这一篇博客,还是接着说那些常见的反爬虫措施以及我们的解决办法。同样的,如果对你有帮助的话,麻烦点一下推荐啦。
一、防盗链
这次我遇到的防盗链,除了前面说的Referer防盗链,还有Cookie防盗链和时间戳防盗链。Cookie防盗链常见于论坛、社区。当访客请求一个资源的时候,他会检查这个访客的Cookie,如果不是他自己的用户的Cookie,就不会给这个访客正确的资源,也就达到了防盗的目的。时间戳防盗链指的是在他的url后面加上一个时间戳参数,所以如果你直接请求网站的url是无法得到真实的页面的,只有带上时间戳才可以。
这次的例子是天涯社区的图片分社区:

这里我们先打开开发者工具,然后任意选择一张图片,得到这个图片的链接,然后用requests来下载一下这张图片,注意带上Referer字段,看结果如何:
import requests
url = "http://img3.laibafile.cn/p/l/305989961.jpg"
headers = {
"Referer": "http://pp.tianya.cn/",
"UserAgent":"Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/68.0.3440.75 Safari/537.36"
}
res = requests.get(url)
with open('test.jpg', 'wb') as f:
f.write(res.content)
我们的爬虫正常运行了,也看到生成了一个test.jpg文件,先别急着高兴,打开图片看一下:

一口老血吐了出来,竟然还有这种套路!怎么办呢?往下看!
解决办法:
既然他说仅供天涯社区用户分享,那我们也成为他的用户不就行了吗?二话不说就去注册了个账号,然后登录,再拿到登录后的Cookie:
__auc=90d515c116922f9f856bd84dd81; Hm_lvt_80579b57bf1b16bdf88364b13221a8bd=1551070001,1551157745; user=w=EW2QER&id=138991748&f=1; right=web4=n&portal=n; td_cookie=1580546065; __cid=CN; Hm_lvt_bc5755e0609123f78d0e816bf7dee255=1551070006,1551157767,1551162198,1551322367; time=ct=1551322445.235; __asc=9f30fb65169320604c71e2febf6; Hm_lpvt_bc5755e0609123f78d0e816bf7dee255=1551322450; __u_a=v2.2.4; sso=r=349690738&sid=&wsid=71E671BF1DF0B635E4F3E3E41B56BE69; temp=k=674669694&s=&t=1551323217&b=b1eaa77438e37f7f08cbeffc109df957&ct=1551323217&et=1553915217; temp4=rm=ef4c48449946624e9d7d473bc99fc5af; u_tip=138991748=0
注意:Cookie是有时效性的,具体多久就会失效我没测试。紧接着把Cookie添加到代码中,然后运行,可以看到成功把图片下载下来了:

搞了这么久才下了一张图片,我们怎么可能就这么满足呢?分析页面可知一个页面上有十五张图片,然后往下拉的时候会看到"正在加载,请稍后":

我们立马反应过来这是通过AJAX来加载的,于是打开开发者工具查看,可以找到如下内容:
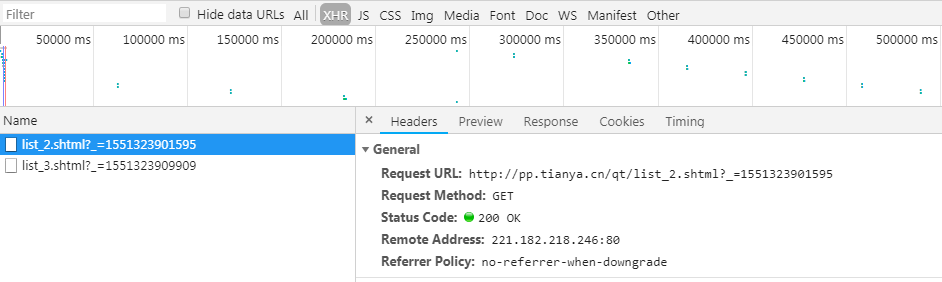
可以看到每个链接“?”前面的部分都是基本一样的,“list_”后面跟的数字表示页数,而“_=”后面这一串数字是什么呢?有经验的人很快就能意识到这是一个时间戳,所以我们来测试一下:
import time
import requests
t = time.time()*1000
url = "http://pp.tianya.cn/qt/list_4.shtml?_={}".format(t)
res = requests.get(url)
print(res.text)
运行之后得到了我们想要的结果。现在我们已经能用代码构造链接了,那我们怎么知道最多有多少页呢?我们先继续拖动滚轮下拉页面,发现出现第5页之后就没有了:

这怎么办呢?不急,我们不是已经能自己构造链接了嘛,我们可以通过改变“list”后面的数字来得到更多的页面啊。不过我自己测试的结果是最多只有15页,之后再怎么增大数字也没用了,应该是服务器做了限制,最多只给15页的数据。下图是我把数字改为16后返回的结果:
最后编写程序并运行,就能把图片下载下来了:

完整代码已上传到GitHub!
二.随机化网页源码
用display:none来随机化网页源码,有网站还会随机类和id的名字,然后再加点随机的tr和td,这样的话就增大了我们解析的难度。比如全网代理IP:

解决办法:
可以看到每个IP都是包含在一个class为“ip”的td里的,所以我们可以先定位到这个td,然后进行下一步解析。虽然这个td里面包含了很多的span标签和p标签,而且也每个标签的位置也没有什么规律,不过还是有办法解析的。方法就是把这个td里的所有文字提取出来,然后把那些前后重复的部分去除掉,最后拼接到一起就可以了,代码如下:
1 et = etree.HTML(html) # html:网页源码 2 for n in range(1, 21): 3 lst = et.xpath('//table/tbody/tr[{}]/td[1]//text()'.format(n)) 4 proxy = "" 5 for i in range(len(lst) - 1): 6 if lst[i] != lst[i + 1]: 7 proxy += lst[i] 8 proxy += lst[-1] 9 print(proxy)
最后就能得到我们想要的数据了。不过我们得到的端口数据和网页上显示的数据是不一样的,这是因为端口数据是经过了JS混淆的,至于怎么破解,下次会分享出来。