一、写在前面
当你看着你的博客的阅读量慢慢增加的时候,内心不禁有了些小激动,但是不得不吐槽一下--博客园并不会显示你的博客的总阅读量是多少。而这一篇博客就将教你怎么利用队列这种结构来编写爬虫,最终获取你的博客的总阅读量。
二、必备知识
队列是常用数据结构之一,在Python3中要用queue这个模块来实现。queue这个模块实现了三种队列:
class queue.Queue(maxsize=0):FIFO队列(first in first out),先进先出,第一个进入队列的元素会第一个从队列中出来。maxsize用于设置队列里的元素总数,若小于等于0,则总数为无限大。
class queue.LifoQueue(maxsize=0):LIFO队列(last in first out),后进先出,最后一个进入队列的元素会第一个从队列中出来。maxsize用于设置队列里的元素总数,若小于等于0,则总数为无限大。
class queue.PriorityQueue(maxsize=0):优先级队列(first in first out),给队列中的元素分配一个数字标记其优先级。maxsize用于设置队列里的元素总数,若小于等于0,则总数为无限大。
这次我使用的是Queue这个队列,Queue对象中包含的主要方法如下:
Queue.put(item, block=True, timeout=None):将元素放入到队列中。block用于设置是否阻塞,如果timeout为正数,表明最多阻塞多少秒。
Queue.get(block=True, timeout=None):从队列中删除并返回一个元素,如果队列为空,则报错。block用于设置是否阻塞,如果timeout为正数,表明最多阻塞多少秒。
Queue.empty():判断队列是否为空,如果队列为空,返回False,否则返回True。
三、具体步骤
首先进入博客,然后打开开发者工具选择查看元素,如下:
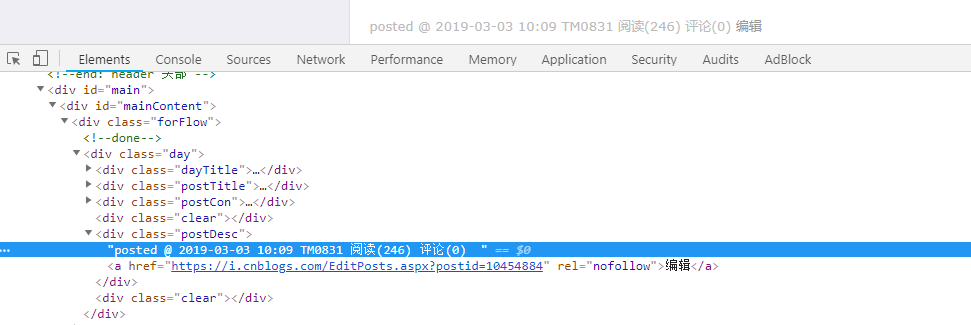
这里只要定位到类名为postDesc的div节点就可以提取到我们想要的阅读量信息了,这一步是很简单的。问题在于如何实现翻页?先定位到下一页查看一下元素:
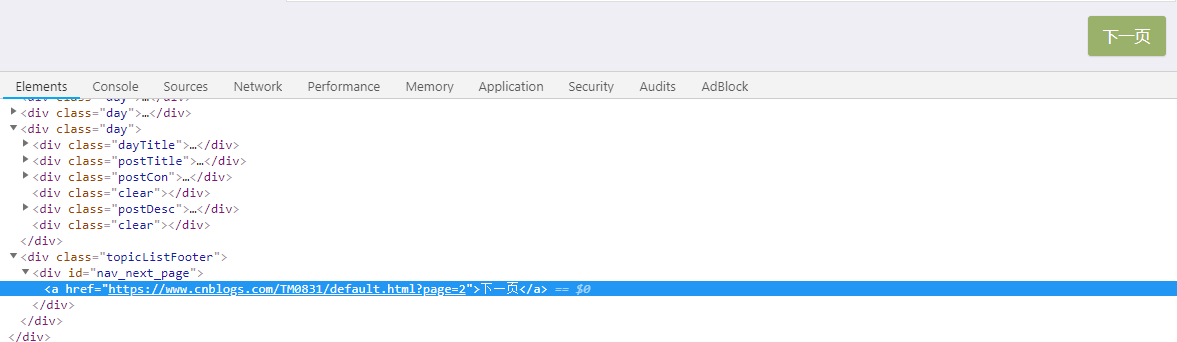
好像定位到id为nav_next_page的div节点就行了,是这样吗?点击进入下一页,然后再次定位查看一下:
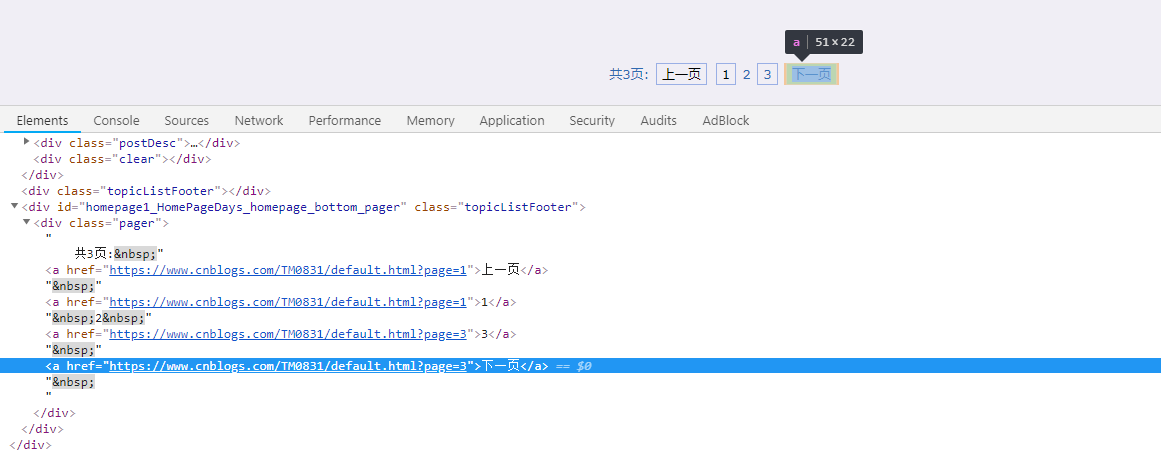
可以看到用之前定位div节点的方法已经不行了,怎么办呢?我的解决办法是用正则表达式进行匹配,因为下一页对应的元素都是这样的:
<a href="链接">下一页</a>
所以只需要进行一下正则匹配就能获取下一页的链接了,如果获取不到,就说明已经是最后一页了!
四、完整代码
