特征处理相关的算法,大体分为以下三类: 特征抽取:从原始数据中抽取特征
特征转换:特征的维度、特征的转化、特征的修改
特征选取:从大规模特征集中选取一个子集
#导入相关的库
from pyspark.ml.feature import HashingTF,IDF,Tokenizer
from pyspark.sql import SparkSession
#创建SparkSession对象spark = SparkSession.builder.master('local').appName('TF-DF').getOrCreate()
#创建一个DataFrame, 每个句子代表一个文档
sentenceData = spark.createDataFrame([
(0,"I heard about Spark and I love Spark"),
(0,"I wish Java could use case classes"),
(1,"Logistic regression models are neat")]).toDF("label","sentence")
#用tokenizer对句子进行分词tokenizer = Tokenizer(inputCol="sentence", outputCol="words")
wordsData = tokenizer.transform(sentenceData)
#用HasdingTf的transform方法把句子哈希成特征向量,这里的哈希表的桶数设为2000hashingTF = HashingTF(inputCol="words", outputCol= "rawFeatures",numFeatures=20)
featurizeData = hashingTF.transform(wordsData)
#用IDF来对单纯的词频特征向量进行修正,使其更能体现不同词汇对文本的区别能力,IDF是一个Estimator,调用fit()方法并将词频向量传入,即产生一个IDFModel。idf = IDF(inputCol="rawFeatures", outputCol="features")
idfModel = idf.fit(featurizeData)
#IDFModel是一个Transformer,调用它的transform()方法,即可得到每一个单词对应的TF-IDF度量值。rescaledData = idfModel.transform(featurizeData)
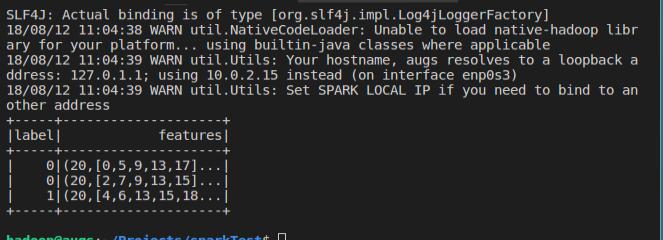
rescaledData.select("label","features").show()
效果: