TCP传输的数据单元是报文段,报文段分为首部、数据两部分
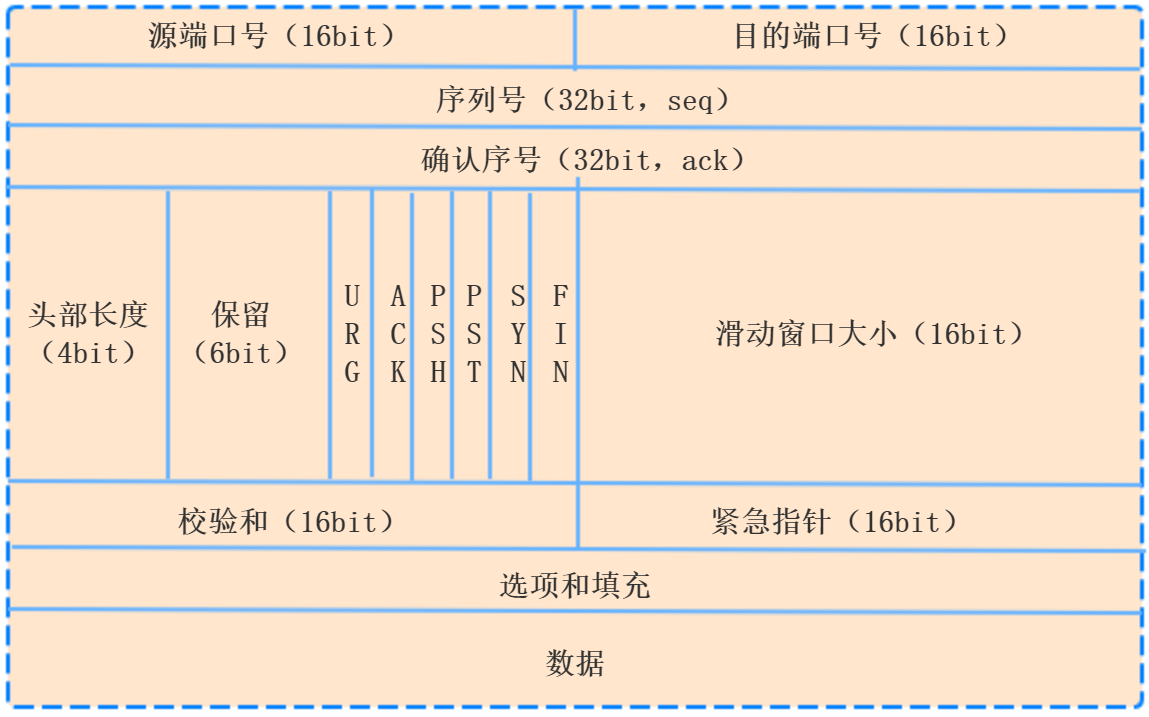
TCP首部
首部的前20字节是固定长度,后面的4n字节根据需要增加的选项
字段解释:图中标示单位为bit,不是byte
1、源端口、目的端口:占用2byte,实现分用功能(TCP通过端口把请求分发到应用层不同的应用程序)
2、序号:占用4byte,范围[0,2^32-1],序号增加到最大,就会重新回到0,也就是使用的mod2^32运算
TCP面向字节流的,同一个TCP连接中传送的字节流中每个字节都是按照顺序编号,整个要传送的字节流的初始序号在连接建立的时候设置,首部
中的序号指的是本报文段所发送的数据的第一个字节的序号。
3、确认号ack:占用4byte,指的是希望收到对方的下一个报文段的首个字节的序号
4、数据偏移:占用4bit,指的是TCP报文段首部的长度,因为选项的长度不确定,所以数据偏移的存在是很有必要的,数据偏移的最大长度
60byte,所以选项的长度不超过40byte
5、保留:占6bit
6、紧急URG(URGent):当URG=1时,紧急指针字段有效,应用程序告诉TCP发送端有紧急数据需要发送,于是TCP把紧急数据插入到本报文段数据
的最前面,后面的数据仍然是普通数据,需要和紧急指针配合使用
7、确认ACK:ACK=1生效,在连接建立之后发送的所有报文段ACK都要置为1
8、推送PSH:发送方把PSH置为1,并立即创建一个报文段发送出去,接收方收到PSH=1的报文段,就尽快的交付给应用程序,不需要等到整个接
收缓存填满之后再向上交付。但是很少使用
9、复位RST:当RST=1时,表明TCP连接出现严重差错,必须释放连接,然后重新建立连接,还可以用来拒绝一个非法的报文段或者拒绝打开一
个非法连接。RST也称为重置位或重建位
10、同步SYN:在连接建立时同步序号。
11、终止FIN:用来释放一个连接
12、窗口:占用2byte,指的是发送方的接收窗口,而不是发送窗口。
窗口值的作用就是:
从本报文段的首部确认号开始,接收方允许发送报文的数据量,之所以有这个限制,这是因此接收方的数据缓存是有限的。
窗口值作为接收方让发送方设置其发送窗口的依据。
13、检验和:占用2byte,通过加上伪首部,检验首部和数据
14、紧急指针:占用2byte,只有URG=1才有效,指的是紧急数据的大小,紧急数据末尾在报文段的位置,窗口为0的时候也可以发送紧急数据。
15、选项:长度可变,最大40byte
cwnd:发送端窗口(congestion window)
rwnd:接收端窗口(receiver window)
最大报文段长度MSS:实际指的是TCP报文段中数据字段的最大长度,MSS尽量大一点,只要在网络层传输不需要分片就行
