| PSP2.1 | Personal Software Process Stages | 预估耗时(分钟) | 实际耗时(分钟) |
|---|---|---|---|
| Planning | 计划 | 40 | 50 |
| · Estimate | · 估计这个任务需要多少时间 | 40 | 50 |
| Development | 开发 | 300 | 820 |
| · Analysis | · 需求分析 (包括学习新技术) | 30 | 20 |
| · Design Spec | · 生成设计文档 | 20 | 10 |
| · Design Review | · 设计复审 | 10 | 20 |
| · Coding Standard | · 代码规范 (为目前的开发制定合适的规范) | 10 | 10 |
| · Design | · 具体设计 | 30 | 30 |
| · Coding | · 具体编码 | 150 | 400 |
| · Code Review | · 代码复审 | 30 | 30 |
| · Test | · 测试(自我测试,修改代码,提交修改) | 60 | 300 |
| Reporting | 报告 | 40 | 90 |
| · Test Report | · 测试报告 | 30 | 60 |
| · Size Measurement | · 计算工作量 | 10 | 10 |
| · Postmortem & Process Improvement Plan | · 事后总结, 并提出过程改进计划 | 10 | 20 |
| 合计 | 380 | 960 |
解题思路
对于这个题目来说读取字符数和行数是基本操作,题目的难点在于按照给定规则对文本进行划词,以及在单词数量大时如何保证词频查找更新的空间复杂度,一开始时我想直接使用标准模板库中的map来进行单词频率的存储,但后来查看其底层实现时发现C++的map是基于BST实现的。虽然每次查找有O(logN)的时间复杂度,但当单词数量大时,时间复杂度依然太高,后来在 畅畅 同学的提醒下,我使用基于哈希实现的unordered_map来存储单词及其词频,通过牺牲空间复杂度换取每次查找O(1)的时间复杂度。
接口设计与实现过程
需求分析:
-
读取txt文件中内容(基础功能)
-
统计文件的字符数(基础功能)
-
统计文件的单词总数(基础功能)
-
统计文件的有效行数(基础功能)
-
统计文中的各单词的出现次数,最终输出频率最高的10个(拓展功能)
