本文最初发布于 DataStax 官方博客,经原作者授权由 InfoQ 中文站翻译并分享。本译文发布也已获得授权,较原文有调整。
译文链接:https://www.infoq.cn/article/t7S3mF1HSCJJDE8zsdOt
关于 Apache Pulsar
Apache Pulsar 是 Apache 软件基金会顶级项目,是下一代云原生分布式消息流平台,集消息、存储、轻量化函数式计算为一体,采用计算与存储分离架构设计,支持多租户、持久化存储、多机房跨区域数据复制,具有强一致性、高吞吐、低延时及高可扩展性等流数据存储特性。
GitHub 地址:http://github.com/apache/pulsar/
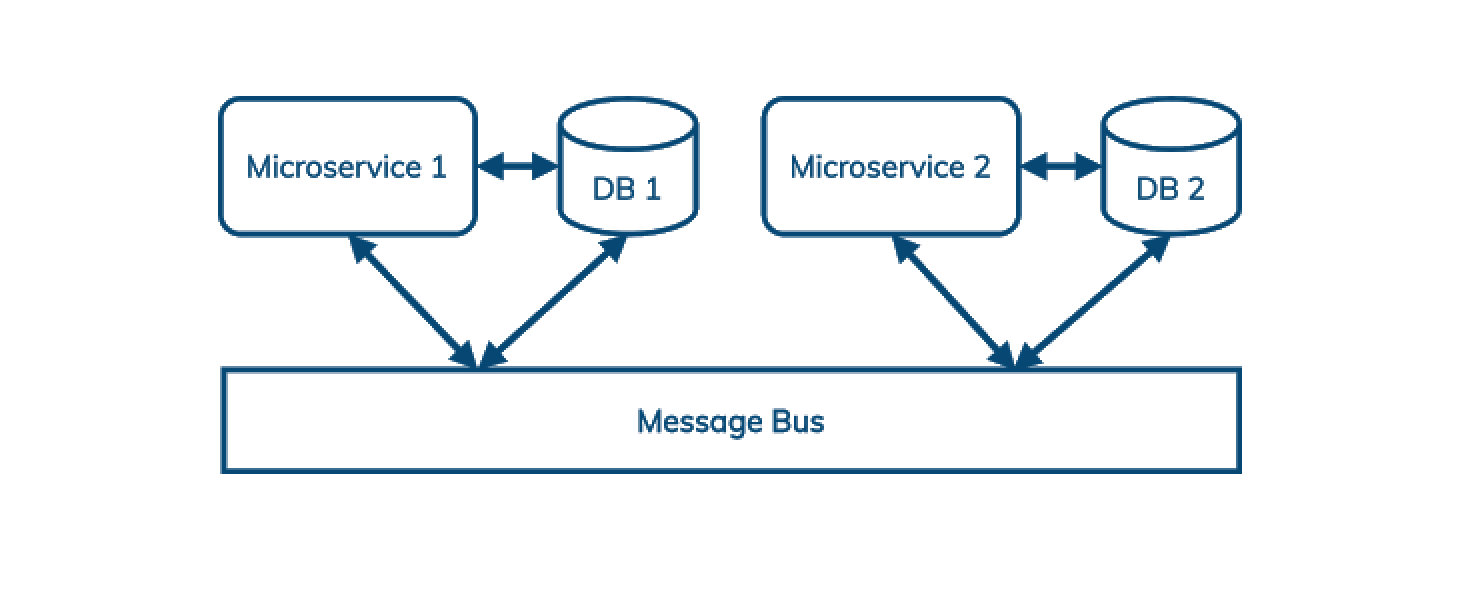
多年来,DataStax 一直关注消息领域。一个非常重要的原因是基于微服务的架构日益普及。简单来说,微服务架构使用消息总线来解耦服务之间的通信,并简化重放、错误处理和负载峰值。
有了 Cassandra 和 Astra,开发者和架构师就有了这样一个数据库生态系统:
•以开源为基础
•非常适合混合云和多云部署
•云原生,按消费计价
目前还没有满足这些需求的消息解决方案,因此我们计划打造一个。从评估最流行的 Apache Kafka 开始,我们发现它在四个方面存在不足:
1.跨地域复制
2.扩展
3.多租户
4.队列
然而,针对 Kafka 的不足之处,Apache Pulsar 却解决了所有这些问题。让我们逐项看下 Pulsar 在这四方面的优势。
Pulsar 支持跨地域复制
Kafka 被设计为在单个区域内运行,不支持跨数据中心的复制。Kafka 部署区域之外的客户端只能忍受延迟增加。有几个项目试图在客户端层面向 Kafka 添加跨数据中心的复制,但操作都很困难,而且容易失败。
Pulsar 在核心服务器上构建了跨地域复制功能,你可以在部署时选择同步或异步配置,并且可以按主题配置复制机制。生产者可以从任何地区写入共享主题,Pulsar 负责确保这些信息对各地的消费者均可见。
Pulsar 具备高可扩展性
在 Kafka 中,存储单元是一个段文件,但是复制单元是一个分区中的所有段文件。每个分区都归一个 leader 代理所有,它会复制给多个 follower。所以,当你需要给 Kafka 集群增加容量时,在新节点分担现有节点的负载之前,有些分区需要复制到新节点上。
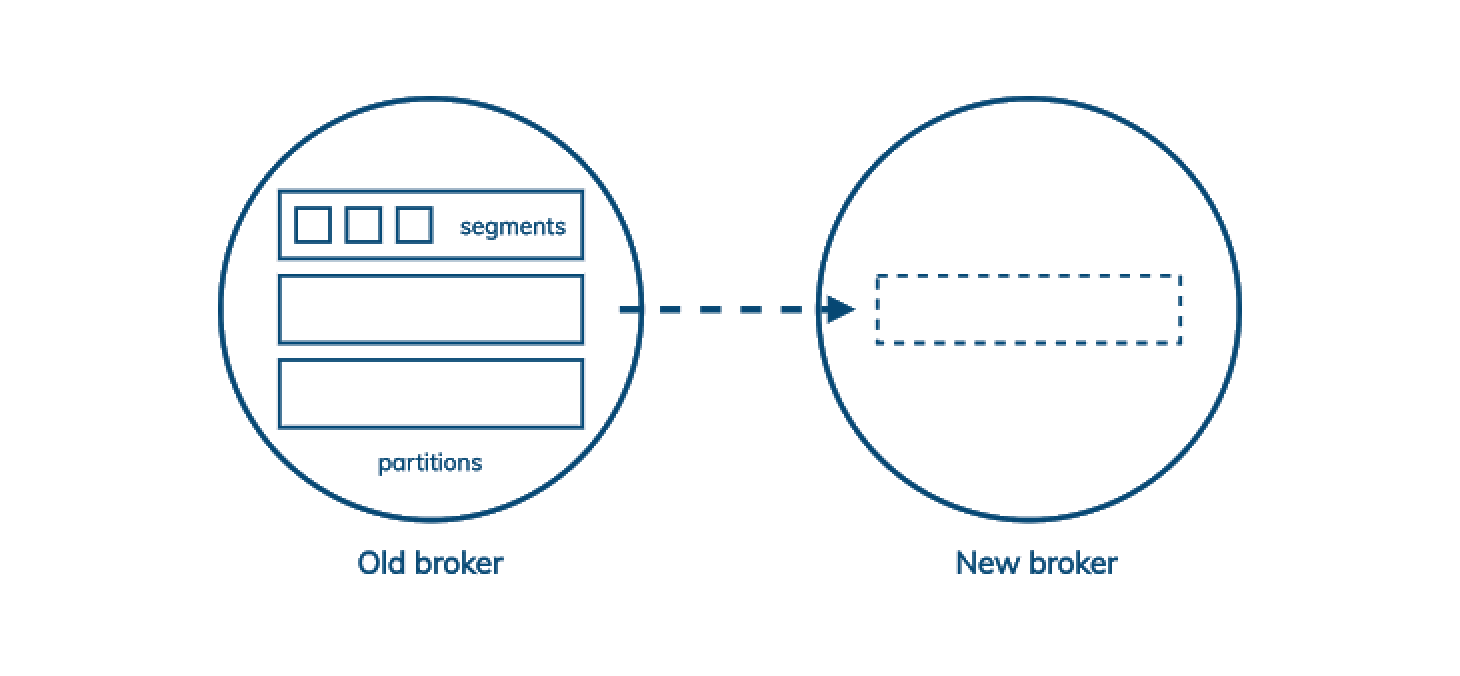
这意味着,增加 Kafka 集群的容量会使其变慢,而不是变快。如果你的容量规划恰到好处,这很好,但如果业务需求的变化比你预期的要快,那么这可能会是一个严重的问题。
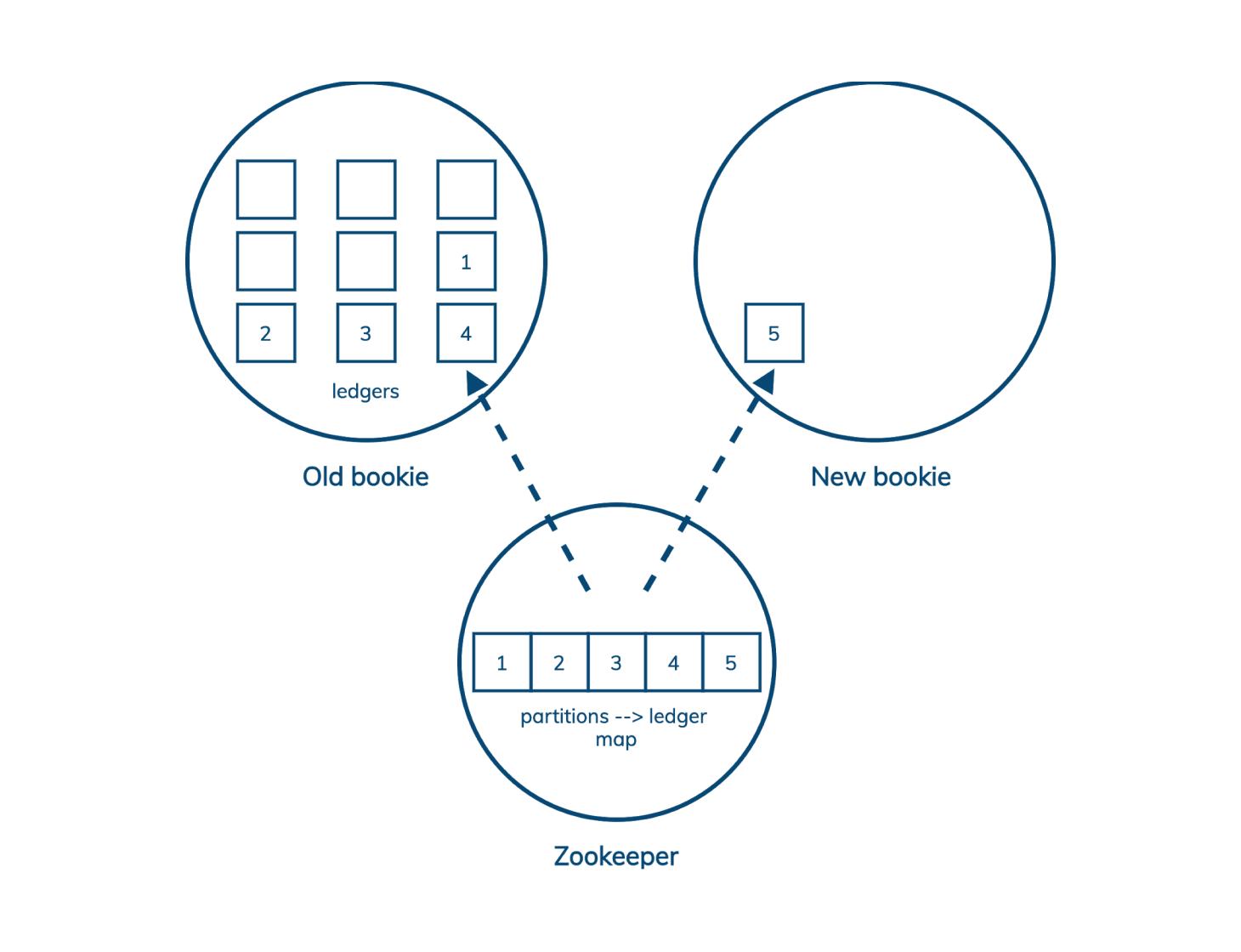
Pulsar 增加了一个间接层。(Pulsar 也将计算和存储分开,分别由 broker 和 bookie 管理,但这里,最重要的部分是 Pulsar 如何通过 BookKeeper 增加复制的粒度。)在 Pulsar 中,分区被分割成 ledger,但和 Kafka 段不同,ledger 可以单独复制,互不影响。Pulsar 在 ZooKeeper 中维护着一个 ledger 到分区的映射。