以下内容将介绍ECCV2018的一篇目标检测的文章《CornerNet: Detecting Objects as Paired Keypoints》。该文章讲述了一个老子就是不用anchor boxes的还能做目标检测的故事。对了据说代码公布了(反正我下载的时候里面是缺东西的)。
这篇文章为什么让我喜欢看呢
1.你们用anchor boxes但我就不用
2.有了一种新的pooling方式,corner pooling
3.将很多人体姿态识别的方法和思想用到了目标检测
4.我们小组汇报我得汇报这一篇
CornerNet的动机
他的作者为什么要提出这么一个方法呢?
1.他说anchor boxes的方法画的框框太多了很麻烦,很慢。(这个方法在MS COCO上,使用Titan X(PASCAL)GPU,平均检测时间为244ms per image, 快不快大家自己感受)。
2.anchor boxes引入了许多超参数和设计选择,好多个boxes啊、大小啊、长宽比啊,再想想要配合多尺度检测,哎呀,我好柔弱…
3.啊我们有了新的pooling方法–corner pooling
那不如,我们就不用anchor boxes了吧,我们就只用两个点吧:我们找出目标物体左上角和右下角的两个点,是不是就可以成功画出这个物体外边的框框了?是。
就像下面酱紫:

(其实作者在夸自己方法好的时候,有的时候我觉得很不靠谱,他说他们可能好的原因之一,是因为你确定box的中心要考虑四边,但是我们确定两个顶角只用考虑两边。其实我觉得照着他们的这种画外接矩形的方法,知道两边也可以确定中心,是一样的…不过不知道自己有没有理解错)。
CornerNet框架
那不如就正式看一下到底是怎么两点画框框的吧。
网络总的来说长这样。
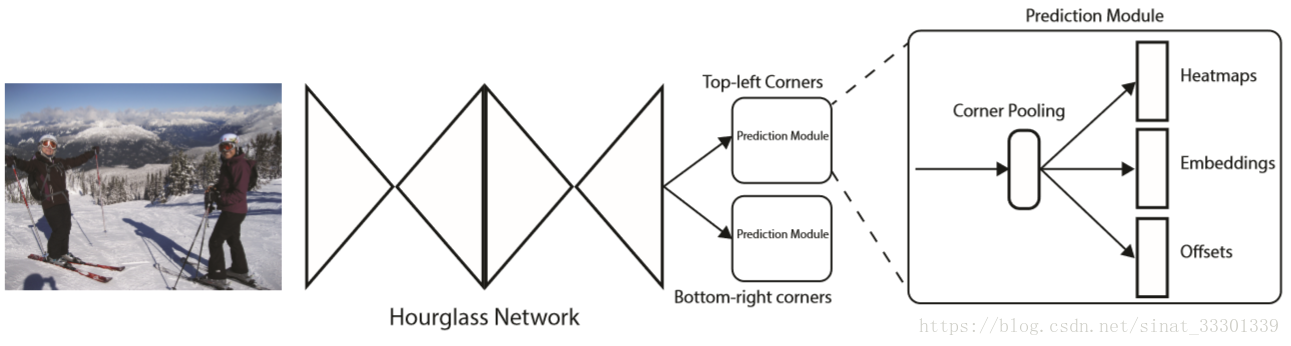
主要是一个沙漏网络加上两个预测模块。这个沙漏网络Hourglass Network,是一个人体姿态估计方向的一个方法,本宝宝不懂,为大家指一下论文,告退。
两个预测模块一个用于预测左上角那个点,另一个预测右下角那个点。每个预测模块的输出分为Heatmaps,Embedding,和offsets三个部分,他们分别的作用是指出角点的位置,角点配对,偏差矫正,我们后面慢慢具体介绍。