可靠传输的工作原理
TCP发送的报文段交给IP层传输,网络层提供不可靠的服务,所以,TCP必须采用合适的措施使得两个运输层之间的通信变得可靠
理想的传输条件:
1).传输信道不产生差错
2).不管发送方发送数据的速度有多快,接收方总能来得及接收数据
A是发送方,B是接收方
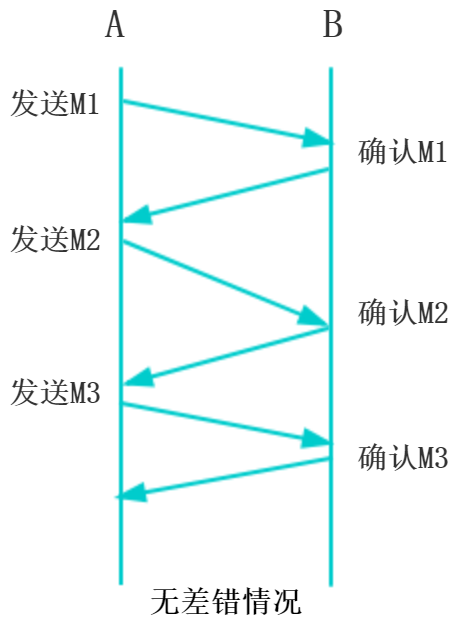
这种理想情况下才不需要采取措施实现可靠传输,然后实际上不是这样的,需要可靠性传输协议
停止等待协议:
传输的数据单元称为分组,每发送一个分组就停止发送,知道得到对方的确认,然后再发送下一个分组
超时重传:
为每个发送的分组设置一个超时计数器,A只要经过一段时间没有收到确认,就认为刚才的分组丢失,重新发送刚才的分组
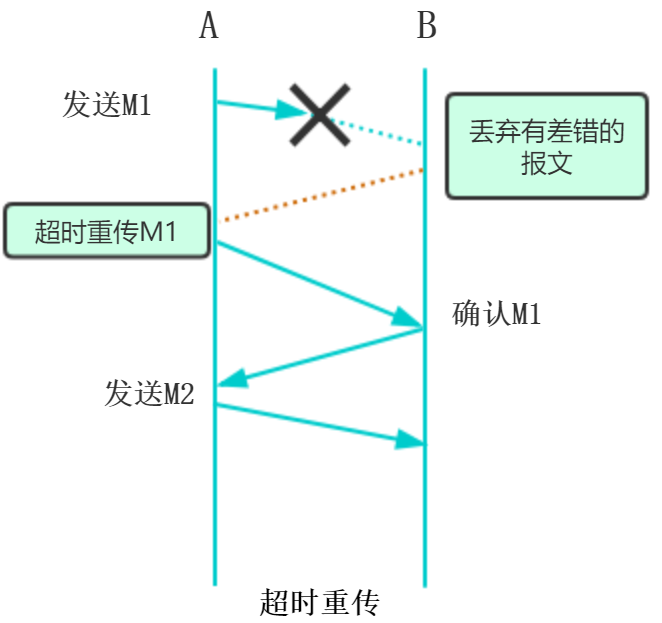
确认丢失:
确认丢失了,A没有收到,重新发送给B一个分组,B又收到重传的分组M1,要采用两个行动:
1).丢弃这个重复的分组
2).向A发送确认
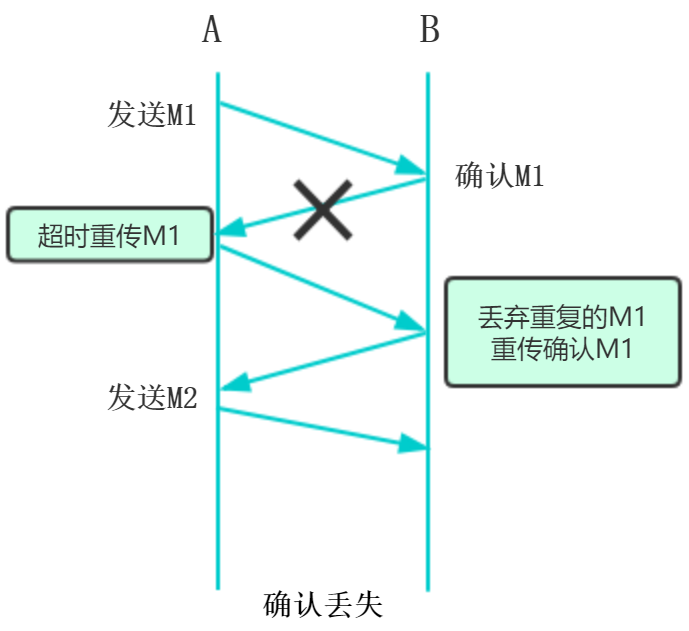
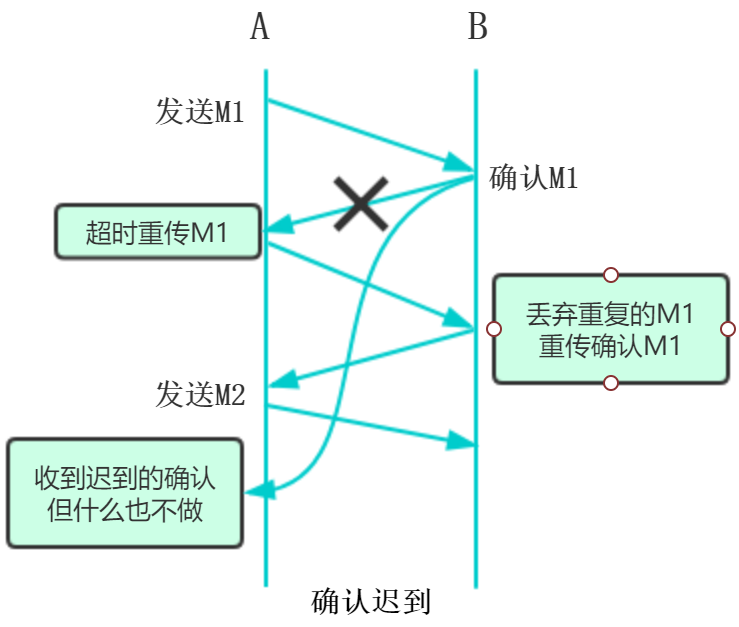
确认迟到:
A收到重复的确认立马丢弃,B收到重复的分组,也要丢弃,并且重新确认分组
上述的可靠性传输协议就是自动重传请求(ARQ Automatic Repeat reQuest),在不可靠的网络环境实现可靠的通信
总结:
重传的请求是自动进行的,接收方不需要主动要求发送方重传某个错误的分组
停止等待协议优点就是简单,但是信道利用率太低,为了提高利用率,发送方可以不使用等待停止协议,采用流水线传输,
就需要了解连续ARQ协议和滑动窗口协议
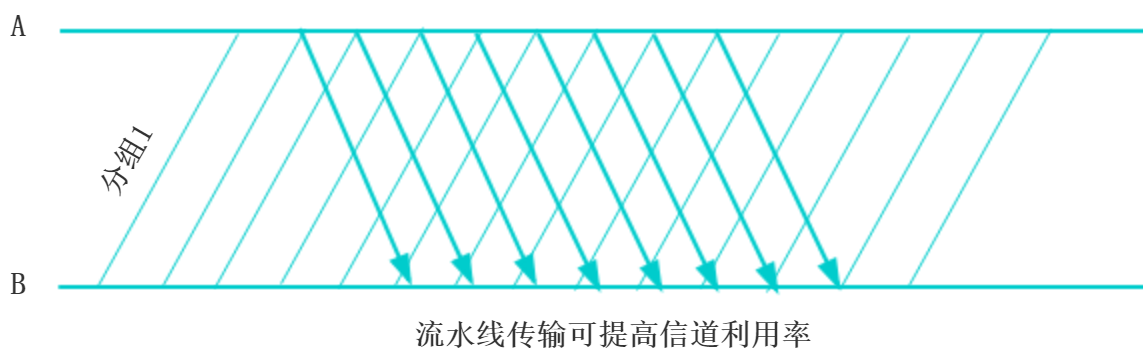
连续ARQ协议
位于发送窗口中的每个分组都可以按顺序连续发送出去,不需要等待对方的确认,这样信道的利用率就提高了
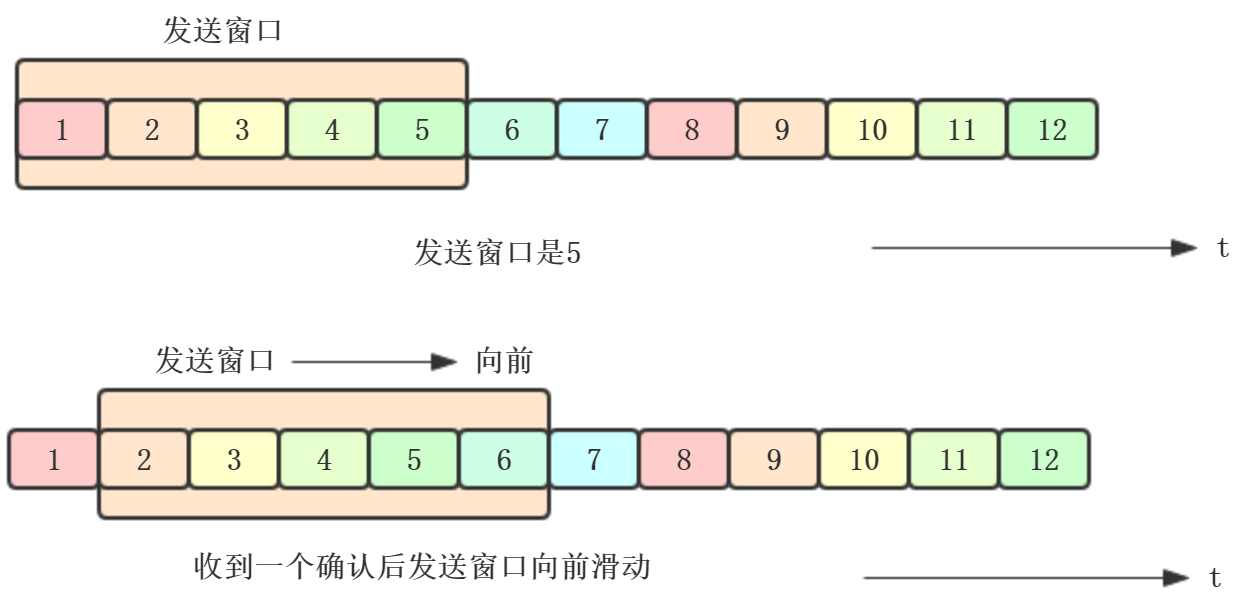
发送方:每收到一个确认,发送窗口向前滑动一个分组的位置
接收方:不必对收到每个分组逐个发送确认,而是在收到几个分组后,对按次序到达的最后一个分组发送确认,就表示:到这个分组为
止之前的所有分组都收到了,这就是累计确认
滑动窗口
以字节为单位,已经发送的数据,在没收到确认的时候,都要暂时保存,以便超时重传。后沿后面的部分都是已发送且收到确认。后沿只
能不动或者前移。前沿的前面部分是不允许发送的,可以前移、不动、后移(不建议)
例如:A收到B发来的确认报文段,如下图
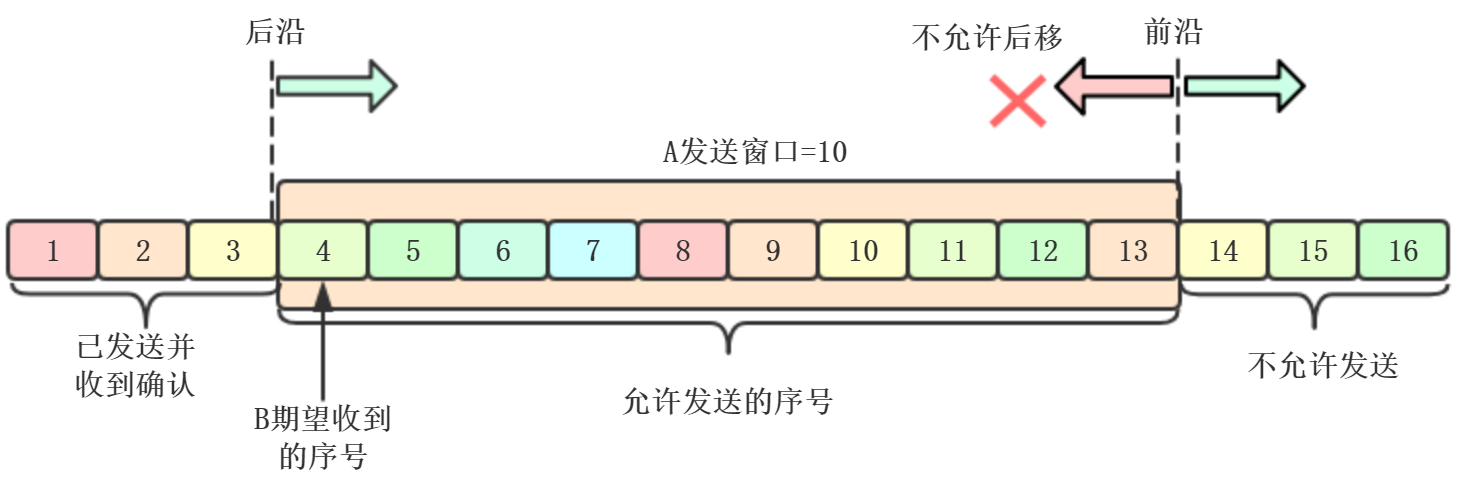