因此,当我们向集群添加一个新的存储节点时,我们所要做的就是在该节点上启动一个新的 ledger。现有的数据可以保留在原来的位置,不需要集群做额外的工作。
要深入了解 Pulsar 的架构和存储模型,请阅读 Jack Vanlightly 的博文。
Pulsar 支持多租户
多租户基础设施可以跨多个用户和组织共享,同时保证它们彼此隔离。一个租户的活动不应该影响其他租户的安全或 SLA。
从根本上说,多租户可以从两个方面降低成本。首先,简单地共享单个租户没有充分利用的基础设施——将组件的成本分摊到所有用户。第二,通过简化管理——当有几十、几百或几千个租户时,管理一个实例明显简单许多。即使在一个容器化的世界里,“在这样一个共享系统上给我分配一个帐户”也比“为我提供这个服务的一个新实例”容易实现得多。全球性的问题可能由于分散在许多实例中而被掩盖。
与跨地域复制一样,多租户很难移植到没有这项设计的系统上。Kafka 是单租户设计,但 Pulsar 从内核上就支持多租户。
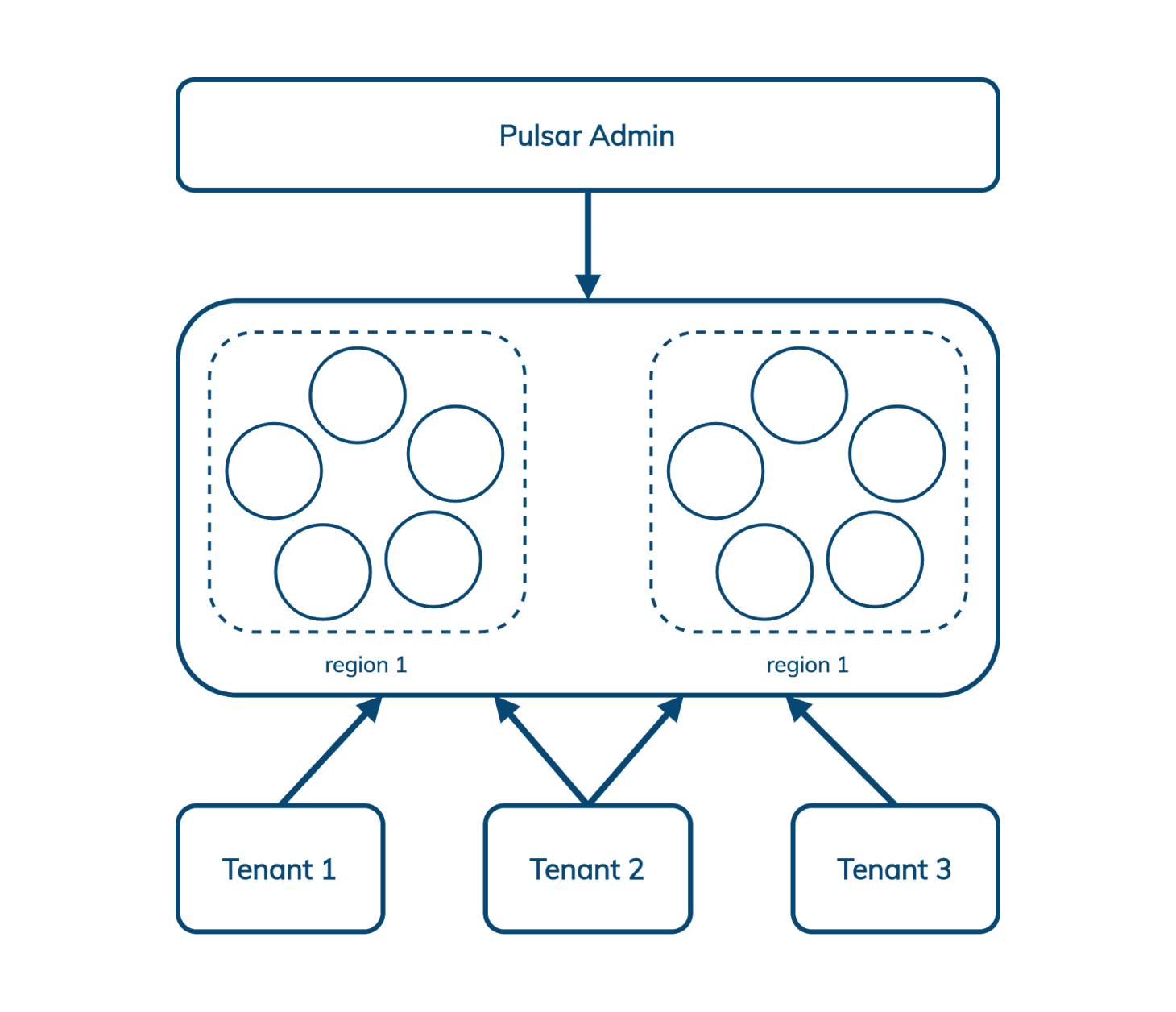