prediction module(corner pooling)
看一下这篇文章的亮点集中部分,预测模块部分,单独拿出一个预测模块分解(就拿左上角角点的预测模块好了)
首先它长这样。它需要预测左上角那个点的位置,它属于哪个类别,以及预测位置的偏移量。
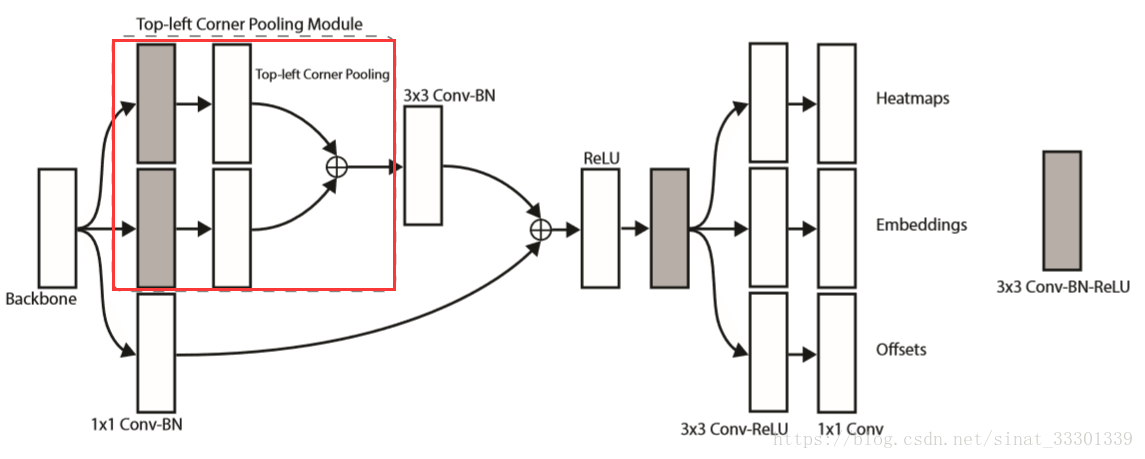
backbone指的是Hourglass Network。
网络里面什么卷积啊什么激活啊大家就自己看吧啊,前面放出来的代码链接里面也有这部分的代码,请君自己动手。
这部分里,主要的亮点就是画红框框的那部分corner pooling,然后解释一下他的输出。
corner pooling
从上面那张图我们可以看到corner pooling模块就是在两个feature map上面分别做了一个神奇的pooling,将得到的结果加和然后输出。
这个神奇的pooling展示如下(以左上角角点预测的corner pooling为例)
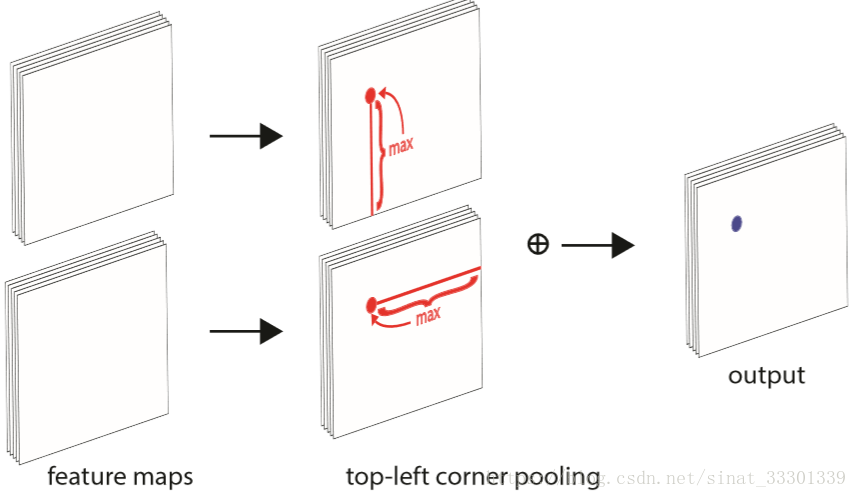
我们庸俗的来谈一谈上图的意思:就是两张feature map, 取同一个位置,对第一个feature map上的这个位置的像素点,从它开始一直向下这一列所有的像素点,取它们最大值(就是取这一列做max pooling);对第二个feature map上的这个位置的像素点,从它开始向右这一行所有像素点,取它们的最大值(max pooling+1),将这两个最大值相加,就是这个位置的输出。对所有位置进行这个操作,得到一个完整的output,这就是一个完整top-left corner pooling。
为什么会想到要这样pooling呢? 你想想,你要是高楼的最左上角那块砖,你是不是向左看,向下看都能看到你的同伴,把pooling也这样设计,是不是很神奇。
同理,bottom-right corner pooling就是向上看取最大值,向左看取最大值,然后加起来。
output
prediction module的output,也就是整个模型的output。主要分为heatmap,Embedding,offset。