发送窗口的序号表示允许发送的序号。窗口越大,发送方就可以在收到对方确认之前发送更多的数据,因此可以获得更高的传输效率。接收
方会把自己的接收窗口数值放到窗口字段中发给对方。所以,A的发送窗口一定不能大于B的接受窗口数值。除此之外,发送窗口还受到网络拥塞
程度的影响
现在假设A发送了序号4 - 13的数据,发送窗口位置不变,但发送窗口内有5个字节(红色部分4 - 8)是已发送但未收到确认,而前面5个字节
(9 - 13)允许发送但尚未发送
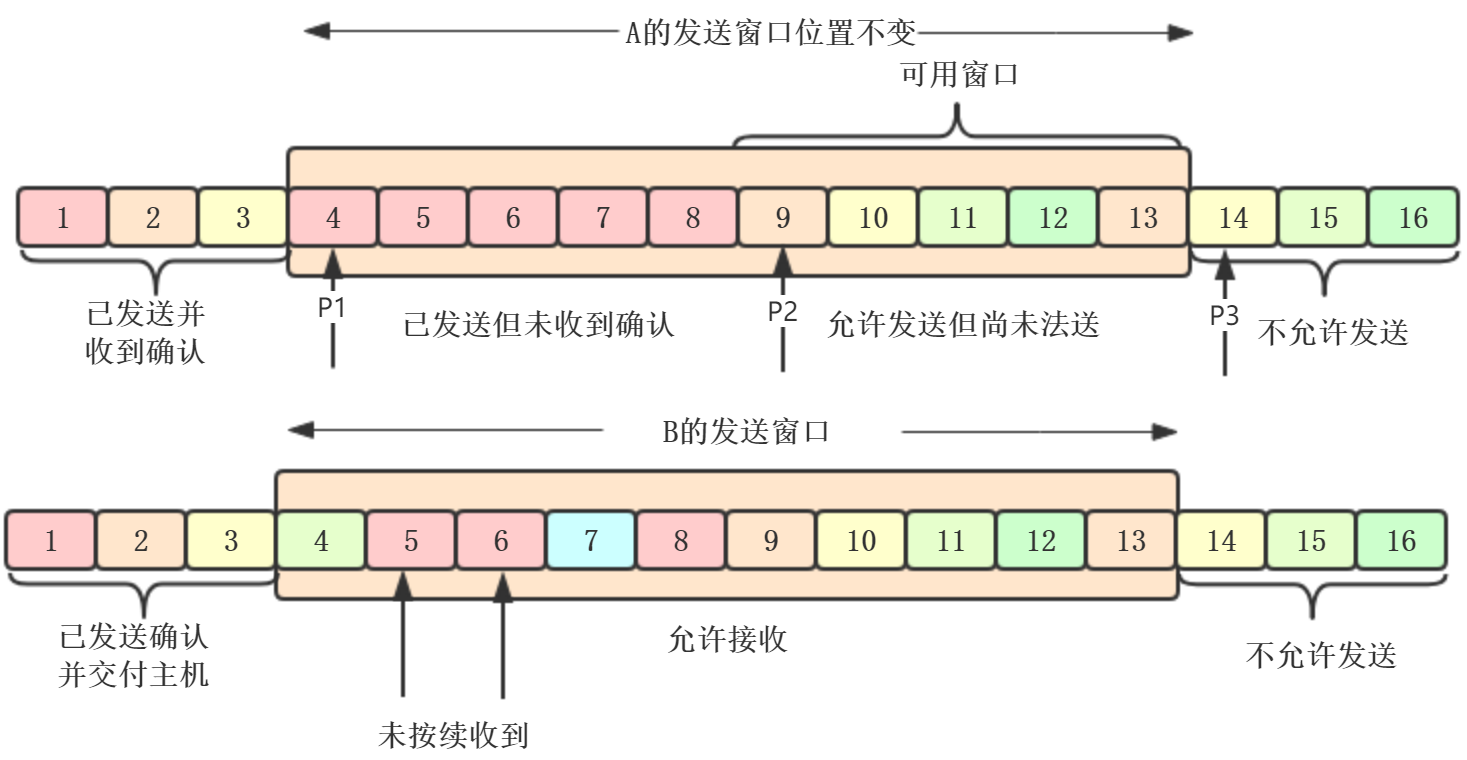
上图中,P1,P2,P3分别代表着:
P3-P1=A的发送窗口
P2-P1=已发送但未收到确认的字节数
P3-p2=允许发送但尚未发送的字节数,也称为可用窗口
B的接收窗口:
接收窗口大小为10,接受窗口4 - 13是允许接收的,B收到5和6的数据,但是4的数据没收到(丢失了,或者滞留在网络某节点),数据没按顺序
到达,B只能对按序到达的数据中的最高序号进行确认,因此B发送的确认报文段中确认号还是31(即期望收到的序号),而不能是5或6
假如,A最终把9-13也发送成功,P2和P3重合,可用窗口为0,B发送了确认,但是滞留在网络中,为了保证可靠传输,A只能认为B还没收到,超
时过后进行重传(超时计数器控制时间),之后重置计数器,直到收到B确认位置
发送/接收的缓存和窗口
图咱就不画了,应该能看懂,画图真的花时间的。如果实在看不懂,自己看书,在《计算机网络第七版》P223
发送方的应用程序把字节流写入TCP的发送缓存,接收方的应用程序从TCP的接收缓存中读取字节流
发送缓存:
1、应用程序传送给发送方TCP准备发送的数据
2、已发送但尚未收到确认的数据
发送窗口是发送缓存的一部分,已确认的数据从缓存中删除。发送方应用程序必须控制写入缓存的速率,否则没有空间存放
接收缓存:
1、用来存放按序达到的,但未被接收方应用程序读取的数据
2、为按序到达的数据
如果收到的分组检测出有误差,直接丢弃。如果接收方应用程序来不及读取收到的数据,接收缓存会被填满,接收窗口就为0了,反之,接收
窗口会变大,但不能超过接收缓存的大小。
注意点:
1、不按序到达的数据如何处理,无明确规定。通常先临时存放在接收窗口中,等到缺少的字节到达后,再按序交付上层的应用程序
2、TCP要求接收方有累计确认的功能,这样可以减少传输开销
3、TCP的通信是全双工通信,每一方都有自己的发送窗口和接收窗口,要搞清楚
超时重传时间的选择:我选择放弃,你们自己看吧。。。
选择确认SACK:
当收到的报文段没有差错,只是未按照序号,中间缺少一些序号的数据,通过SACK只传送缺少的数据
TCP的流量控制
点对点通信量的控制
1、利用滑动窗口实现流量控制
