参考文献:https://msdn.microsoft.com/en-us/magazine/ms809762.aspx
https://msdn.microsoft.com/en-us/magazine/bb985992.aspx
PE文件到内存的映射:http://www.cnblogs.com/qintangtao/archive/2013/01/28/2880606.html
关于windows虚拟地址空间分配问题:https://blog.csdn.net/wang010366/article/details/52730052
第二篇的翻译:http://www.cppblog.com/shaoxie1986/articles/126142.html
第一篇文章前面讲了很多乱七八糟的历史遗留问题,包括16位Windows,COFF等等东西,大致意思是:
Windows有两种不同的操作系统:Windows和WindowsNT.Windows系统有95、98、Mc等品牌,他们都是从老一点16位版本的Windows系统发展而来。WindowsNT系统有Windows 2000以及Windows XP Windows7 8 8.1 10等品牌。WindowsNT架构的基本特征如下:纯32位架构;支持虚拟机;可移植性;支持多线程;支持多处理器;安全性和兼容性。
(WindowsNT需要一种对COFF进行扩展,保证他的可移植性,从而发明了PE文件格式)众所周知,Windows NT具有VAX®VMS®和UNIX®传统,许多Windows NT创建者在来到Microsoft之前为这些平台设计和编码。当设计Windows NT时,很显然,他们试图通过使用以前编写和测试的工具来最小化他们的引导时间。通过这些工具生成和使用的可执行文件和对象模块格式被称为COFF(公共对象文件格式)。 COFF的相对年龄可以通过诸如以八进制格式指定的字段之类的东西来看出。 COFF格式本身是一个很好的起点,但为了现代操作系统(如Windows NT或Windows 95)的所有需求,他需要扩展。此更新的结果是可移植可执行格式。它被称为“可移植”,因为Windows NT在各种平台(x86,MIPS®,Alpha等)上的所有实现都使用相同的可执行格式。当然,在CPU指令的二进制编码等方面存在差异。重要的是,不必为每个到达现场的新CPU完全重写操作系统加载程序和编程工具。
你可以选择直接跳过前面一部分,直接进入"Win32 and PE Basic Concepts"部分。
基本概念(术语):
Module(模块):已加载到内存中的可执行文件或DLL的代码,数据和资源。以及用于确定代码数据位置的由Windows使用的支持数据结构,其中这个数据结构在PE头中。磁盘上的文件不是模块,装入内存后运行时就叫做模块。
模块句柄(handle):(模块的基地址作为模块句柄)句柄只是一个数值而已,它的值对程序来说是没有意义的,它只是Windows用来表示各种资源的编号而已。在WINDOWS下,模块指的是EXE和DLL等数据加载到内存中的映像,模块句柄又是比较特殊的,它跟一般的句柄不一样,模块句柄指向的就是EXE和DLL等的在内存的位置(就是指向它们的数据起始位置);进程句柄只是WINDOWS用来标识某个进程的ID值罢了,在内部,WINDOWS使用一种类似MAP的技术来进行映射的,就是通过这个进程句柄来找到指定进程在内存的位置
PE文件:意为可移植的可执行的文件,常见的EXE、DLL、OCX、SYS、COM都是PE文件,PE文件是微软Windows操作系统上的程序文件(可能是间接被执行,如DLL)(摘自百度)。这个概念很重要,PE文件基本可以理解是放在磁盘中的可执行文件(DLL除外)
VA(Virtual Address 虚拟地址):虚拟内存并不是真正的内存,它是通过映射(Map)的方法,使可用的虚拟地址(VA)达到4GB(因为EIP32位索引的最大范围是4GB)。每个程序都有独立的4GB寻址空间,不同程序的地址空间是被互相隔离的;
