上篇已经安装好了虚拟机了,现在开始配置环境,安装hadoop
注:hadoop集群最少需要三台机,因为hdfs副本数最少为3,单机不算
我搭了三台机
1、创建hadoop用户,hadoopgroup组
groupadd -g 102 hadoopgroup # 创建用户组 useradd -d /opt/hadoop -u 10201 -g 102 hadoop #创建用户 passwd hadoop #给用户设置密码
2、安装ftp工具
yum -y install vsftpd
启动ftp:systemctl start vsftpd.service
停止ftp:systemctl stop vsftpd.service
重启ftp:systemctl restart vsftpd.service
[root@venn08 ~]# systemctl start vsftpd.service # 启动,无提示信息 [root@venn08 ~]# ps -ef|grep vsft #查看进程已存在,直接使用ftp工具连接 root 1257 1 0 09:41 ? 00:00:00 /usr/sbin/vsftpd /etc/vsftpd/vsftpd.conf root 1266 1125 0 09:42 pts/0 00:00:00 grep --color=auto vsft [root@venn08 ~]# systemctl restart vsftpd.service
注:使用vsftpd 安装后就可以使用系统用户作为ftp用户登录,选项同系统权限,不需要额外配置。
2、安装jdk、hadoop
将下载的jdk、hadoop拷贝到服务器上,解压,修改目录名
[hadoop@venn05 ~]$ pwd /opt/hadoop [hadoop@venn05 ~]$ ll drwxr-xr-x. 11 hadoop hadoopgroup 172 Apr 3 20:49 hadoop3 -rw-r--r--. 1 hadoop hadoopgroup 307606299 Apr 2 22:30 hadoop-3.0.1.tar.gz drwxr-xr-x. 8 hadoop hadoopgroup 255 Apr 1 2016 jdk1.8 -rw-r--r--. 1 hadoop hadoopgroup 181367942 May 26 2016 jdk-8u91-linux-x64.tar.gz
修改目录名,是为了方便书写
3、配置Java、hadoop环境变量
在最后添加Java、hadoop环境变量,注意路径不要写错即可
[hadoop@venn05 ~]$ vim .bashrc [hadoop@venn05 ~]$ more .bashrc # .bashrc # Source global definitions if [ -f /etc/bashrc ]; then . /etc/bashrc fi # Uncomment the following line if you don't like systemctl's auto-paging feature: # export SYSTEMD_PAGER= # User specific aliases and functions #jdk export JAVA_HOME=/opt/hadoop/jdk1.8 export JRE_HOME=${JAVA_HOME}/jre export CLASS_PATH=${JAVA_HOME}/lib:${JRE_HOME}/lib export PATH=${JAVA_HOME}/bin:$PATH #hadoop export HADOOP_HOME=/opt/hadoop/hadoop3 export PATH=$HADOOP_HOME/bin:$HADOOP_HOME/sbin:$PATH
4、切换root用户,修改各机/etc/hosts
[root@venn05 hadoop]# vim /etc/hosts [root@venn05 hadoop]# more /etc/hosts 127.0.0.1 localhost localhost.localdomain localhost4 localhost4.localdomain4 ::1 localhost localhost.localdomain localhost6 localhost6.localdomain6 192.168.1.5 venn05 192.168.1.6 venn06 192.168.1.7 venn07
其他几台机操作相同
5、创建ssh密钥
[hadoop@venn08 ~]$ mkdir .ssh # 创建.ssh 目录 [hadoop@venn08 ~]$ cd .ssh/ [hadoop@venn08 .ssh]$ ls [hadoop@venn08 .ssh]$ pwd /opt/hadoop/.ssh [hadoop@venn08 .ssh]$ ssh-keygen -t rsa # 创建ssh秘钥,一路回车下去 Generating public/private rsa key pair. Enter file in which to save the key (/opt/hadoop/.ssh/id_rsa): Enter passphrase (empty for no passphrase): Enter same passphrase again: Your identification has been saved in /opt/hadoop/.ssh/id_rsa. Your public key has been saved in /opt/hadoop/.ssh/id_rsa.pub. The key fingerprint is: SHA256:rrlJxkA6o4eKwDKWjbx5CgyH+9EzbUiyfFHnJzgTL5w hadoop@venn08 The key's randomart image is: +---[RSA 2048]----+ | | | | | . o . | | . o o B | |o * + E S . | |=*+B * = o | |OB=.