让发送方的发送速度不要太快,能让接收方来得及接收
ACK表示标志位,ack表示确认字段的值
利用滑动窗口机制很方便在TCP连接上实现对发送方的流量控制

PS:上面第二行,A发送序号101到200,应该是还能发送200字节,笔误了
在连接建立的时候,B告诉A(rwnd=400),发送方的cwnd不能超过接收方给出的rwnd的范围,TCP的窗口单位为字节,不是报文段
上面这个流程应该很好理解了。。。
上述流程存在一个问题:B向A发送rwnd=0的报文段后,B的接收缓存又有了新的空间,发送rwnd=400,但是丢失了,这时候A等待B发送非零
窗口的通知,B等待A发送数据,可能导致死锁。这个问题通过持续计数器解决
持续计数器工作原理:
只要收到零窗口报文段,就会启动,设置的时间到期后,发送一个探测报文段,对方收到后给出现在的窗口值,如果为零,重置时间,
不为零,打破死锁
2、TCP的传输效率
通过TCP中广泛使用的Nagle算法和解决糊涂窗口综合征的方式配合使用,最终达到:发送方不发送很小的报文段,接收方也不会有一点小的窗口
大小信息就通知对方
2、TCP的拥塞控制
拥塞:网络中某一资源的需求超过该资源所能提供的可用部分,性能就会变差,也就是对资源的需求 > 可用资源
1、一般原理:
防止过多的数据注入到网络,这样就可以使网络中的路由器或链路不至于过载,是一种全局性的过程
流量控制:
点对点通信量的控制,是抑制发送端发送数据的效率,以便接收端来得及接收
拥塞控制和流量控制最简单的对比:一台计算机传输数据和500台计算机传输数据(考虑的是整个网络的负载能力)的区别
出现网络拥塞的因素很多:
1).当某个节点缓存的容量太小,到达该节点的某些分组会被丢弃,简单的扩大缓存空间无法解决拥塞问题,可能导致网络的性能更差
2).处理机处理的效率太慢
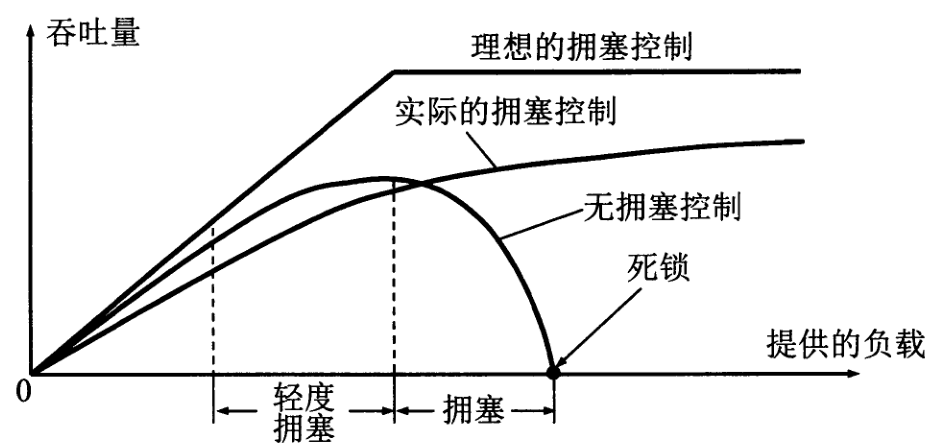
在网络负载的增加,吞吐量的增加速率逐渐减少。为达到饱和,有一部分输入分组被丢失了。当网络进入拥塞时,吞吐量还会下降,设置降到
零,出现死锁
2、拥塞控制方法:
基于窗口的拥塞控制:发送方维护一个拥塞窗口的状态变量。大小取决于网络的拥塞程度,动态变化。发送方让发送窗口等于拥塞窗口
控制拥塞窗口的原则:如果网络没有发生拥塞,可以把拥塞窗口设置大一点,以便发送更多的分组,提高网络利用率,但是如果发生拥塞,
就是减少拥塞窗口的大小,减少注入到网络中的分组,以便缓解网络中的拥塞。
判断发生网络拥塞的依据就是出现超时,不考虑丢弃分组
3、TCP基于拥塞控制的算法有以下四种:
3.1).慢开始
从小到大逐渐增大发送窗口,也就是组件增加拥塞窗口的值,从cwnd初始为1开始启动,指数启动只有在TCP连接建立和网络出现超时时才