heatmap:有C个chanel,C是目标类别数。没有背景chanel。每个chanel都是二进制掩模,用于表示角点的位置,是的,就是我们的终极目标找到点。
Embedding:用于角点配对。你有一堆top-left corners,又有一堆bottom-right corners,那你哪儿知道谁该跟谁是一对儿画框框。这里是用了人体姿态估计中,配对关节点的思想,为每个角点配一个Embedding,就把它当成是一个身份牌。每个对象的身份牌颜色都不一样,拿到同一种颜色身份牌的就是一家子了。这里就是embedding值最相近的top-left corner和bottom-right corner配成一对去画框框。
offset:偏移。为什么要计算这个东西呢。作者的实验里,输入是511∗511 511*511511∗511(好像我记得),但是heatmap是128∗128 128*128128∗128。把输入上的点(x,y) (x,y)(x,y)隐射到heatmap上,就得是
,先甭管人家算出来结果是多少,看到取整符号就知道要损失精度,再把heatmap上找到的位置映射回去的时候,那肯定就不准了呀,于是就有了offset(128∗128∗2,x,y 128*128*2,x,y128∗128∗2,x,y两个方向的偏移)。
这三个东西怎么组合在一起呢?在Testing Details里面作者有这样写。先对heatmap非极大值抑制 ,然后取top 100 的top-left和top 100 的bottom-right的角点,然后用offset矫正这些角点的位置。随后计算top-left和bottom-right角点Embedding的L1距离,距离大于0.5或者包含不同类别的角点不配携手走进婚姻的殿堂。能走进婚姻殿堂的就领证结婚,这一对就可以用来画框框了。
loss
我是一个慵懒的人,谈到loss的时候,我会慵懒的随便谈谈。

看到了伐,总的loss长这样。第一部分是一个focal loss的变形,用于控制heatmap;第二部分和第三部分用于控制角点的组合与分离;第三部分用于控制偏移。α,β,γ是超参(作者反正取了0.1,0.1,1)。我们分开稍微谈一谈。
第一部分

