1.1. 索引入门
1.1.1. 索引是什么
1.1.1.1. 生活中的索引
MySQL官方对索引的定义为:索引(Index)是帮助MySQL高效获取数据的数据结构。
可以得到索引的本质:索引是数据结构。
上面的理解比较抽象,举一个例子,平时看任何一本书,首先看到的都是目录,通过目录去查询书籍里面的内容会非常的迅速。

上图就是一本书,书籍的目录是按顺序放置的,有第一节,第二节它本身就是一种顺序存放的数据结构,是一种顺序结构。
另外通过目录(索引),可以快速查询到目录里面的内容,它能高效获取数据,通过这个简单的案例可以理解所以就是高效获取数据的数据结构
再来看一个发杂的情况,

我们要去图书馆找一本书,这图书馆的书肯定不是线性存放的,它对不同的书籍内容进行了分类存放,整索引由于一个个节点组成,根节点有中间节点,中间节点下面又由子节点,最后一层是叶子节点,
可见,整个索引结构是一棵倒挂着的树,其实它就是一种数据结构,这种数据结构比前面讲到的线性目录更好的增加了查询的速度。
1.1.1.2. MySql中的索引

MySql中的索引其实也是这么一回事,我们可以在数据库中建立一系列的索引,比如创建主键的时候默认会创建主键索引,上图是一种BTREE的索引。每一个节点都是主键的ID
当我们通过ID来查询内容的时候,首先去查索引库,在到索引库后能快速的定位索引的具体位置。
1.1.1.3. 谈下B+Tree
要谈B+TREE说白了还是Tree,但谈这些之前还要从基础开始讲起
1.1.1.3.1. 二分查找
二分查找法(binary search) 也称为折半查找法,用来查找一组有序的记录数组中的某一记录。
其基本思想是:将记录按有序化(递增或递减)排列,在查找过程中采用跳跃式方式查找,即先以有序数列的中点位置作为比较对象,如果要找的元素值小于该中点元素,则将待查序列缩小为左半部分,否则为右半部分。通过一次比较,将查找区间缩小一半。
# 给出一个例子,注意该例子已经是升序排序的,且查找 数字 48
数据:5, 10, 19, 21, 31, 37, 42, 48, 50, 52
下标:0, 1, 2, 3, 4, 5, 6, 7, 8, 9
• 步骤一:设 low 为下标最小值 0 , high 为下标最大值 9 ;
• 步骤二:通过 low 和 high 得到 mid ,mid=(low + high) / 2,初始时 mid 为下标 4 (也可以=5,看具体算法实现);
• 步骤三 : mid=4 对应的数据值是31,31 < 48(我们要找的数字);
• 步骤四:通过二分查找的思路,将 low 设置为31对应的下标 4 , high 保持不变为 9 ,此时 mid 为 6 ;
• 步骤五 : mid=6 对应的数据值是42,42 < 48(我们要找的数字);
• 步骤六:通过二分查找的思路,将 low 设置为42对应的下标 6 , high 保持不变为 9 ,此时 mid 为 7 ;
• 步骤七 : mid=7 对应的数据值是48,48 == 48(我们要找的数字),查找结束;
通过3次 二分查找 就找到了我们所要的数字,而顺序查找需8
1.1.1.3.2. 二叉树(Binary Tree)
每个节点至多只有二棵子树;
• 二叉树的子树有左右之分,次序不能颠倒;
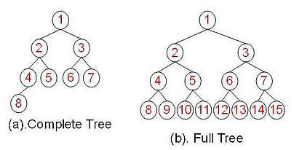
• 一棵深度为k,且有 个节点,称为满二叉树(Full Tree);
• 一棵深度为k,且root到k-1层的节点树都达到最大,第k层的所有节点都 连续集中 在最左边,此时为完全二叉树(Complete Tree)
1.1.1.3.3. 平衡二叉树(AVL-树)
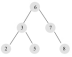
l 左子树和右子树都是平衡二叉树;
l 左子树和右子树的高度差绝对值不超过1;
◦ 平衡二叉树
◦ 非平衡二叉树