使用。每经过一个传输轮次,拥塞窗口 cwnd 就加倍。一个传输轮次所经历的时间其实就是往返时间RTT。不过“传输轮次”更加强调:把拥塞
窗口cwnd所允许发送的报文段都连续发送出去,并收到了对已发送的最后一个字节的确认。
另外,慢开始是指在TCP开始发送报文段时先设置cwnd=1,使得发送方在开始时只发送一个报文段(目的是试探一下网络的拥塞情况),然后
再逐渐增大cwnd。为了防止拥塞窗口cwnd增长过大引起网络拥塞,还需要设置一个慢开始门限ssthresh状态变量(如何设置ssthresh)。
慢开始门限ssthresh的用法如下:
当 cwnd < ssthresh 时,使用上述的慢开始算法。
当 cwnd > ssthresh 时,停止使用慢开始算法而改用拥塞避免算法。
当 cwnd = ssthresh 时,既可使用慢开始算法,也可使用拥塞控制避免算法。
3.2).拥塞避免
让拥塞窗口cwnd缓慢增大,每经过一个往返时间RTT就把cwnd+1,而不是加倍,线性规律缓慢增加,到达ssthresh后,为了避免拥塞开始尝试
线性增长
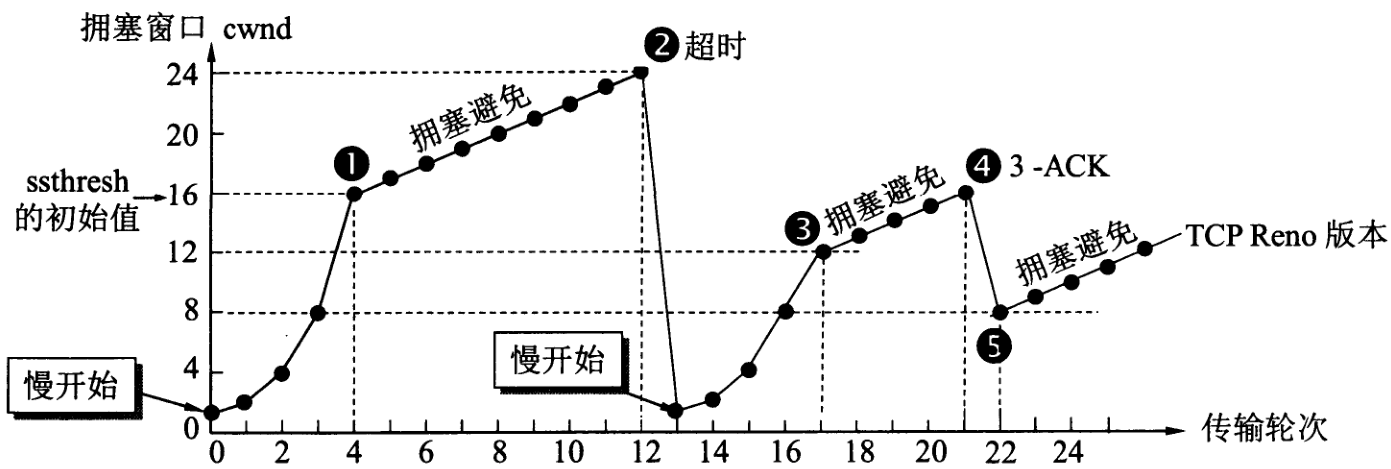
我用的画图工具几乎没法画折线图,只能直接截图了,大家凑活看吧
无论在慢开始阶段还是在拥塞避免阶段,只要发送方判断网络出现拥塞(超时),就要把慢开始门限ssthresh = cwnd/2(但不能小于2)。
同时设置cwnd = 1,执行慢开始算法。
个别报文段在网络中丢失,但实际上网络并没有发生拥塞。发送发收不到确认,就会产生超时,被误认为网络拥塞,这样就会产生问题。
为了解决这个问题使用快重传算法,可以让发送方尽早知道有个别报文段丢失
拥塞控制并不能完全避免拥塞
3.3).快重传
首先要求接收方每收到一个失序的报文段后就立即发出重复确认(为的是使发送方及早知道有报文段没有到达对方),发送方只要一连收到三
个重复确认就知道接收方丢包了,快速重传丢包的报文,而不必继续等待M3设置的重传计时器到期。TCP马上设置cwnd = 1。由于发送
方尽早重传未被确认的报文段,因此采用快重传后可以使整个网络吞吐量提高约20%。
如果发送方知道只是丢失个别报文段,不启动慢开始,而是使用快恢复算法
3.4).快恢复
特点:
直接从ssthresh线性增长。
与快重传配合使用,其过程有以下两个要点:
1、当发送方连续收到三个重复确认,就执行“乘法减小”算法,把慢启动门限ssthresh减半。这是为了预防网络发生拥塞。请注意:接下
去不执行慢开始算法。
2、由于发送方现在认为网络很可能没有发生拥塞,发送方调整ssthresh = cwnd/2,同时设置cwnd = ssthresh,然后开始执行拥塞
避免算法,使拥塞窗口缓慢地线性增大。
