CountVectorizer旨在通过计数来将一个文档转换为向量。当不存在先验字典时,
Countvectorizer作为Estimator提取词汇进行训练,并生成一个CountVectorizerModel
用于存储相应的词汇向量空间。该模型产生文档关于词语的稀疏表示,其表示可以传递给其他算法,例如LDA。
在CountVectorizerModel的训练过程中,CountVectorizer将根据语料库中的词频排序从
高到低进行选择,词汇表的最大含量由vocabsize超参数来指定,超参数minDF,则指定词
汇表中的词语至少要在多少个不同文档中出现。
#导入相关的库
from pyspark.sql import SparkSession
from pyspark.ml.feature import CountVectorizer
#配置spark
spark = SparkSession.builder.master('local').appName("CountVectorizerDemo").getOrCreate()
#创建DataFrame,可以看成包含两个文档的,迷你语料库
df = spark.createDataFrame([
(0, "a b c".split(" ")),
(1, "a b b c a".split(" "))
], ["id", "words"])
#过CountVectorizer设定超参数,训练一个CountVectorizer,这里设定词汇表的最大量为3,设定词汇表中的词至少要在2个文档中出现过,以过滤那些偶然出现的词汇
cv =CountVectorizer(inputCol="words", outputCol='features', vocabSize=3, minDF=2.0)
#生成一个model
model = cv.fit(df)
#使用这一模型对DataFrame进行变换,可以得到文档的向量化表示
result = model.transform(df)
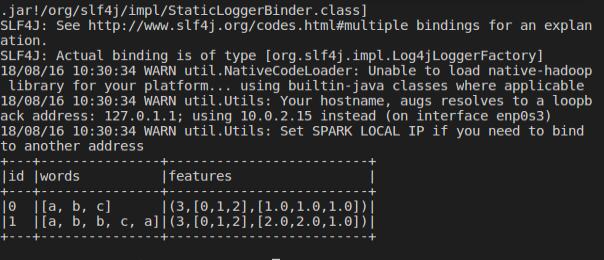
result.show(truncate=False)