Pulsar 允许我们通过一个接口管理跨多个区域的多个租户,该接口包括身份验证和授权、隔离策略(Pulsar 可以选择在集群中划分出专供单个租户使用的硬件)和存储配额。
Pulsar 支持队列(也支持流)
Kafka 提供了一个经典的发布/订阅(publish/subscribe)消息模型——发布者发送消息给 Kafka,后者在主题中按分区排序,并给每个订阅者(或”消费者“)发送一份副本。
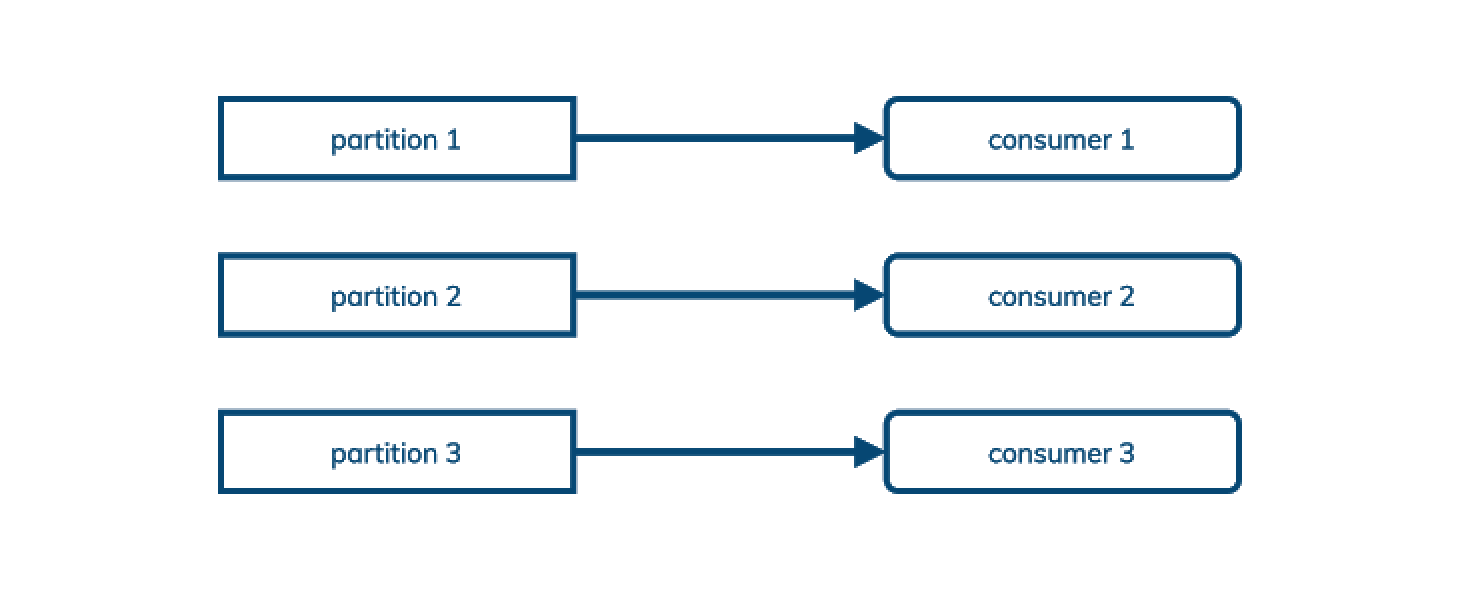
Kafka 用日志中的偏移量记录消费者已经看到了哪条消息。这意味着消息不能乱序确认,同时也意味着不能跨多个消费者共享订阅。(在其消费者分组设计中,Kafka 允许将多个分区映射到一个消费者,但不能反过来。)
这对于发布/订阅用例(有时称为流)来说很好。对于流,重要的是要以与消息发布时相同的顺序消费消息。
Pulsar 支持发布/订阅模式,但也支持队列模式,在后一种情况下,处理顺序并不重要,我们只想在任意数量的消费者之间平衡一个主题的消息:
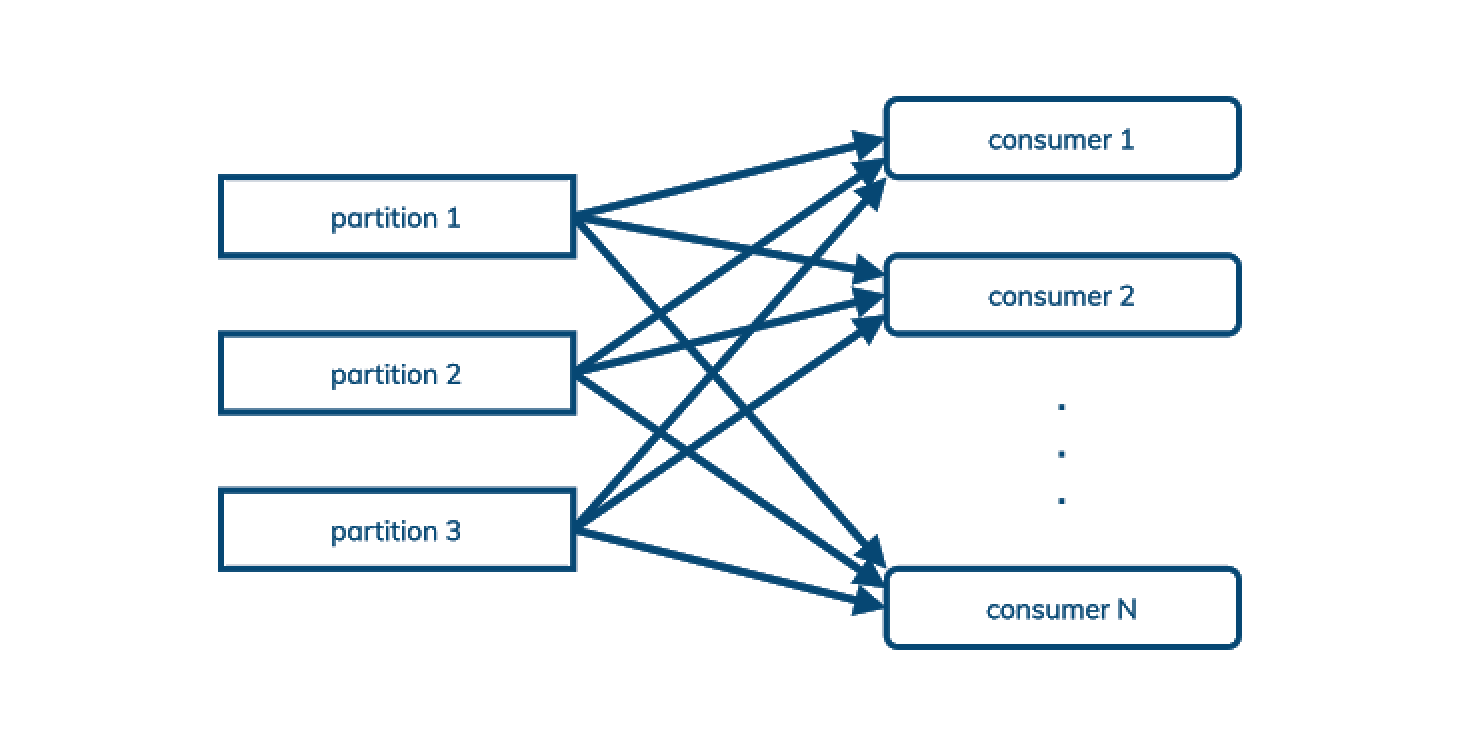
这(以及面向队列的特性,如“死信队列”和支持重新发送的否定确认)意味着 Pulsar 经常可以取代 AMQP 和 JMS 以及 Kafka 风格的发布/订阅,采用 Pulsar 的企业有机会进一步降低成本。
小结
与 Kafka 相比,Pulsar 的架构使它在跨地域复制、扩展、多租户和队列等方面具有重要的优势。近日,DataStax 也宣布加入到 Pulsar 社区,推动 Pulsar 成长和发展。
相关阅读
•理解Apache Pulsar工作原理
•Apache Pulsar Pulsar的跨地域复制机制介绍(1)
•Apache Pulsar Pulsar的跨地域复制机制介绍(2)
•Pulsar vs Kafka 统一消费模型
•Pulsar vs Kafka 分层分片架构
欢迎关注 Apache Pulsar 中文社区公众号 ApachePulsar,获取最新 Apache Pulsar 动态与技术干货。