拥塞控制流程图:
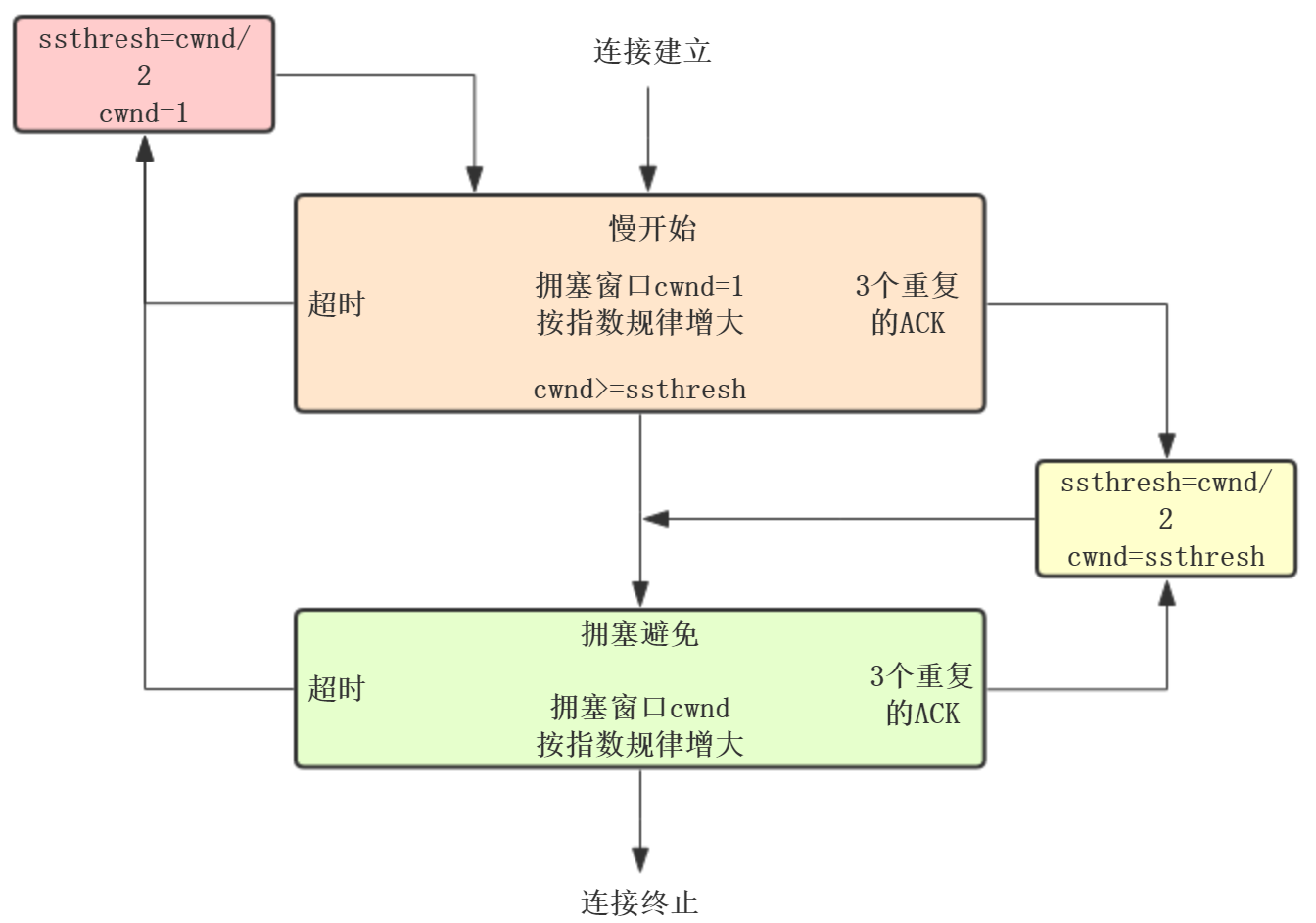
发送方窗口的上限值 = Min [ rwnd, cwnd ]
当rwnd < cwnd 时,是接收方的接收能力限制发送方窗口的最大值。
当cwnd < rwnd 时,则是网络的拥塞限制发送方窗口的最大值。
也就是说,rwnd和cwnd中min,控制发送发发送数据的速率
TCP运输连接管理
TCP三次握手
为了确保数据能到达目标,TCP协议采用三次握手
用户发送HTTP request通过TCP connection连接服务器,这个连接可以一直保持着的,第一个HTTP完成三次握手,第二个请求就不需要进行
三次握手了
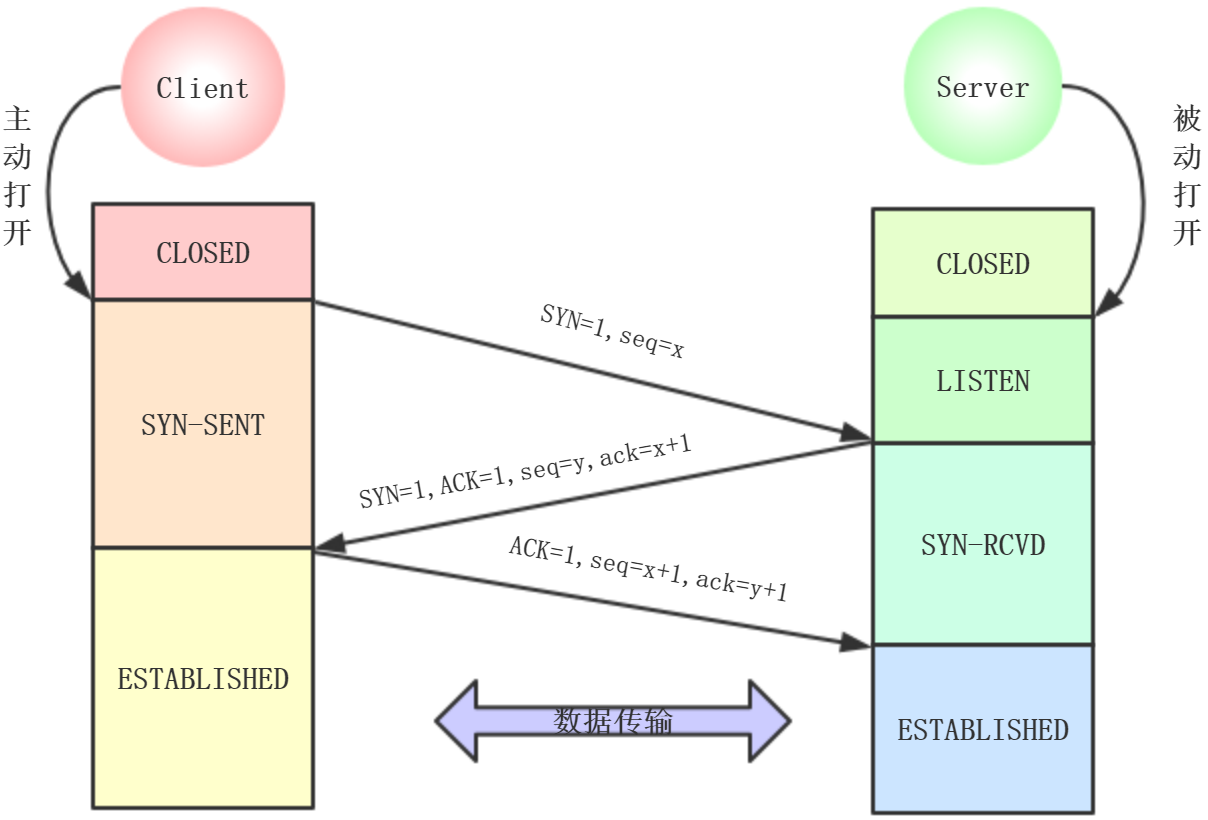
1、最开始两段TCP都是处于CLOSED,A主动打开连接,B被动打开连接
2、B的TCP服务器进程创建传输控制模块TCB,准备接收客户端的请求,处于LISTEN
3、A也创建TCB后
3.1).一次握手:A向B发送连接请求报文段,同步位SYN=1,选择一个初始序号seq=x。SYN报文段不能携带数据,但是消耗一个序号,然后处
于SYN-SENT状态
3.2).二次握手:B收到报文段,如果同意,发送确认报文段。SYN=ACK=1,确认号ack=x+1,为自己选择初始序号seq=y。这个报文段也不能
携带数据,也消耗一个序号,处于SYN-RCVD
3.3).三次握手:client收到Server的确认报文段,还要给Server返回确认报文段。ACK=1,ack=y+1,seq=x+1(ACK报文段可以携带数据,如果
不携带不消耗序号,所以,下一个数据报文段的序号还是x+1),这时Client处于ESTABLISHED,Server收到Client的确认报文之后,也处于
ESTABLISHED
第三次的作用:防止已失效的连接请求报文突然又传到接收方,就以为这是一个新的连接请求,而发送方并不承认这个请求,就会浪费这个连接
SYN攻击
在三次握手的过程中,当server发送ACK+SYN包给client,client发送ACK给server,在server还没收到的时候,这时的TCP连接称为半连接,
收到之后才是establish状态
SYN攻击就是伪造大量的虚假IP地址,不断向server发送SYN包,server恢复确认,并且等待确认返回,由于源地址都是虚拟的,server不断
发送SYN+ACK直到超时,这些SYN包将占用未连接队列,导致正常的SYN请求因为队列满了而被丢弃,从而引起网络阻塞甚至系统瘫痪
这是一种典型的DDOS攻击,检测的方式:当server有大量半连接状态且源IP地址都是随机的,可以断定遭到SYN攻击了。
为什么不是两次握手?