1 """ 2 Version: Python3.5 3 Author: OniOn 4 Site: http://www.cnblogs.com/TM0831/ 5 Time: 2019/3/11 10:46 6 """ 7 import re 8 import queue 9 import requests 10 from lxml import etree 11 12 13 class CrawlQueue: 14 def __init__(self): 15 """ 16 初始化 17 """ 18 self.q = queue.Queue() # 爬取队列 19 self.username = input("请输入您的博客名称:") 20 self.q.put("http://www.cnblogs.com/" + self.username) 21 self.urls = ["http://www.cnblogs.com/" + self.username] # 记录爬取过的url 22 self.result = [] # 储存阅读量数据 23 24 def request(self, url): 25 """ 26 发送请求和解析网页 27 :param url: 链接 28 :return: 29 """ 30 res = requests.get(url) 31 et = etree.HTML(res.text) 32 lst = et.xpath('//*[@class="postDesc"]/text()') 33 for i in lst: 34 num = i.split(" ")[5].lstrip("阅读(").rstrip(")") 35 self.result.append(int(num)) 36 37 # 下一页 38 next_page = re.search('<a href="(.*?)">下一页</a>', res.text) 39 if next_page: 40 href = next_page.group().split(' ')[-1].replace('<a href="', '').replace('">下一页</a>', '') 41 if href not in self.urls: # 确保之前没有爬过 42 self.q.put(href) 43 self.urls.append(href) 44 45 def get_url(self): 46 """ 47 从爬取队列中取出url 48 :return: 49 """ 50 if not self.q.empty(): 51 url = self.q.get() 52 self.request(url) 53 54 def main(self): 55 """ 56 主函数 57 :return: 58 """ 59 while not self.q.empty(): 60 self.get_url() 61 62 63 if __name__ == '__main__': 64 crawl = CrawlQueue() 65 crawl.main() 66 print("您的博客总阅读量为:{}".format(sum(crawl.result)))
完整代码已上传到GitHub!