-
接口封装(拓展功能)
实现过程
程序基本框架:根据需求分析我将整个程序划分为5个主体部分
-
文件读取与接口调用部分
-
字符数统计部分
-
行数统计部分
-
单词统计部分
-
单词词频统计部分
接口设计:
- 字符数统计部分:
int CountChar(char *filename) - 行数统计部分:
int CountLine(char *filename) - 单词统计部分:
int CountAllWords(char *filename) - 词频统计部分:
vector<pair<string, int>> top10words(char *filename)
各部分实现:
-
文件读取实现:通过使用C++的fstream类读取文件流
-
字符数统计部分:每次从文件流中读取一个字符并计数
-
行数统计部分:运用C++的getline函数从fstream对象中按行读取并计数
-
单词统计部分:首先需要按照规则划分出每个单词,其次对每个单词进行计数
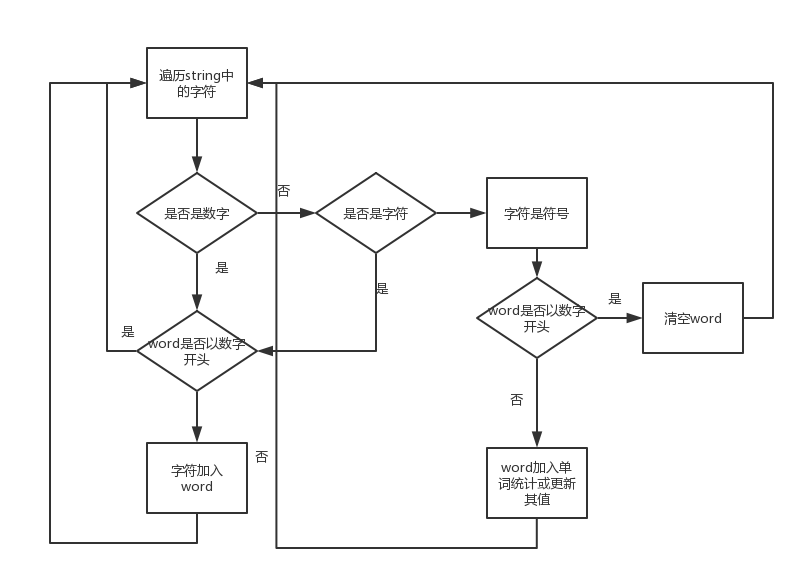
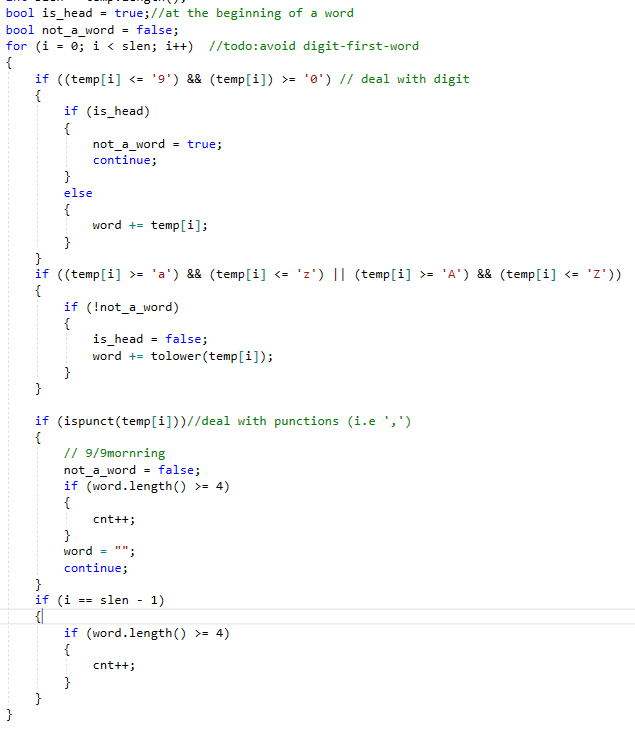
