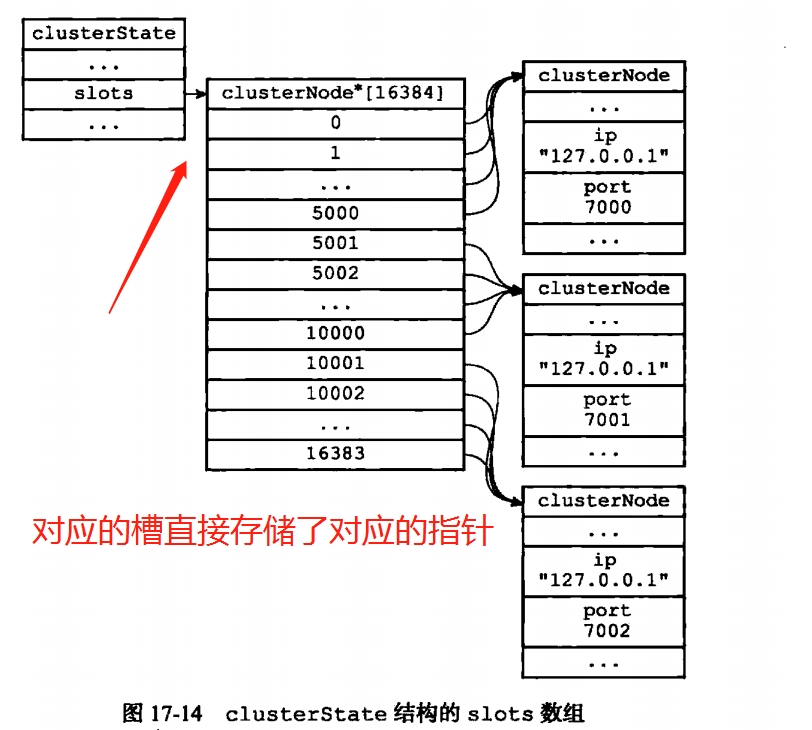
卡斯特State结构记录了集群目前所处的状态,例如集群是在线还是下线,包含着多少个节点

7000 7001 7002的集群的对应的clusterState对应的实际存储的结构。
Cluster meet命令的详细执行流程:
CLUSTER MEET <IP><PORT>的第一步就是先给要创建的节点设置一个ClusterNode的结构,并且将对应的信息填充到Node字典中。
然后会根据IP和PORT也就是B,发送一条Meet消息,如果B收到meet消息,也会为A创建一个ClusterNode结果,放到自己的Node字典中。
之后向A节点返回一条pong消息,然后A收到后再返回一个ping。就是TCP/IP握手的正常流程。

Redis中通过分片的方式来保存数据库中的键值对,集群中的整个数据库被分为16384个槽,也就是2的14次方数据库中的每个键都是属于这16384槽中的一个,集群中的每个节点都可以处理0-16384个槽。如果这些糙是在处理的阶段那么这个集群则是上线的阶段。通过CLUSTER ADDSLOTS<slot>[]就可以进行嘈的分配。通过cluster info可以查看到对应的集群情况

在clusternode这一结构中的numslots属性记录了对应节点分配的槽的分配信息,numslots是一个16384大小的数组,1表示负责这个槽,0表示不负责这个槽。

槽的作用之一就是用来规划某个节点应该负责的内容,简单的说就是槽告知了某个节点应该负责多少,当消息进入集群的时候就会经过一系列算法,转化为0~16384中的一个数值,这个数值就是槽的代表,然后发给对应的节点。在ClusterState中记录了所有槽的分配的信息,ClusterNode要使用只能进行遍历才可以知道所有的槽的分配,而ClusterState则可以直接知道。
命令被集群处理的具体的执行流程如下所示