如果client发送的报文段没有丢失,而是在某个网络节点被滞留,然后过了一段时间传递到server,这时已经是一段过期的报文段,server
同意建立连接,而client现在并没有发送请求,不会发送请求,这样就会浪费server的资源,所以采用三次握手就可以避免这种情况
四次挥手:断开连接
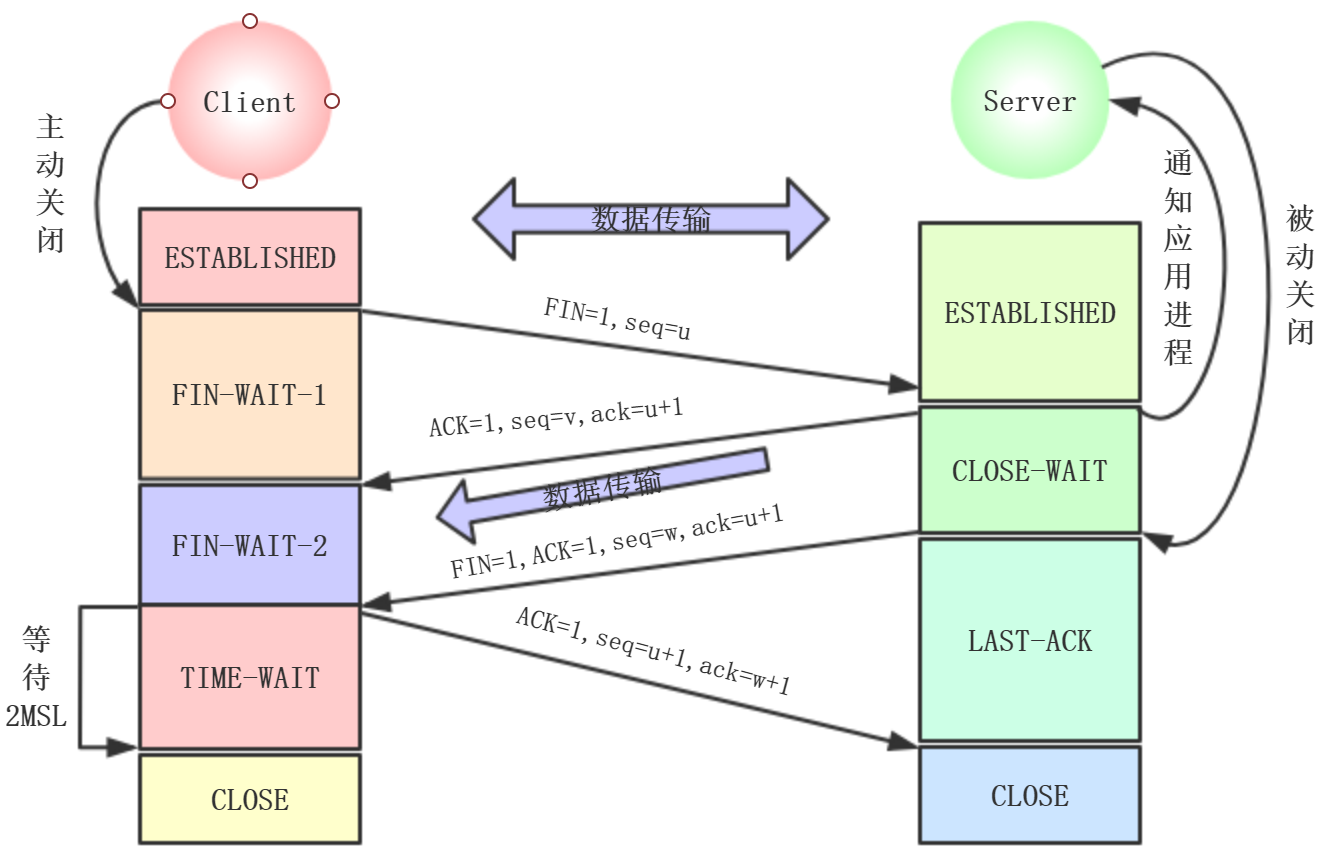
第一次挥手:
TCP发送一个FIN(结束,即使不携带数据,也要消耗一个序号),用来关闭客户端到服务端的连接。此时A处于FIN-WAIT-1状态。u等于前
面已发送过的数据的最后一个字节的序号+1。然后B进入CLOSE-WAIT状态,TCP服务器通知应用程序,从A到B的连接就释放了,此时TCP连接处
于HALF-CLOSE状态,但是B到A的连接没有关闭(Client是A,Server是B),这时如果B发送报文,A还是要接收的
第二次挥手:
B返回一个ACK(确认位),ack=u+1(FIN消耗一个序号)。v等于B之前已发送的数据的最后一个字节的序号+1。等待B发送连接释放报文段。
A收到之后处于FIN-WAIT-2
第三次挥手:
如果B不再向A发送数据,应用程序通知B释放连接,发送一个FIN=1,seq=w,ack=u+1到A,seq为w(因为HALF-CLOSE状态的B可能有发送一些数据
了),Server关闭Client的连接,B处于LAST-ACK。
第四次挥手:
A发送报文段到B,ACK=1,seq=u+1,ack=w+1。这时A处于TIME-WAIT状态。这时TCP连接还没有释放,经过2MSL(时间等待计时器设置的2MSL,MSL
是最长报文段寿命,建议设置2minute)后,A才进入CLOSED。之后才能创建新的连接。当A撤销TCB之后,结束这次TCP连接
为什么需要经过2MSL才进入CLOSED,原因:
1、为了保证A发送的最后一个ACK报文段能够达到B
2、防止已经失效的连接请求报文段出现在本连接中,这样可以使这次连接中产生的所有报文段从网络中消失
为什么是4次挥手呢,ACK和FIN不同时发送给client?