- 划分单词:根据C++ fstream类的get()方法在按string读取时会自动按空格划分的特点,首先读入由空格划分的字符串,在此基础上需要对这个字符串内部再进行切分比如出现‘hello,world’时,程序应该准确讲此字符串划分为‘hello’和‘world’,我采用的方法是通过遍历字符串,并设置is_head,not_a_word两个flag来完成string内划词的操作
- 流程图
- 核心代码
-
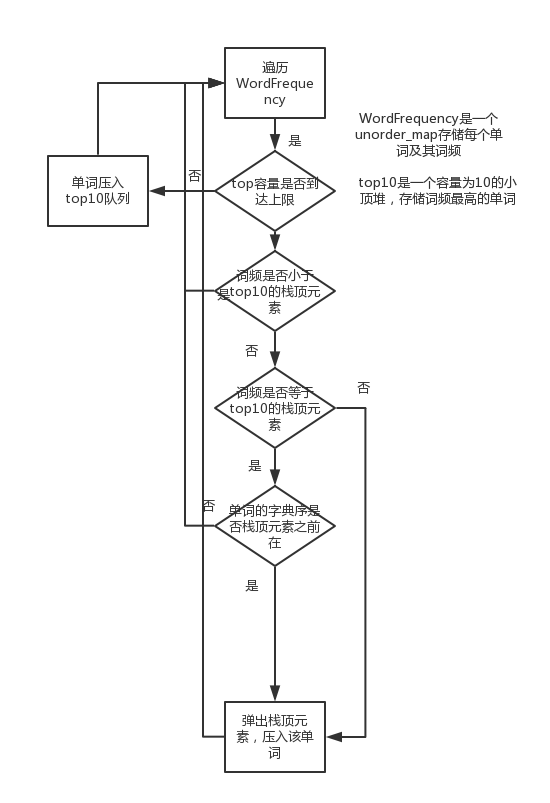
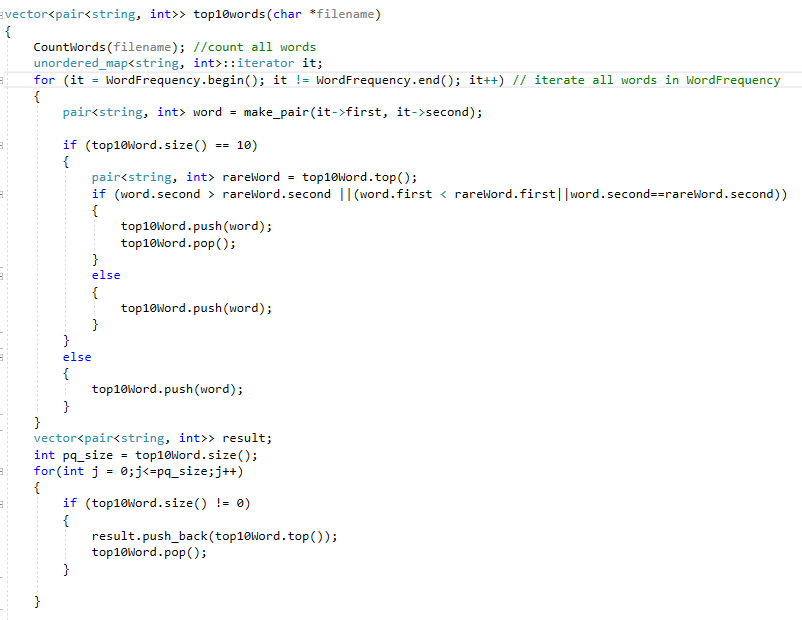
单词词频top10:使用基于priority_queue实现的小顶堆来维护top10词频队列,当队列中元素不足十个时直接入队,当队列中满时,对栈顶元素与欲入队元素进行比较,首先比较词频,词频相同比较字典序
- 流程图
- 核心代码
- 流程图
性能分析及改进
在性能分析中我循环执行如下文本1000000次
h
e
l
l
o
hello
hello123
123hello
hello
HELLO
123file
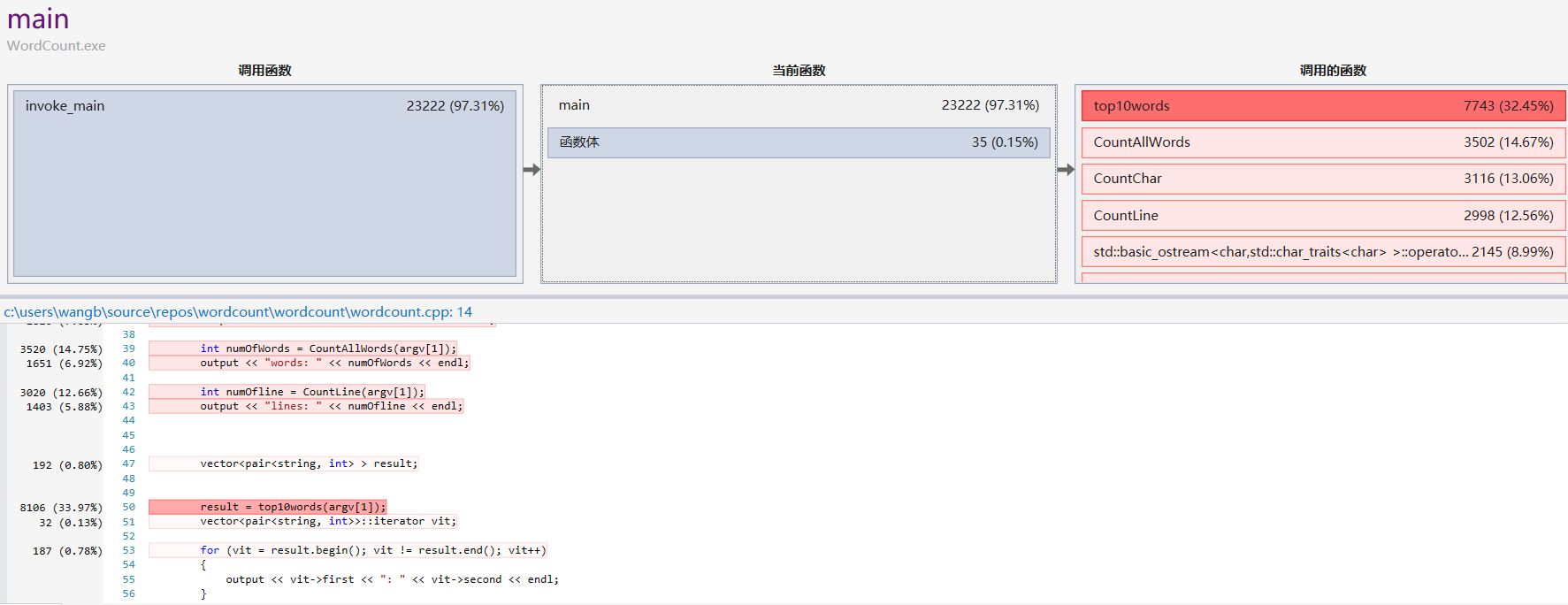
