Flink 累计窗口
接上篇: [如何用flink sql写,3h,7h,1d内pv,uv] (https://www.cnblogs.com/Springmoon-venn/p/15179311.html)
之前一直比较遗憾,Flink Sql 没有 Trigger 功能,长时间的窗口不能在中途触发计算,输出中间结果。而很多实时指标是小时、天级的累集窗口,比如大屏中的当日 pv、uv,整体是一天中所有访问的次数和用户数,但是需要实时更新,比如每 10S 更新一次截止到当前的pv、uv。
这种场景使用 Streaming Api 很容易实现,就是个天的翻滚窗口加上 10S 的 Trigger 就可以了
.windowAll(TumblingEventTimeWindows.of(Time.days(1), Time.hours(-8)))
.trigger(ContinuousProcessingTimeTrigger.of(Time.seconds(10)))
Flink 1.13 版本以前,Sql 中还不能实现这个功能,1.13 添加了 CUMULATE 窗口,可以支持这种场景。
(感谢 antigeneral 同学提醒有这个功能)
以下为官网介绍:
累积窗口在某些情况下非常有用,例如在固定窗口间隔内提前触发的滚动窗口。例如,每日仪表板绘制从 00:00 到10:00 处每分钟累积的 UV, UV 表示从 00:00 到 10:00 的 UV 总数。这可以通过 CUMULATE 窗口轻松地实现。
CUMULATE 函数将元素分配给覆盖初始步长间隔内的窗口,并每一步扩展到一个步长(保持窗口开始固定),直到最大窗口大小。您可以将 CUMULATE 函数视为首先应用 TUMBLE 最大窗口大小的窗口,然后将每个滚动窗口拆分为具有相同窗口开始和窗口结束步长差异的多个窗口。所以累积窗口确实重叠并且没有固定的大小。
例如,您可以有一个 1 小时步长和 1 天最大大小的累积窗口,并且您将获得每天的窗口:[00:00, 01:00), [00:00, 02:00), [00:00, 03:00), ..., [00:00, 24:00)。
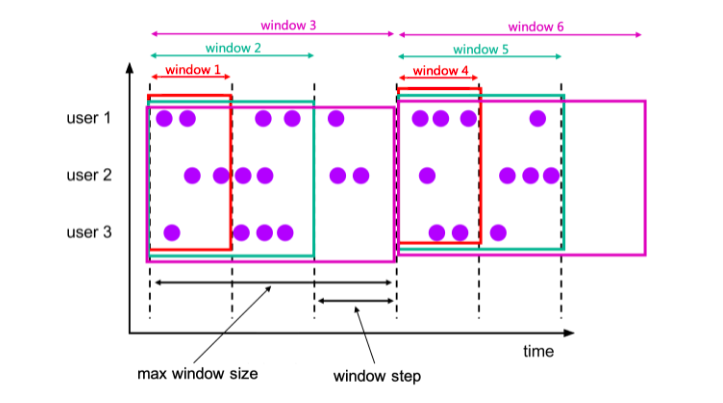
这些CUMULATE函数根据时间属性列分配窗口。的返回值CUMULATE是一个新的关系,包括原始关系的所有列以及额外的 3 列名为“window_start”、“window_end”、“window_time”以指示分配的窗口。原始时间属性“timecol”将是窗口 TVF 之后的常规时间戳列。
CUMULATE 需要三个必需的参数。
CUMULATE(TABLE data, DESCRIPTOR(timecol), step, size)
data: 是一个表参数,可以与时间属性列有任何关系。timecol: 是一个列描述符,指示数据的哪些时间属性列应该映射到滚动窗口。step: 是指定顺序累积窗口结束之间增加的窗口大小的持续时间。size: 是指定累积窗口最大宽度的持续时间。size 必须是 step 的整数倍。
这是 Bid 表上的示例调用:
-- NOTE: Currently Flink doesn't support evaluating individual window table-valued function, -- window table-valued function should be used with aggregate operation, -- this example is just used for explaining the syntax and the data produced by table-valued function. > SELECT * FROM TABLE( CUMULATE(TABLE Bid, DESCRIPTOR(bidtime), INTERVAL '2' MINUTES, INTERVAL '10' MINUTES)); -- or with the named params -- note: the DATA param must be the first > SELECT * FROM TABLE( CUMULATE( DATA => TABLE Bid, TIMECOL => DESCRIPTOR(bidtime), STEP => INTERVAL '2' MINUTES, SIZE => INTERVAL '10' MINUTES));
+------------------+-------+------+------------------+------------------+-------------------------+
| bidtime | price | item | window_start | window_end | window_time |
+------------------+-------+------+------------------+------------------+-------------------------+
| 2020-04-15 08:05 | 4.00 | C | 2020-04-15 08:00 | 2020-04-15 08:06 | 2020-04-15 08:05:59.999 |
| 2020-04-15 08:05 | 4.00 | C | 2020-04-15 08:00 | 2020-04-15 08:08 | 2020-04-15 08:07:59.999 |
| 2020-04-15 08:05 | 4.00 | C | 2020-04-15 08:00 | 2020-04-15 08:10 | 2020-04-15 08:09:59.999 |
| 2020-04-15 08:07 | 2.00 | A | 2020-04-15