在redis内使用CRC16算法对命令中的value值进行槽计算,最终计算出一个位于0~16383之间的数组,在计算出槽值之后,节点就会检查自己的clusterState中的slots数组来项i判断这个槽是否自己负责。如果不是自己处理的就会向客户端返回MOVED错误,指引客户端转向正在处理的节点。例如Set data aa,发送给节点7000.7000节点会计算这个data对应的槽值应该是多少,例如计算出是200,然后7000节点会检查自己的clusterState中的slots[200]来判断这个节点是不是由自己进行负责,如果是自己负责那么就会进行处理,如果不是的话就会slots[200]找到这个对应的指针,然后找到对应的clusterNode。然后给客户端发送一个MOVED错误,并告知正确的节点以及端口。让客户端向这个节点发送对应的请求。当然这个错误是我们看不见的也就是隐藏起来的MOVED。所谓的转向其实就是换一个套接字。


注意的一点就是节点服务器只会使用0号数据库,单机模式下的数据库则可以使用正常的,默认下就是可以使用0-15号数据库。
如果槽已经分配完成,这时候又添加进了新的节点,那么就会进入一个重新分配的动作,这个动作是由redis-trib负责执行的。redis-trib通过对源节点和目标节点进行发命令来进行实现重新分配。
1.目标节点准备好从源节点导入属于槽slot的键值对
2.源节点准备好将属于槽slot的键值对迁入至目标节点
3.获取到count个属于槽slot的键值对的键名
4.将选中的键原子地从源节点迁移到目标节点
5.重复执行3和4


在Redis中的节点分为主节点和从节点,主节点用于处理槽而从节点则用于复制某个主节点,并在被复制的主节点下线时,代替下线节点继续处理命令请求。
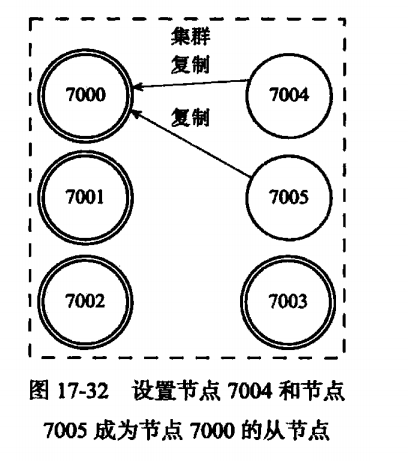
这样的话如果7000下线了,就可以在7004,7005里面选取一个节点作为主节点,另外一个节点则会成为新节点的从节点进行复制功能。

主从的设计很符合天然的树状,也就是每一个节点其实的内容都是一样的。如果最头部的挂了,下面的节点可以很好的进行读,但是写就全部无效。特别很明确。主节点收到消息之后分发给从节点,然后从节点可以进行全量也可以进行增量。如果是广播的话,对应的网络资源的消耗也不会特别大。可以很好的分散读写压力,但是有个缺陷就是主节点的压力依然挺不住,如果主节点挂了,那么整个系统就无法继续进行下去了。Master Server是以非阻塞的方式为Slaves提供服务。所以在Master-Slave同步期间,客户端仍然可以提交查询或修改请求。Slave Server同样是以非阻塞的方式完成数据同步。在同步期间,如果有客户端提交查询请求,Redis则返回同步之前的数据。主机宕机,宕机前有部分数据未能及时同步到从机,切换IP后还会引入数据不一致的问题,降低了系统的可用性。
Sentinel,三铁no,是主从的一个升级的版本,我是这么理解的,牺牲一部分资源来完成主节点的高可用,当然问题就是一个服务器依然需要所有的数据。一致性方面其实还是不错的。至少下弱一致性这个级别的。redis较难支持在线扩容,在集群容量达上限时在线扩容变的很复杂。Redis主机宕机后,哨兵模式正在投票选举的情况之外,因为投票选举结束之前,谁也不知道主机和从机是谁,此时Redis也会开启保护机制,禁止写操作,直到选举出了新的Redis主机
Cluster 可以认为是真正的打散了压力,这个也导致数据不会单一的存在一个主节点上,一致性方面进一步变弱,可用性方面加强。理论上Sentinel和Cluster结合的方式是最好的。