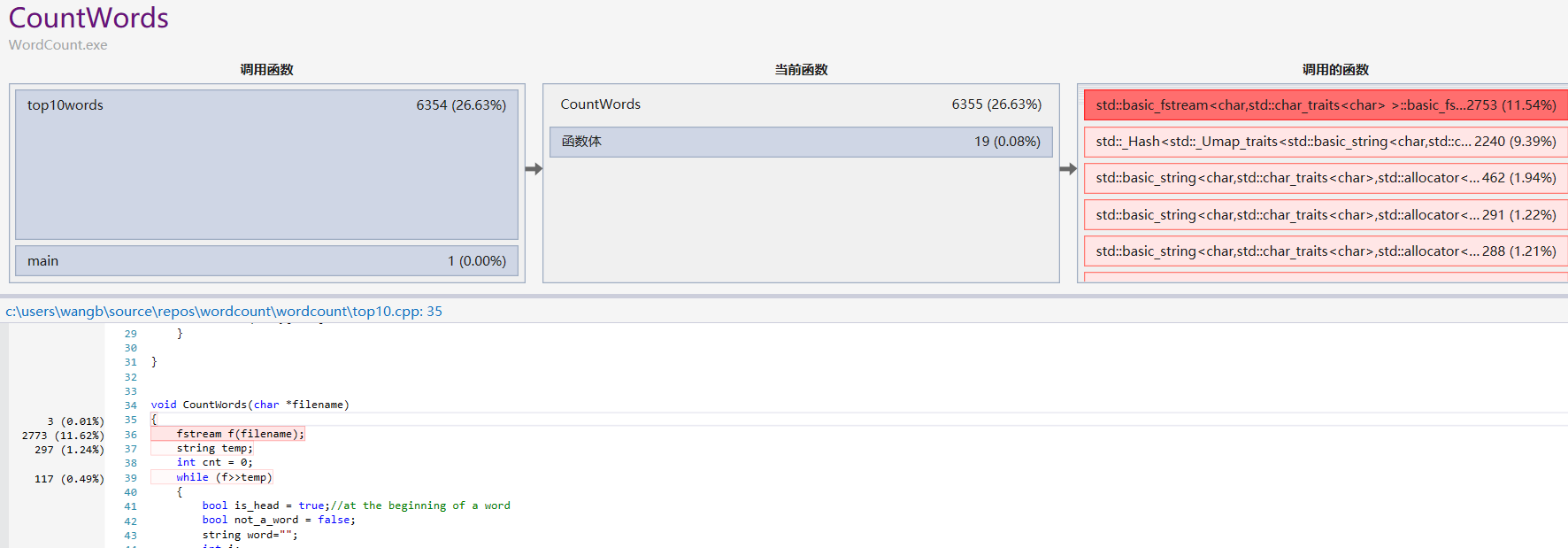
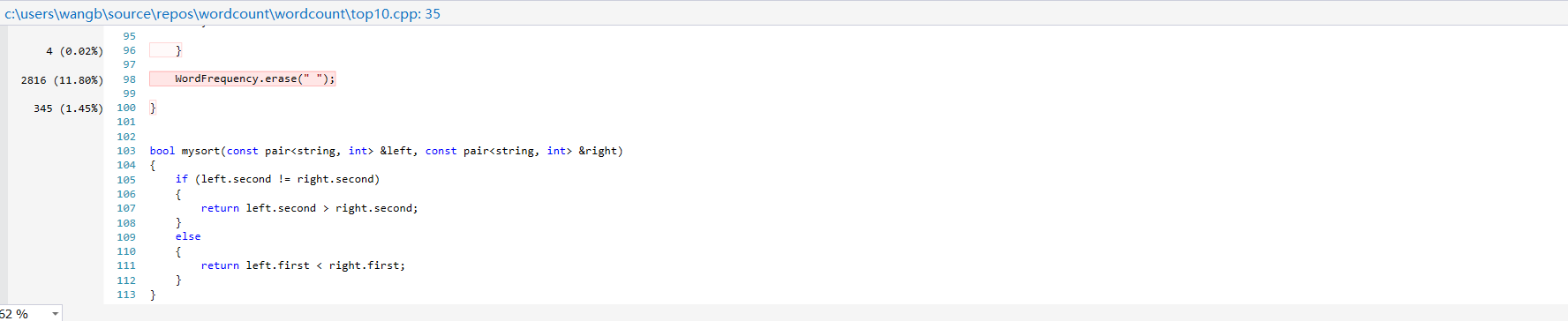
可以发现性能瓶颈主要出现在文件读取以及删除空格单词的词频上,通过代码逻辑优化后,执行同样的测试,运行时间缩短了3秒
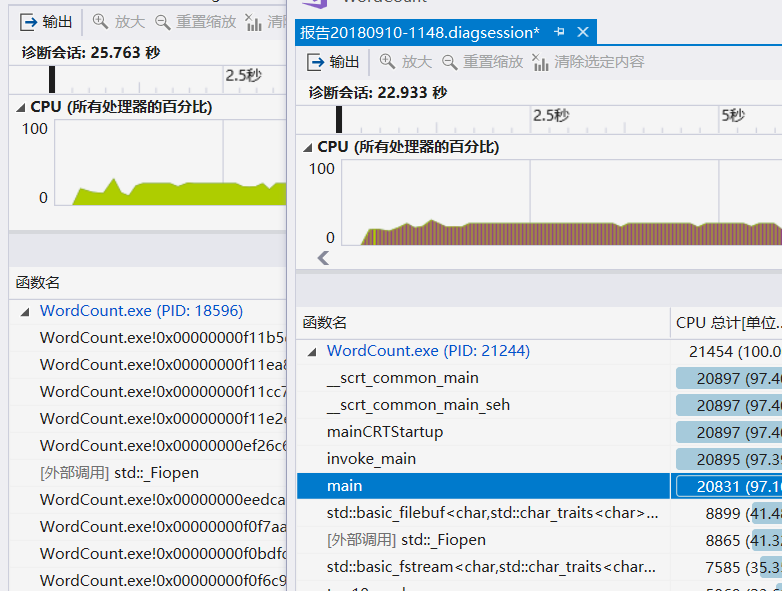
单元测试改进
十个单元测试
-
文本不存在
-
无参数输入
-
空文本
-
单词以数字开头
-
大小写单词
-
其他字符
-
单词长度
-
参数超过限制
-
文本包含10个以上的不同单词
-
文本只包含空格、换行符与制表符
-
10个测试通过
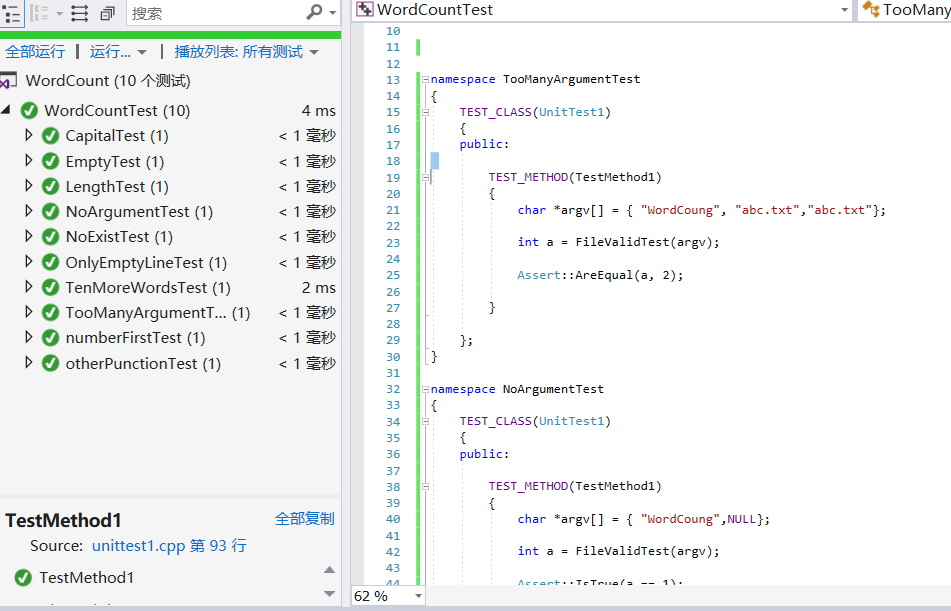
代码覆盖率
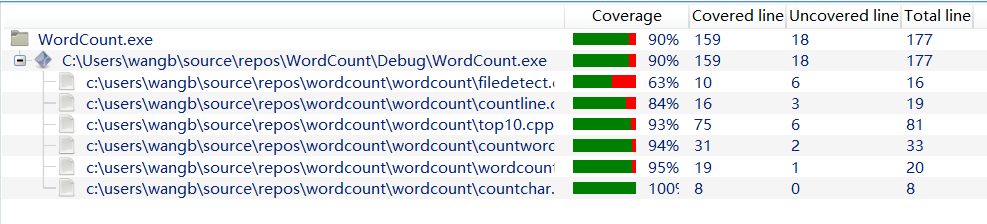
代码覆盖率低的filedetect.cpp,是因为没被覆盖的代码是应对错误参数输入设计的
异常处理说明
- 针对参数输入错误的异常处理:
- 当无文本参数输入时
- 当输入参数过多时
- 文本文件不存或无法打开时

- 针对空文本输入时,防止优先队列容量为0时的访问越界情况:
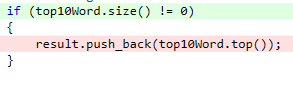
心得体会
-
通过这次个人项目,我逐步开始体会到软件工程这门课程的重要性,以前写一些大点的程序,在代码改动时整个项目就像倒过来的金字塔,改动任何一处都会导致一连串错误的发生。在这次实践中我按照PSP表格对项目的规划一步一步地完成了整个项目,而不像从前为了尽快完成作业,用一种写了再说的方式来对待项目。这种步步为营的计划也许就是软件工程中“工程”二字的含义所在吧。毫无疑问,按照这种方式写出的软件结构性更强,而且各个模块也能包产到户,使得项目进展更容易衡量。
-
针对PSP表格中的结果,我对自己的时间预计出现了很大偏差,特别是测试部分的时间预估远远不足,这和我对单元测试的认识有很大关系,相信随着之后的学习,对项目的时间规划会越来越趋于实际
-
以前对github以及git的认识一直停留在纸面上,虽然知道它们是coder强大的工具,但一直觉得自己写小项目用github有大材小用的感觉,直到这次在项目进行时全程按照规范,一旦项目进展立刻签入github,我才对github有了真正可感的认识。在实现业务逻辑时不用畏手畏脚的感觉实在太棒了。
-
此外这也是第一次为自己写的软件写单元测试,终与知道还有这样相对轻松且自动化的测试方式