DLL程序没有自己的“私有”空间,它们称之为动态链接库文件,它们总是被映射到其他应用程序的地址空间中的,作为其他应用程序的一部分运行。在这里可以简单理解就是内存地址(实际上基于Windows的分页机制,这些地址空间的一些部分被映射了物理内存,一些部分映射硬盘上的交换文件,一些部分什么也没有映射。)虚拟内存管理器通过虚拟地址的访问请求,控制所有的物理地址访问;
物理地址:CPU访问内存单元时,要给出内存单元的地址。所有的内存单元构成的存储孔家你是一个一维的线性空间,每个内存单元都在这个空间中有唯一的地址,称为物理地址。物理地址 = 段地址*16+偏移地址。BTW,内存本身没有分段,段(segment)的划分来源于CPU。
基地址(BaseAddress):是内存映射的EXE或DLL的起始地址,是Win32中的一个重要概念。也称为模块的基址。Windows NT和Windows 95使用模块的基址作为模块句柄
RVA(Relative Virtual Address相对虚拟地址 ):PE文件中的许多字段都是根据RVAs指定的。 RVA只是某个项的偏移量,相对于文件内存映射的位置。。一个RVA是在内存中相对于PE文件被加载的地址的一个偏移。例如,假设加载程序将PE文件映射到虚拟地址空间中从地址0x10000开始的内存中。如果图像中的某个表从地址0x10464开始,则表的RVA为0x464。
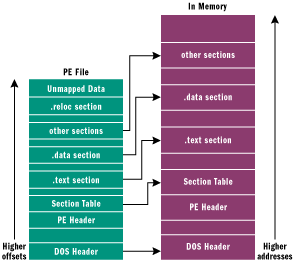
因为在磁盘上的可执行文件(PE文件)与Windows加载后的模块非常相似。 Windows加载器不需要非常努力地从磁盘文件创建进程。加载程序使用内存映射文件机制( the memory-mapped file mechanism )将文件的相应部分映射到virtual address space(VAS,虚拟地址空间)。使用结构类比,PE文件就像一个预制的家。它基本上是一个整体,然后是少量工作将它连接到世界其他地方(也就是说,将它连接到它的DLL等等)。同样的加载容易性也适用于PE格式的DLL。加载模块后,Windows可以像任何其他内存映射文件一样有效地对待它。
对于Win32,一块连续的内存被模块用于存储代码,数据,资源,导入表,导出表和其他所需模块数据结构。在这种情况下,你需要知道的是仅仅是加载器将文件映射到内存的位置,而你可以通过根据存储镜像部分的指针轻松找到模块的所有各个部分。
但是在和可执行文件打交道时,你要牢记的是他是可重定位的。这意味着每次加载可执行文件,他的虚拟地址都不一样(一旦加载后,就不能再重定位)。发生重定位的原因是因为可执行文件不能存在于真空中,它必须与其他可执行文件一起加载到同一个地址空间(VAS)中。当然,现代操作系统为每个进程都分配了单独的地址空间(VAS),但在每个地址空间中都加载了多个可执行文件。除了主可执行文件(你在运行程序时启动的后缀为.exe文件),每个程序都有一定数量的附加可执行文件同时加载到了这一个地址空间(VAS)中,不管这个层序是否有自己的DLLs。由于每个地址空间中都加载了多个可执行文件,导致每个地址空间事实上都是一个多个可执行文件的混合体。因此,可能会出现两个或多个模块试图使用同一个内存地址,这显然是行不通的。解决方法是当加载时重定位其中一个模块,将它加载到任意一个与原来加载位置不同的地址即可。可执行文件需要事先知道他要加载的位置,因为一个可执行文件包含有许多交叉引用。事实上每个模块创建时都会为它分配一个基地址,这样就不必在每次加载模块时都重复这一修改绝对地址的过程了。相反,如果这个模块基地址已被占用,这个模块就需要重定位。而为了区分地址空间中的不同模块,每个模块都有一个唯一的模块句柄来标识。
因为有了重定位,可执行文件的头部中就不会有绝对地址了,绝对地址只存于代码中,只要可执行文件的头部中有一个指针,他就是已相对虚拟地址(relative vitural address,RVA)的形式出现。RVA是文件内的一个偏移量,当文件被加载并分配了一个虚拟地址后,加载器利用RVA计算出实际的虚拟地址,其计算方法是:将模块基地址+RVA)的形式出现。RVA是文件内的一个偏移量,当文件被加载并分配了一个虚拟地址后,加载器利用RVA计算出实际的虚拟地址,其计算方法是:将模块基地址+RVA。