* * . | |B+o+ * + | |o++ =. | +----[SHA256]-----+ [hadoop@venn08 .ssh]$ ll # 查看 total 8 -rw-------. 1 hadoop hadoopgroup 1679 Apr 24 10:17 id_rsa # 私钥,本机保存 -rw-r--r--. 1 hadoop hadoopgroup 395 Apr 24 10:17 id_rsa.pub #公钥,复制到其他机器
每台机都执行以上步骤,创建 ssh 密钥
6、合并每台机器的公钥,放到每台机器上
Venn05 : 复制公钥到文件 : cat id_rsa.pub >> authorized_keys 拷贝到 venn 06 : scp authorized_keys hadoop@venn06:~/.ssh/authorized_keys Venn 06 : 拷贝venn06的公钥到 authorized_keys : cat id_rsa.pub >> authorized_keys 拷贝到 venn07 : scp authorized_keys hadoop@venn07:~/.ssh/authorized_keys Venn07 : 复制公钥到文件 : cat id_rsa.pub >> authorized_keys 拷贝到 venn 05 : scp authorized_keys hadoop@venn05:~/.ssh/authorized_keys 拷贝到 venn 06 : scp authorized_keys hadoop@venn05:~/.ssh/authorized_keys
多机类推
至此,配置完成,现在各机hadoop用户可以免密登录。
7、修改 hadoop环境配置:hadoop-env.sh
进入路径: /opt/hadoop/hadoop3/etc/hadoop,打开 hadoop-env.sh 修改:
export JAVA_HOME=/opt/hadoop/jdk1.8 # 执行jdk
8、修改hadoop核心配置文件 : core-site.sh ,添加如下内容
<configuration>
<!--hdfs临时路径-->
<property>
<name>hadoop.tmp.dir</name>
<value>/opt/hadoop/hadoop3/tmp</value>
</property>
<!--hdfs 的默认地址、端口 访问地址-->
<property>
<name>fs.defaultFS</name>
<value>hdfs://venn05:8020</value>
</property>
</configuration>
9、修改yarn-site.sh ,添加如下内容
<configuration>
<!-- Site specific YARN configuration properties -->
<!--集群master,-->
<property>
<name>yarn.resourcemanager.hostname</name>
<value>venn05</value>
</property>
<!-- NodeManager上运行的附属服务-->
<property>
<name>yarn.nodemanager.aux-services</name>
<value>mapreduce_shuffle</value>
</property>
<!--容器可能会覆盖的环境变量,而不是使用NodeManager的默认值-->
<property>
<name>yarn.nodemanager.env-whitelist</name>
<value> JAVA_HOME,HADOOP_COMMON_HOME,HADOOP_HDFS_HOME,HADOOP_CONF_DIR,CLASSPATH_PREPEND_DISTCACHE,HADOOP_YARN_HOME,HADOOP_HOME,PATH,LANG,TZ</value>
</property>
<!-- 关闭内存检测,虚拟机需要,不配会报错-->
<property>
<name>yarn.nodemanager.vmem-check-enabled</name>
<value>false</value>
</property>
</configuration>
10、修改mapred-site.xml ,添加如下内容
<configuration>
<!--local表示本地运行,classic表示经典mapreduce框架,yarn表示新的框架-->
<property>
<name>mapreduce.framework.name</name>
<value>yarn</value>
</property>
<!--如果map和reduce任务访问本地库(压缩等),则必须保留原始值
当此值为空时,设置执行环境的命令将取决于操作系统:
Linux:LD_LIBRARY_PATH=$HADOOP_COMMON_HOME/lib/native.
windows:PATH =%PATH%;%HADOOP_COMMON_HOME%\bin.