因为在关闭连接时,发送FIN给对方,只是表明我不想发送数据,但是我还是可以接收数据的,但是对方是否关闭发送数据通道,需要上层
应用层来决定,因此,ACK和FIN都是分开发送的
TCP的有效状态机
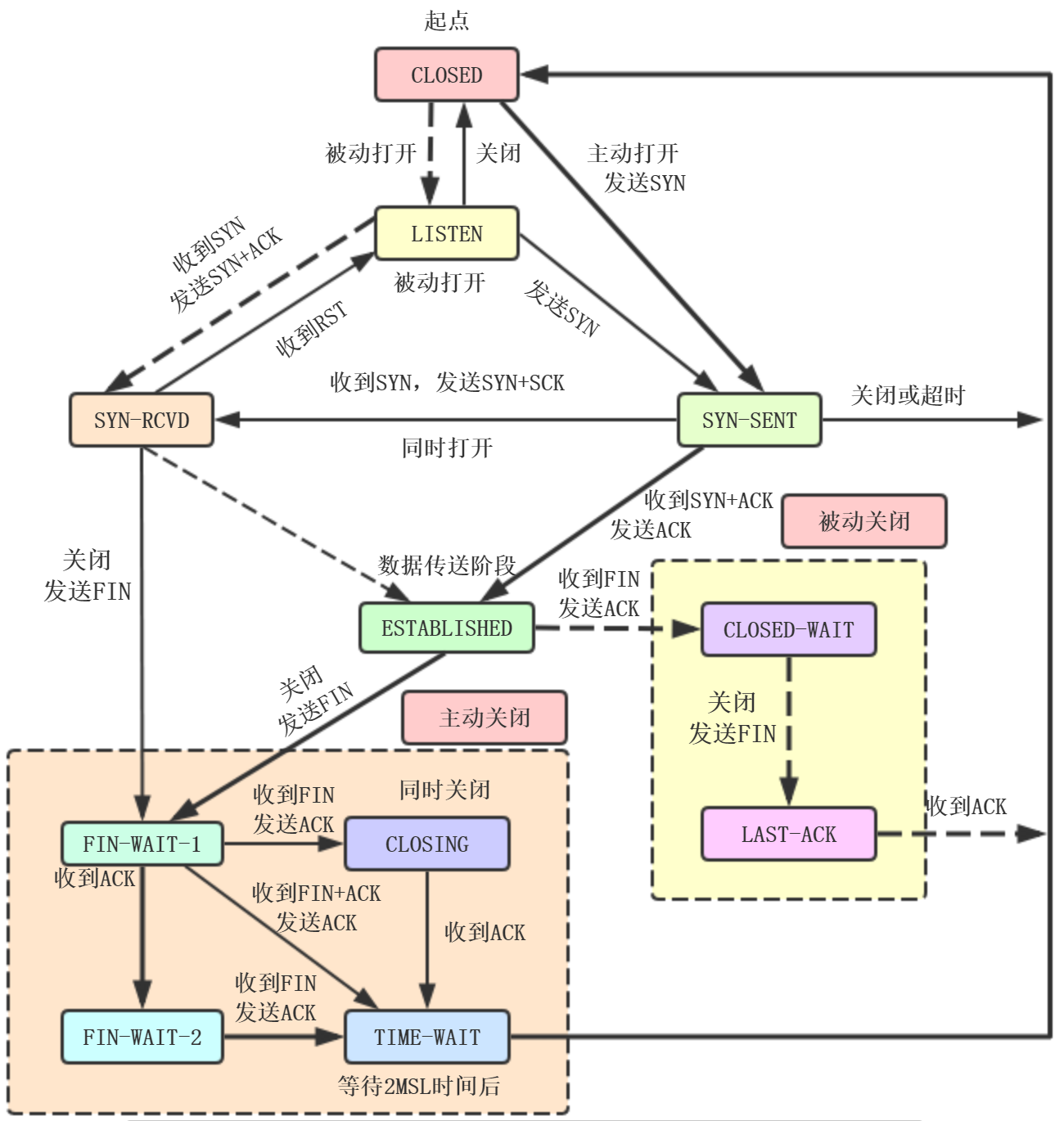
上图中,粗实线的箭头表示客户进程的正常变迁,虚线箭头表示服务器进程的正常变迁,细线箭头表示异常变迁。
什么是粘包、拆包?
TCP根据缓冲区的实际情况进行包的划分,业务上分为:
1、拆包:一个完整的包可能会被TCP分为多个包进行发送
2、粘包:多个小的包也可能被封装成一个大的包进行发送
粘包、拆包产生的原因?
1、应用程序写入的字节大小大于Socket发送缓冲区大小
2、进行MSS大小的TCP,MSS是最大报文段长度的缩写,是TCP报文段中的数据字段最大长度,MSS=TCP报文段长度-TCP首部长度
3、以太网的Payload大于MTU,进行IP分片,MTU是最大传输单元的缩写,以太网的MTU为1500字节
粘包、拆包解决策略
由于底层的TCP无法理解上层的业务数据,所以在底层是无法保证数据包不被拆分和重组的,这个问题只能通过上层的应用协议栈设计来解决,
根据业界的主流协议的解决方案,可以归纳如下:
消息定长,例如每个报文的大小固定为200字节,如果不够空位补空格
包尾增加回车换行符进行分割,例如FTP协议
将消息分为消息头和消息体,消息头中包含表示长度的字段,通常涉及思路为消息头的第一个字段使用int32来表示消息的总长度更复杂的应用
层协议
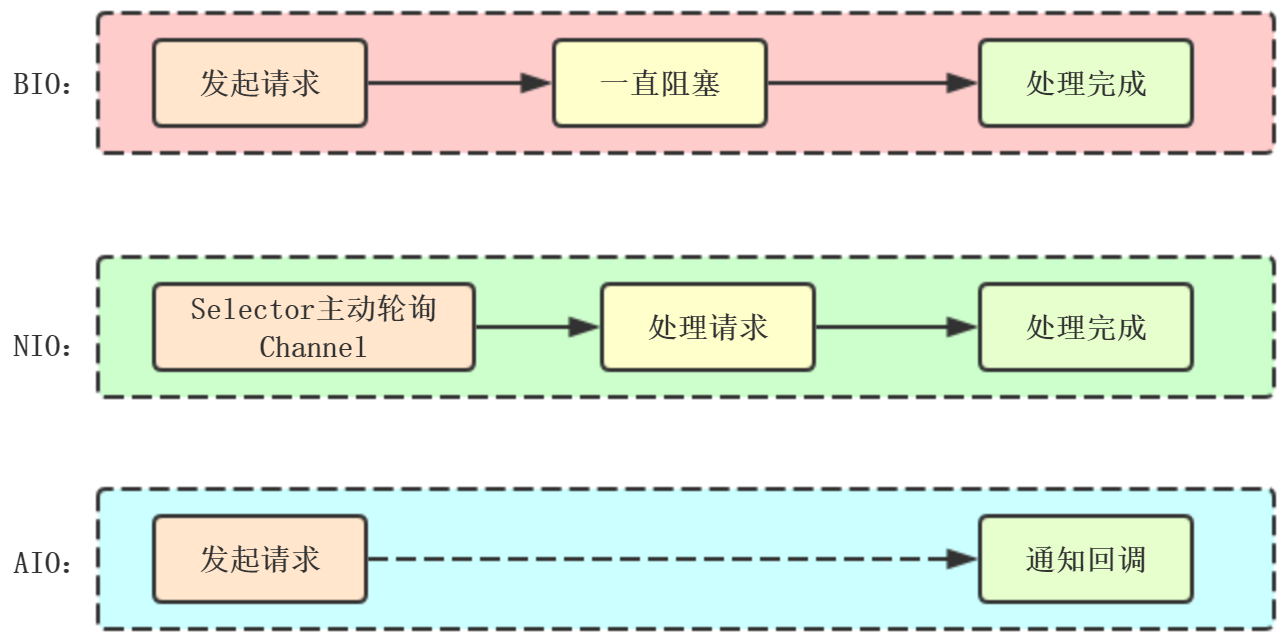
同步/异步/阻塞/非阻塞
同步阻塞:相当于一个线程在等待。
同步非阻塞:相当于一个线程在正常运行。
异步阻塞:相当于多个线程都在等待。
异步非阻塞:相当于多个线程都在正常运行。
IO分类:
BIO:同步阻塞IO
NIO:同步非阻塞IO jdk1.4
API相对复杂,需要熟悉多线程,内部存在bug,例如epoll bug,有可能selector空轮询造成100%CPU
AIO:异步非阻塞IO
内容参考:计算机网络(第七版)