数据同步,顾名思义就是不同系统的数据进行同步处理。而业务系统所涉及的数据库同步是重中之重,虽然大部分数据库都提供了导入导出的工具,但是数据存储到各个地方,Hive、Hbase、MySQL、Oracle 等各种各样的不同数据库,然而要把数据同步到指定不同类型的存储库是非常麻烦。那该如何统一实现数据源同步?下面介绍几种常用的同步的方案和工具。
1、Sqoop
Apache Sqoop 是一种工具,用于在 Apache Hadoop 和外部数据存储(如关系数据库,企业数据仓库)之间高效传输批量数据。
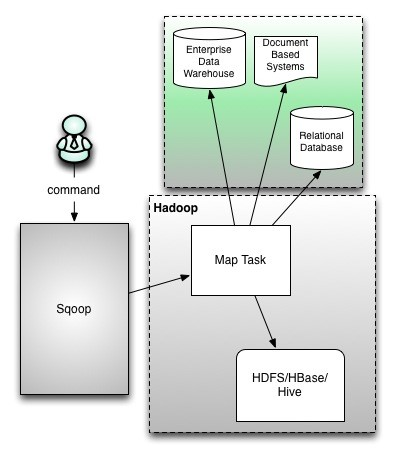
Sqoop 用于将数据从外部数据存储导入 Hadoop Hdfs 或 Hive 和 HBase 等相关 Hadoop 生态系统。同样,Sqoop 还可用于从 Hadoop 或其生态系统中提取数据,并将其导出到外部数据存储区,如关系数据库、数据仓库。Sqoop 适用于 Oracle,MySQL,Postgres 等关系数据库。
Sqoop 数据导入命令示例如下。
sqoop import
-connect jdbc:mysql://localhost:3306/sqoop
-username root
-password 123456
-table emp_etl
-m 3
-hive-import
-create-hive-table
-hive-table emp_mysql
通过命令行界面执行 Sqoop 命令。也可以使用 Java API 访问 Sqoop。Sqoop 解析命令行生成 MapRedure 并只启动 Hadoop Map 作业以导入或导出数据,因为只有在需要聚合时才需要 Reduce 阶段。Sqoop 只是导入和导出数据, 它没有做任何聚合。
映射作业根据用户定义的数量(-m 3)启动多个映射器。对于 Sqoop 导入,将为每个映射器任务分配一部分要导入的数据。Sqoop 在映射器之间平均分配输入数据以获得高性能。然后,每个映射器使用 JDBC 创建与数据库的连接,并获取由 Sqoop 分配的数据部分,将其写入 HDFS 或 Hive 或 HBase。
2、Datax
DataX 是阿里开发的一个异构数据源离线同步工具,致力于实现包括关系型数据库(MySQL、Oracle 等)、HDFS、Hive、ODPS、HBase、FTP 等各种异构数据源之间稳定高效的数据同步功能。

DataX 本身作为离线数据同步框架,采用 Framework + plugin 架构构建。将数据源读取和写入抽象成为 Reader/Writer 插件,纳入到整个同步框架中。

Reader:为数据采集模块,负责采集数据源的数据,将数据发送给 Framework。
Writer: 为数据写入模块,负责不断向 Framework 取数据,并将数据写入到目的端。
Framework:用于连 接reader 和writer ,作为两者的数据传输通道,并处理缓冲,流控,并发,数据转换等核心技术问题。
Datax 使用比较简单,只下载 Datax 解压,配置需要运行环境,通过命令运行写好的 json 文件既可以执行任务,另外可以通过二次开发插件支持新的数据源类型,易拓展。
{
"job": {
"content": [
{
"reader": {
"name": "xxxreader",
...
},
"writer": {
"name": "xxxwriter",
...
}
}
],
...
}
}
3、Canal
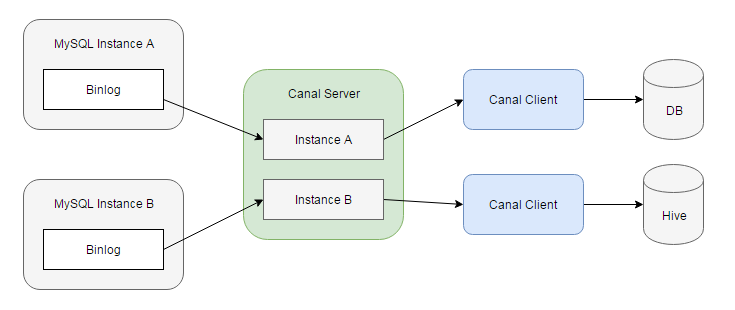
无论是 Sqoop 还是 Datax 都是属于离线同步, 不支持实时的数据抽取。这里说个 MySQL 数据库的同步组件
Canal,非常便捷地将 MySQL 中的数据抽取到任意目标存储中。
原理就是 Canal 伪装成 MySQL 从节点,读取 MySQL 的 binlog(一个二进制格式的文件,它记录了数据库的所有改变,并以二进制的形式保存在磁盘中。),生成消息,客户端订阅这些数据变更消息,处理并存储。只要开发一个 Canal 客户端就可以解析出 MySQL 的操作,再将这些数据发送到大数据流计算处理引擎,即可以实现对 MySQL 实时处理。
4、kettle
Kettle 是一款开源的 ETL 工具,实现对各种数据源读取,操作和写入数据,Kettle 无需安装解压即可使用,可通过客户端进行配置和执行作业。Kettle 中有两种脚本文件,transformation 和 job,transformation 完成针对数据的基础转换,job 则完成整个工作流的控制。
5、Informatica PowerCenter
Informatica PowerCenter 是世界级的 企业数据集成平台,从异构的已有系统和数据源中抽取数据,用来构建和管理企业的数据仓库,从而帮助企业做出快速、正确的决策。此产品为满足企业级要求而设计,可以提供企业部门的数据和非关系型数据之间的集成,如XML,网站日志,关系型数据,主机和遗留系统等数据源。
小结
那我们该如何选择合适同步的工具。大数据平台是与 Hadoop 集群相挂钩,在离线同步一般选择 Sqoop,Sqoop 从一开始就是为大数据平台的数据采集业务服务,而且作为 Apache 顶级的项目,Sqoop 比起 Datax 更加可靠,如果涉及阿里自身的数据库系列选择 Datax 是一个不错的选择。在实时同步数据,一般采用 Kafka 作为中间组件,跟 Canal 结合实现 MySQL 到 Hive 增量数据同步。kettle 和 Informatica PowerCenter 一般在建设数仓中使用,通过客户端配置 ETL 任务定制。