1.1.1.3.3.1. 平衡二叉树的遍历
l 前序 :6 ,3, 2, 5,7, 8(ROOT节点在开头, 中 -左-右 顺序)
l 中序 :2, 3, 5, 6,7, 8(中序遍历即为升序,左- 中 -右 顺序)
l 后序 :2, 5, 3, 8,7, 6 (ROOT节点在结尾,左-右- 中 顺序)
1.1.1.3.3.2. 平衡二叉树的旋转

需要通过旋转(左旋,右旋)来维护平衡二叉树的平衡,在添加和删除的时候需要有额外的开销。
1.1.1.3.4. B+树
1.1.1.3.4.1. B+树的定义
l 数据只存储在叶子节点上,非叶子节点只保存索引信息;
◦ 非叶子节点(索引节点)存储的只是一个Flag,不保存实际数据记录;
◦ 索引节点指示该节点的左子树比这个Flag小,而右子树大于等于这个Flag
l 叶子节点本身按照数据的升序排序进行链接(串联起来);
◦ 叶子节点中的数据在 物理存储上是无序 的,仅仅是在 逻辑上有序 (通过指针串在一起);
1.1.1.3.4.2. B+树的作用
l 在块设备上,通过B+树可以有效的存储数据;
l 所有记录都存储在叶子节点上,非叶子(non-leaf)存储索引(keys)信息;
l B+树含有非常高的扇出(fanout),通常超过100,在查找一个记录时,可以有效的减少IO操作;
1.1.1.3.4.3. B+树的扇出(fan out)

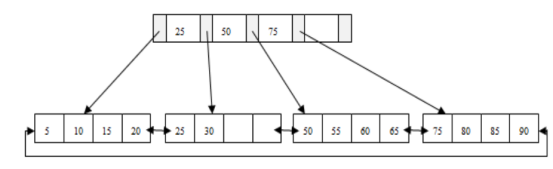
n 该 B+ 树高度为 2
n 每叶子页(LeafPage)4条记录
n 扇出数为5
n 叶子节点(LeafPage)由小到大(有序)串联在一起
扇出 是每个索引节点(Non-LeafPage)指向每个叶子节点(LeafPage)的指针
扇出数 = 索引节点(Non-LeafPage)可存储的最大关键字个数 + 1
图例中的索引节点(Non-LeafPage)最大可以存放4个关键字,但实际使用了3个;
1.1.1.3.4.4. B+树的插入操作
• B+树的插入
B+树的插入必须保证插入后叶子节点中的记录依然排序。

问题:1 插入28

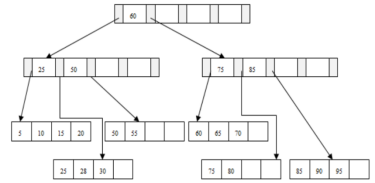
问题2:插入70

问题3:插入95
https://blog.csdn.net/shenchaohao12321/article/details/83243314
1.1.2. 索引的分类
普通索引:即一个索引只包含单个列,一个表可以有多个单列索引
唯一索引:索引列的值必须唯一,但允许有空值
复合索引:即一个索引包含多个列
聚簇索引(聚集索引):并不是一种单独的索引类型,而是一种数据存储方式。具体细节取决于不同的实现,InnoDB的聚簇索引其实就是在同一个结构中保存了B-Tree索引(技术上来说是B+Tree)和数据行。
非聚簇索引:不是聚簇索引,就是非聚簇索引
1.1.3. 基础语法
查看索引
SHOW INDEX FROM table_nameG
创建索引
CREATE [UNIQUE ] INDEX indexName ON mytable(columnname(length));
ALTER TABLE 表名 ADD [UNIQUE ] INDEX [indexName] ON (columnname(length))
删除索引
DROP INDEX [indexName] ON mytable;