介绍
从结构化数据中自动生成文本描述提高了知识库对普通用户的可访问性。这些应用包括向非专家解释数据记录,撰写体育新闻,总结多个文档中的信息,并生成对话回应。
数据到文本这个领域依然有很多挑战:首先,它们采用扁平的数据本体结构,例如数据记录的槽值对或者表格的扁平形式。这种扁平化的结构不足以在结构化数据的本体中编码丰富的语义关系,尤其是表,这些语义关系可以利用这些语义知识进一步改进表的表示。其次,一些数据集只关注少量的领域或知识图,因此提供有限数量的谓词和数据本体。此外,由于任务的性质和自动生成过程的原因,其中一些算法在数据输入和句子之间只存在松散的对齐。
为了解决这些问题,我们提出了structured DAta-Record-to-Text(DART),目标是覆盖维基百科中的多样的表格,比特定域的数据集要丰富。我们还引入了新的表上的树本体注释,它将平面表模式转换为树结构的语义框架。 树本体反映了表模式中的核心和辅助关系,并且自然地跨许多领域出现。因此,DART为从各种数据源(包括WikiSQL和WikiTableQuestions)提取的树状结构语义框架提供高质量的句子注释。我们评估了DART上的几种最先进的数据到文本模型,发现尽管这些模型在特定领域上表现很好,但却由于DART的领域丰富的语义结构而表现不好。
我们的贡献:
- 我们为结构化数据到文本的生成提出了一个很大且开放域的数据集,并把他们转换成树结构,这种层级的输入是我们和其他语料的区别。
- 我们对几个最先进的数据到文本模型进行了基准测试,以表明DART引入了新的泛化挑战。
- 我们证明,使用DART进行数据增强可以提高WebNLG 2017数据集上现有模型的性能。考虑到DART的开放领域特性,我们希望该结果能够推广到其他数据到文本的数据集。
数据采集
整体流程如图1所示,包含了几个数据集部分。
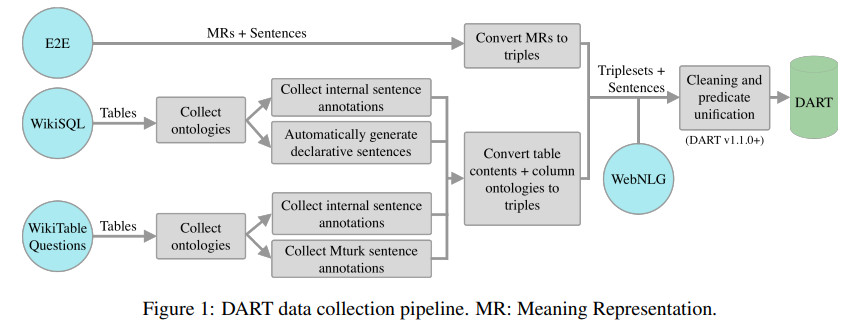
树本体与表的句子标注
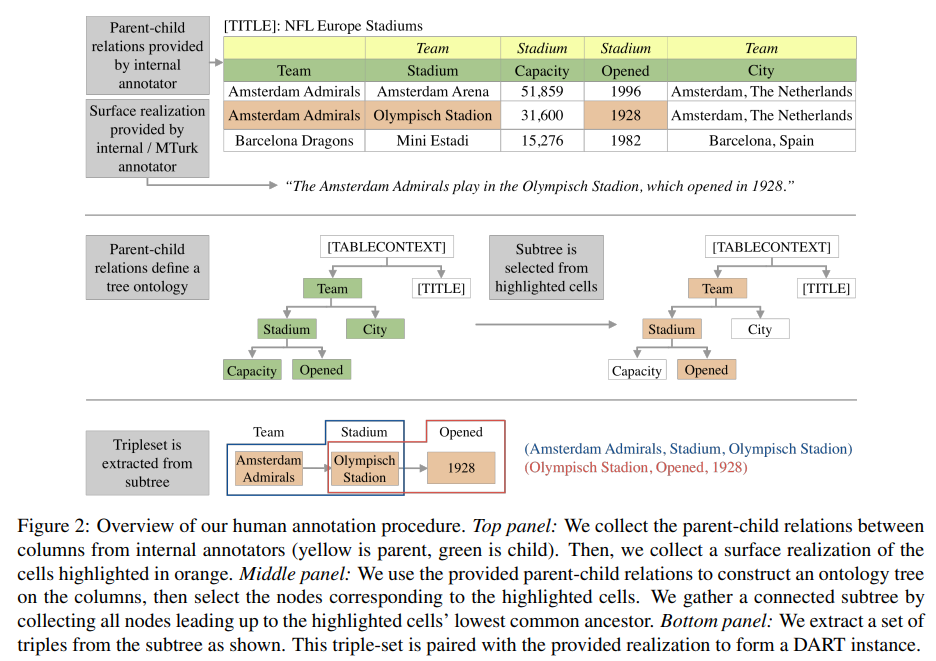
连通分量提取
这一部分筛选掉一些与无法联通或联通错误的sample,或者人为进行修改。