-->
<property>
<name>mapreduce.admin.user.env</name>
<value>HADOOP_MAPRED_HOME=/opt/hadoop/hadoop3</value>
</property>
<!--
可以设置AM【AppMaster】端的环境变量
如果上面缺少配置,可能会造成mapreduce失败
-->
<property>
<name>yarn.app.mapreduce.am.env</name>
<value>HADOOP_MAPRED_HOME=/opt/hadoop/hadoop3</value>
</property>
</configuration>
11、修改hdfs-site.xml ,添加如下内容
<configuration>
<!--hdfs web的地址 -->
<property>
<name>dfs.namenode.http-address</name>
<value>venn05:50070</value>
</property>
<!-- 副本数-->
<property>
<name>dfs.replication</name>
<value>3</value>
</property>
<!-- 是否启用hdfs权限检查 false 关闭 -->
<property>
<name>dfs.permissions.enabled</name>
<value>false</value>
</property>
<!-- 块大小,默认字节, 可使用 k m g t p e-->
<property>
<name>dfs.blocksize</name>
<!--128m-->
<value>134217728</value>
</property>
</configuration>
12、修workers 文件
[hadoop@venn05 hadoop]$ more workers venn05 # 第一个为master venn06 venn07
至此,hadoop master配置完成
13、scp .bashrc 、jdk 、hadoop到各个节点
进入hadoop home目录 cd ~
scp -r .bashrc jdk1.8 hadoop3 hadoop@192.168.1.8:/opt/hadoop/
至此hadoop集群搭建完成。
14、启动hadoop:
格式化命名空间:
hdfs namenode –formate
启动集群:
start-all.sh
输出:
[hadoop@venn05 ~]$ start-all.sh WARNING: Attempting to start all Apache Hadoop daemons as hadoop in 10 seconds. WARNING: This is not a recommended production deployment configuration. WARNING: Use CTRL-C to abort. Starting namenodes on [venn05] Starting datanodes Starting secondary namenodes [venn05] Starting resourcemanager Starting nodemanagers
jps 查看进程:
[hadoop@venn05 ~]$ jps 5904 Jps 5733 NodeManager 4871 NameNode 5431 ResourceManager 5211 SecondaryNameNode [hadoop@venn05 ~]$
查看其它节点状态:
[hadoop@venn06 hadoop]$ jps 3093 NodeManager 3226 Jps 2973 DataNode
hadoop启动成功
查看yarn web 控制台:
http://venn05:8088/cluster
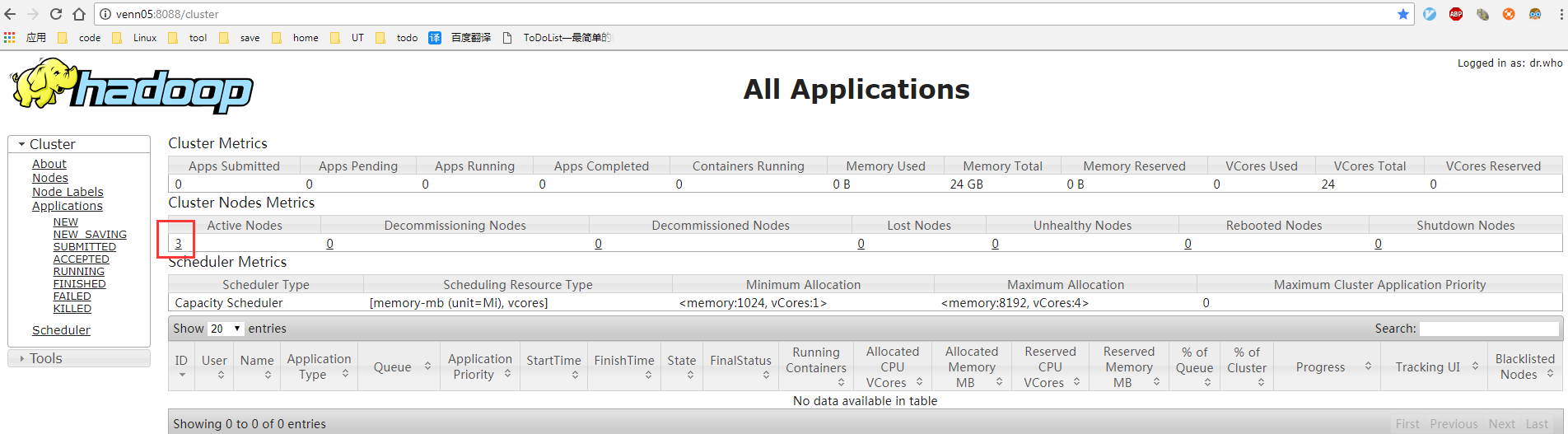
查看 hdfs web 控制台:
http://venn05:50070/dfshealth.html#tab-overview

搞完收工,明天继续写ntp 和搭建过程中遇到的坑