在大概讲述清楚了,PE文件的寻址方式,与进程的关系之后,我们在来关注PE文件内部:、
头部:
MZ-DOS头:PE文件是以DOS头部开始的,这符合我们通常所说的向下兼容设计,他确保了PE可以在DOS系统下优雅的失败。PE当然不能再DOS系统下执行。(这是MS-DOS最初设计者之一Mark Zbikowski名子的首字母大写。)
IMAGE_NT_HEADERS头:IMAGE_NT_HEADERS 结构是存储 PE 文件细节信息的主要位置。它的偏移由这个文件开头的 IMAGE_DOS_HEADER 的 e_lfanew 域给出。实际上有两个版本的IMAGE_NT_HEADER 结构,一个用于 32 位可执行文件,另一个用于 64 位版本。它们之间的区别很小,在讨论中我将认为它们是相同的。区别这两种格式的唯一正确的、由Microsoft 认可的方法是通过 IMAGE_OPTIONAL_HEADER 结构(马上就会讲到)的 Magic 域的值。
typedef struct _IMAGE_NT_HEADERS {
DWORD Signature;
IMAGE_FILE_HEADER FileHeader;
IMAGE_OPTIONAL_HEADER32 OptionalHeader;
} IMAGE_NT_HEADERS32, *PIMAGE_NT_HEADERS32;
这个IMAGE_NT_HEADERS32中,第一个是signature是PE签名,在一个有效的PE文件中,Signature字段的值是0x00004550,用ASCII表示就是“PE00”。 #define IMAGE_NT_SIGNATURE定义了这个值。第二个域是一个IMAGE_FILE_HEADER类型的结构,它包含了关于这个文件的一些基本的信息,最重要的是其中一个域指出了其后的可选数据的大小。在PE文件中,这个可选数据是必须的,但仍然被称为IMAGE_OPTIONAL_HEADER。
Table 2. IMAGE_FILE_HEADER Fields
Table 3. IMAGE_OPTIONAL_HEADER Fields
这些都不做详细描述,详情请看开头第一篇文献。 所有这些头部都定义在Microsoft Platform SDK的WinNT.H头文件中。
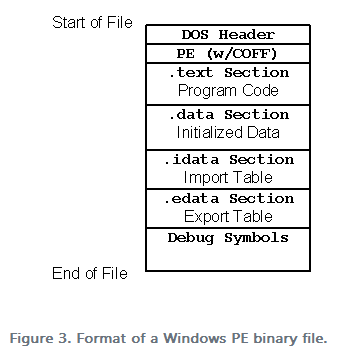
映像区段(Image Section),可执行映像被分为多个独立区段,之所以要分为多个区段,是因为在模块加载时内存管理要对文件中的不同区域采用不同的方式处理。常见有代码区段(code section)和数据区段(data section).区段对齐(Section Alignment),因为在可执行文件头部中对各个区段都设置了不同的访问权限,而且内存管理器在可执行文件映像加载时就需要应用这些访问权限,所以在将可执行文件加载至内存时通常需要对各个区段进行页对齐。另一方面,在磁盘上对可执行文件进行实际的页边界对齐又会浪费资源。
综合上面的原因,PE头部有两种对齐方式,区段对齐和文件对齐。PE文件头指定了这两个对齐值,它们可以是不同的。每个节起始于那个对齐值的倍数的位置。例如,在PE文件中,典型的对齐值是0x200。因此,每个节开始于一个0x200的倍数的文件偏移处。
一旦加载到内存中,节总是起始于至少一个页边界。就是说,当一个PE节被映射到内存中后,每个节的第一个字节都符合一个内存页。对于x86 CPUs,页是4KB,而IA-64,页是8KB。下面显示了PEDUMP输出的Windows XP KERNEL32.DLL 的.text节和.data节的一小部分。
在PE头和映像部分的原始数据之间是section table。Section table基本上是一本电话簿,其中包含有关映像中每个部分的信息。图像中的区段(section)按其起始地址(RVAs)排序,而不是按字母顺序排序。
What a Section is?