长这个鬼样子,其中pcij是预测的heatmap对于c类位置(i,j)的给分;ycij是用非标准化高斯函数增强过的ground-truth heatmap。
非标准化高斯函数增强这个操作呢?因为呀,你给ground-truth的时候,是不是就是给了一个标准的点的位置(正位置),但其他的位置(负位置)也不是完全不对的呀,你像离正位置非常近的点,画出来的框框,有时也能完全框出物体的呀。因此以正位置为圆心画圆,落在能接受半径内的点的惩罚,应该和圈外的惩罚是不一样的,作者为圈儿内的点设计了惩罚的减少量,一个非标准化的2D高斯 。其中心位于正位置,其σ是半径的1/3。这个半径大小得保证半径内的点生成的边框与ground-truth的IOU大于阈值(作者给了0.7),这样算出来的。这样子1−ycij就正好可以减少正位置周围的惩罚啦。(作者是这样讲的,由于我数学不好,具体为什么那个位置周围惩罚项会减少,我得多想段时间,想明白了再回来删了这句话吧。)
。其中心位于正位置,其σ是半径的1/3。这个半径大小得保证半径内的点生成的边框与ground-truth的IOU大于阈值(作者给了0.7),这样算出来的。这样子1−ycij就正好可以减少正位置周围的惩罚啦。(作者是这样讲的,由于我数学不好,具体为什么那个位置周围惩罚项会减少,我得多想段时间,想明白了再回来删了这句话吧。)
第二部分和第三部分
。。。。。太多了,复制不过来,点超链接看原文吧。。。。
实验
到了这里我就知道我要写完了,哈哈哈哈哈哈
实验在Titan X(PASCAL)上跑了MS COCO这个库。
做了个实验证明corner pooling有作用,又做了个实验证明角点位置的确定是关键。实验结果就不放了。
然后对比了其他方法,结果是这样的
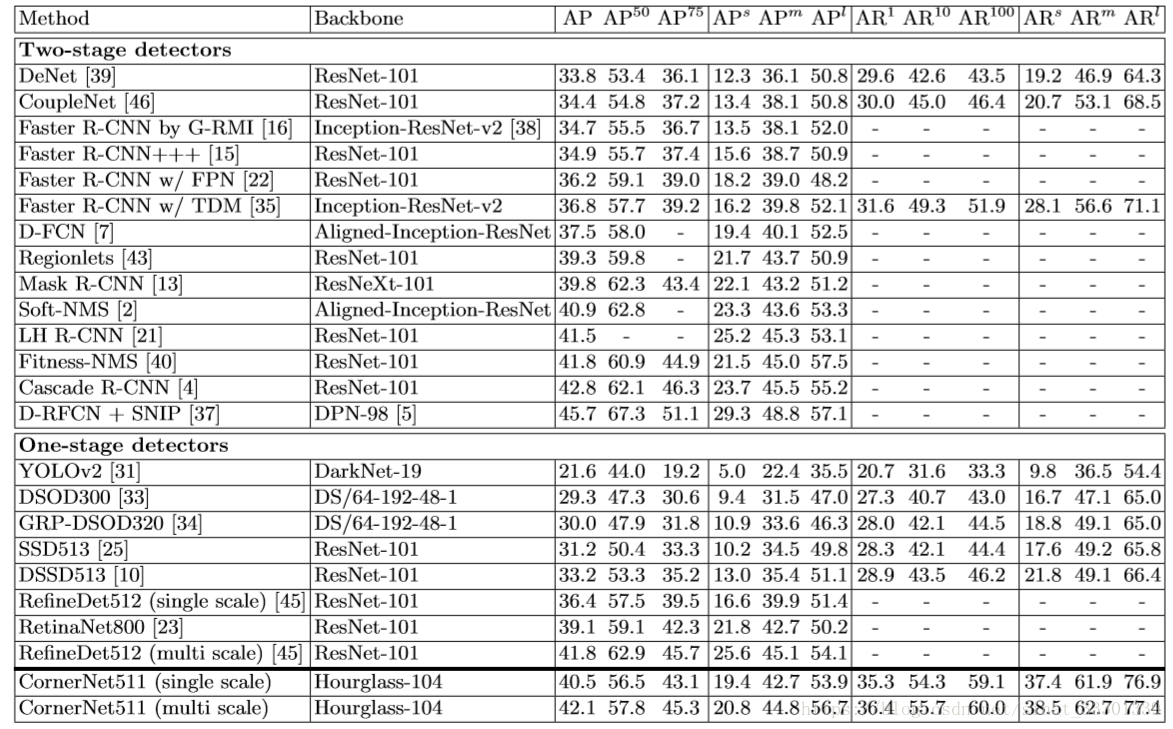
在one-stage里我们可牛了。我们还跟two-stage有得一比呢。
大家就自己看吧。
我写完了,溜了溜了。
---------------------
作者:ErinCC
来源:CSDN
原文:https://blog.csdn.net/sinat_33301339/article/details/82988945?utm_source=copy
版权声明:本文为博主原创文章,转载请附上博文链接!