多表优化及细节详讲
作者 : Stanley 罗昊
【转载请注明出处和署名,谢谢!】
注:本文章需要MySQL数据库优化基础或观看前几篇文章,传送门:
B树索引详讲(初识SQL优化,认识索引):https://www.cnblogs.com/StanleyBlogs/p/10413349.html
B树索引进阶(索引分类、创建方式、删除索引、查看索引、SQL性能问题):https://www.cnblogs.com/StanleyBlogs/p/10416865.html
SQL执行计划于笛卡尔积(了解什么是SQL执行计划,优化原理):https://www.cnblogs.com/StanleyBlogs/p/10422202.html
Type详讲(理解优化级别):https://www.cnblogs.com/StanleyBlogs/p/10426385.html
Extra(理解最终优化概念):https://www.cnblogs.com/StanleyBlogs/p/10429969.html
单表优化(开启优化篇章):https://www.cnblogs.com/StanleyBlogs/p/10442557.html
优化准备
首先我们需要有一个数据库,coursedb,分别创建course(课程表)、teacher(老师表),有以下字段,我们接下来将用以下这张表来做优化实例;

teacher表里面的id 是代表一号老师教2号课程2号老师教1号课程3号老师教三号课程;id是主键
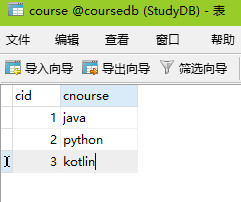
course表就是课程表1号代表java课程2号代表python...cid是主键
多表优化
此次教程不再使用可视化工具,因为效率太慢,我还是比较喜欢命令行操作;
现在有表了,有数据了,我现在写一个左连接,二表关联写一个左连接:
select * from teacher t left outer join course c on t.cid = c.cid where c.cnourse
左连接详解:
left join 是left outer join的简写【本语句使用left outer join】,它的全称是左外连接,是外连接中的一种。
左(外)连接,左表(teacher)的记录将会全部表示出来,而右表(cnourse)只会显示符合搜索条件的记录。右表记录不足的地方均为NULL;
语句解释:现在我们需要两表合一,所以就用左连接的方式,on则表明连接条件,where后面则是查询条件,查询cnourse = java课程的数据;
执行结果:

现在,我们就根据以上sql语句进行优化,所谓的优化,那就是加索引,在加索引之前,我们需要考虑一些问题;
对于这个问题,我有一个结论,就是小表驱动大表,什么意思呢?我举个例子:
比方说我现在有一个where 小表.x = 大表.y;这个就被称之为小表驱动大表,就是把小表放左边大表放一边,这是一个结论,咱们可以稍微分析一下为啥这样干;
假设小表里面有10条数据,我大表里面有300条数据,小表放左边大表放右边对于表里的每10条数据里的每一条,300条数据都会轮循遍历一次,10条里面第一条拿出来,右边执行300次,左边10条第二条拿出来,右边再300次,同理,第三条出来,再300次....;
有一个编程原则我在这里说一下,在写for循环的时候,双层for循环,你外层数据越小内存数据越大,那它的性能就越高,这个是编程原则,把这个原则放到这里也是一样的,数据量最小的表放在前面,数据量最大的表放在后面(where 小表 cid= 大表 cid);
但是对于刚才我写的sql语句来说,t.cid = c.cid即便反过来查询结果也是一样的完全是等价写法仅从结果上来看,但是我们从这个性能上来看,你在写之前分析一下到底是t表数据小呢,还是c表数据小,将数据小的表放到左边;
本题因为都是三条数据,所以不影响,再此就是提一提;
连表查询添加索引原则
现在我们再来研究,我们的索引到底加给那个字段;
在这里我需要再提一下,索引一定要建立经常使用的字段上,这句话对于本次优化应该这么理解:
对于左边这个小表.x = 10,每一条我都要执行300次,因此左边这个表的使用量比较大,因为每用一次执行300次嘛,左边这个x字段使用频率比较高,因此我们就需要给这个x字段加索引;
所以呢?本次优化 t.cid = c.cid很明显,t.cid使用最为频繁,所以给该字段加索引,值得一提的是,因为本次sql语句是左外连接,对于左外连接来说,一般情况下给左边加索引,因为是左外嘛,左边刚好是小表,同理,如果是右外连接我们就需要给右表加索引;
其实很好理解,左外连接就是以左表为基准,意思就是左表的所有数据都要匹配,你全部要匹配,那你必然使用频繁,因此给左表加,右外连接以右表为基准,你右表使用频繁,那就给右表加索引,都是一个意思;
添加索引
分析完了,接下来就开始我们的优化吧;
在优化之前,我们先查询一下原生态SQL语句的执行情况,我们需要explain,就是查看一下不加索引的情况:
explain select * from teacher t left outer join course c on t.cid = c.cid where c.cnourse = "java"
执行结果:

很显然,级别都是ALL,也出现了Using where;
我们现在开始加索引:
alter table teacher add index index_teacher_cid(cid);
加完索引再试试:

我们能发现,有一张表点查询级别提到了index,其次,我们后面还增加了一个Using index索引覆盖提高了查询性能;
到这里,我们是不是少加一个索引,我们把SQL语句拿过来看看:
select * from teacher t left outer join course c on t.cid = c.cid where c.cnourse = "java"
查询条件必然是索引才对,因为要根据它去查数据,所以我漏加了一个,现在我加上后再去执行:
alter table course add index index_course_cnourse(cnourse);
加完索引再去执行试试:

首先,查询级别全部提升到fef级别,其次在查看生效的索引,两个索引被检测到了,在最终效能里面出现了两个Using index因为两章表,此条语句优化完成;
Using join buffer

在Extra字段里面出现了一个在前几章都没有见过的属性,我们来了解一下它:
出现它的原因:MySQL引擎使用了连接缓存;
详解:
说白了就是你这个SQL语句写的太差了,mysql看不下去了它给你加了一个连接缓存,出现这个就说明mysql底层动你的sql语句了,给你加了个缓存;
后面我们自主优化性能提升后,mysql觉得我写的还不错,就不给我加缓存了;
多表查询技巧
刚才我们介绍了两表查询,有些人就会问,那三张表呢?其实我告诉你,100张表也是一样的.....即便你100张表连表查询,原则也是不变的,因为没有新知识了,所以在这里我就说下多表查询的技巧;
1.有多张表,如果你要优化,首先第一个原则我在上面介绍过,小表驱动大表,那个表数据少,就把它写到等号的左边,即便查询结果一样,就比如a表数据少b表数据多,我们就 where a.id= b.id;
2.如果有多张表,索引就建立在经常查询的字段上,假设你有 a b c 三张表,一共有20个字段,这个20个字段你没有必要全加,看着三张表的20个字段里面,谁经常在查询,谁在where后面,以及一些常用字段;
今日感悟:
永远不要强力的去反对别人;
海格斯效应告诉我们:
当你反对别人时,得到的,将是更加强力的反对;
举例说明:
你剥夺了孩子玩耍的时间,那么孩子多半会把学习成绩降下来了给你看;
你剥夺了妻自由的空间,她也会什么家务都不干,你也休想安宁;
尝试用哪个另一个角度去解决问题,否则一定会面临任性的通病;
你跟我过不去,我也让你不痛快!