PE文件区段(section)包含了代码或某种数据。代码就是程序中的可执行代码,而数据却有很多种。除了可读写的程序数据(例如全局变量)之外,区段(section)中的其它类型的数据包括导入和导出表,资源,和重定位表。每个区段(section)在内存中都有它自己的属性,包括这个区段(section)是否含有代码,它是只读的还是可写的,这个区段(section)中的数据是否可在多个进程之间共享。
一般而言,一个区段(section)中所有的代码和数据都通过一些方法逻辑地联系起来。一个PE文件中通常至少有两个区段(section):一个代码区段(section),一个数据区段(section)。一般地,在一个PE文件中至少有一个其它类型的数据区段。在这篇文章的第二部分我将讨论这几种区段。(博主就省略了,请看上面参考文献)
每个区段都有一个不同的名字。这个名字被用来意指区段的作用。例如,一个叫做.rdata的区段表示一个只读数据区段。使用区段名只是为了人们方便,对操作系统来说没有任何意义。一个命名为FOOBAR的区段和一个命名为.text.的区段一样有效。Microsoft通常以一个句点作为区段名的前缀,但这不是必需的。多年来,Borland链接器就一直使用像CODE和DATA.这样的节名。
编译器有一组它们生成的标准的区段,对于它们没有什么不可思议的东西。你可以创建并命名你自己的区段,链接器很乐意在可执行文件中包括它们。在Visual C++中,你可以让编译器把代码或数据放到通过#pragma 语句命名的区段中。例如,下面这条语句
#pragma data_seg( "MY_DATA" )
它会使Visual C++把它生成的所有数据放到一个命名为MY_DATA的区段中,而不是缺省的.data区段。大多数程序都使用编译器产生的默认区段,但偶尔你也许会有把代码或数据放到一个单独的区段中的需求。
区段并不是全部由链接器生成的,它们其实存在于OBJ文件中,通常由编译器把它们放到那儿。链接器的工作是合并OBJ文件中所有必须的区段并且最终放到PE文件相应区段中。例如,你的工程中的每个OBJ文件都至少有一个包含代码的.text区段。链接器合并这些OBJ文件中的.text区段到一个PE文件中的单个的.text区段中。同样地,这些OBJ文件中的叫做.data的区段被合并到PE文件中一个单个的.data区段中。.LIB文件中的代码和数据通常也被包含在可执行文件中,但那个主题已经超出本文的范围了。
链接器遵循一整套规则来决定哪些区段该被合并以及如何合并。OBJ文件中的某个区段也许是提供给链接器使用的,并不会放到最终的可执行文件中去。像这样的区段是由编译器用来以传递信息给链接器。
动态链接库(Dynamically Linked Libraries,DLLs)是Windows系统中的一个重要特性。其基本思想是:程序可以分成若干个可执行文件,每个可执行文件实现程序的某一特性或部分功能。因为只有要用某个特性的时候才会加载相应的可执行文件,所以这样做可以降低整个程序的内存损耗。
对于静态库,.lib文件中的代码一旦生成,就静态地链接到可执行文件内部,就像lib文件中的代码本来就是源程序代码的一部分一样。当一个可执行文件被加载到操作系统时,我们就无法得知这部分代码来源于一个库。如果另一个加载的可执行文件也是静态链接到该库,这个库代码实际上被加载了两次到内存,因为操作系统不知道两个可执行文件中都包含了这个相同的部分。
Windows调用DDL的两种方法:
静态链接(不要和编译时的静态链接相混淆)指一个进程,在该进程可执行文件的导入表中包含对另一个可执行文件的引用(经典链接方式)。为了实现静态链接,在每个模块内部都有一个本模块所使用其他模块的列表和调用每个模块中的函数(这就是导入表)。
运行时链接指的是另一种方法,通过他可执行文件可以决定在运行期加载其他可执行文件,并调用那个可执行文件中的函数。
这两个模式的本质区别是对于动态链接来说程序必须在运行时手工加载正确模块,并通过查找可执行文件的头部找到正确的调用程序。运行期链接更加灵活,但对程序员来说实现起来比较困难。从逆向工程角度来看静态链接比较容易处理。因为他公开暴露了那个函数那个模块调用的。
导入导出:导入导出是前述可执行文件动态链接过程的实现机制。我们考虑一下在编译和链接时的一种的情形:考虑可执行文件引用了其他可执行文件中函数的情况。编译器和链接器并不知道导入函数的实际地址,只有运行到才知道地址。为了解决这个问题,链接器创建了一个特殊的导入表,列出了在目前模块中要引用所有函数名。
导入表包含了该模块要用到的所有模块列表以及每一个模块所要调用的函数列表。当加载模块时,加载器加载导入表中列出的每一个模块,并找到每个模块中列出的函数地址。这些地址是通过查找导出模块的导出表来找到的,导出表包含了每个导出函数的函数名和RVA。