很难受,由于这两天重装了系统,又得重新配置环境了,而我在安装tesserocr的时候踩了一些坑,于是想写出来分享一下。
一.安装tesseract
要安装tesserocr,首先要下载tesseract,它是给tesserocr提供支持的。下载地址为:https://digi.bib.uni-mannheim.de/tesseract/。
打开之后可以看到有很多文件,带dev的为开发版本,不带dev的为稳定版本,我们选择下载不带dev的版本,比如最新的这个:tesseract-ocr-w64-setup-v4.1.0.20190314.exe。下载完成之后运行安装,一直点击next,直到出现如下页面:
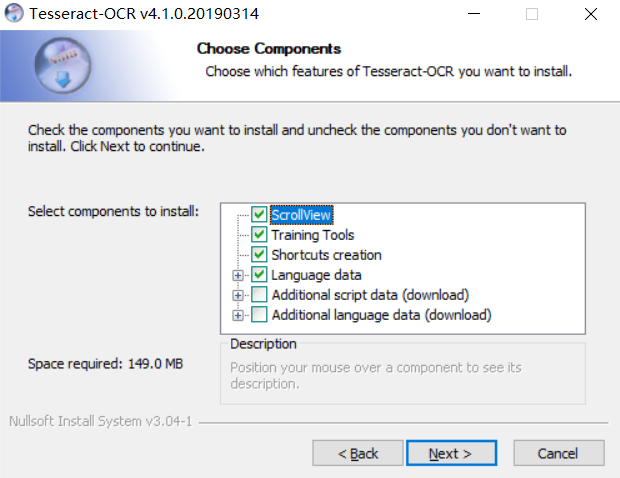
在Additional language data中包含了OCR支持识别的各国语言包,可以根据情况选择,我这里就选择了中文的:
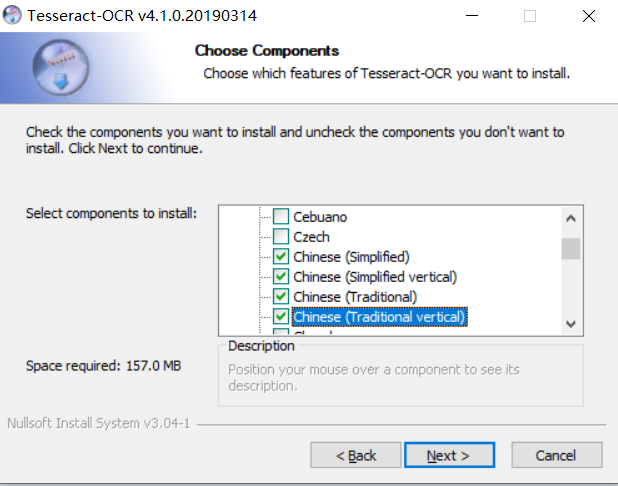
之后的过程就不用赘述了,这里因为我只选择了中文语言包,所以下载起来还是很快的。
二.安装tesserocr
使用pip install tesserocr进行安装。我在安装的时候碰到了下面这个问题:

解决办法:
1)下载对应版本的whl包进行安装,下载地址:https://github.com/simonflueckiger/tesserocr-windows_build/releases。
比如我的Python版本是3.7,电脑是Windows64位,所以我下载的是:tesserocr-2.4.0-cp37-cp37m-win_amd64.whl。下载完之后使用pip进行安装:

2)安装Visual Studio,比如VS2017。这个怎么说呢,虽然它里面包含了很多包,安装起来也很简单,但是如果你想卸载就很蛋疼了,而且这个软件会占用C盘几个G的空间,所以我个人是不推荐使用这个办法的。
三.配置环境变量
首先找到你tesseract安装的目录位置,比如E:Tesseract-OCR,然后将该路径添加到环境变量path中:

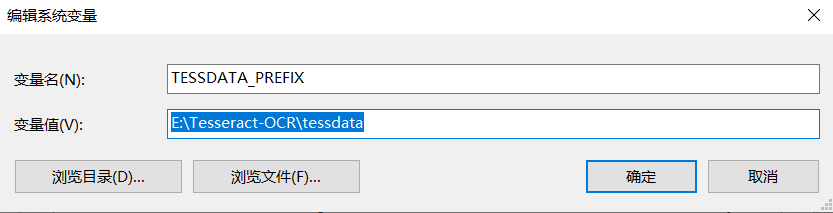
之后新建一个系统变量TESSDATA_PREFIX,对应的值为:E:Tesseract-OCR essdata:
四.运行示例
下面是一个简单的示例,使用的图片为:

代码很简单,如下:
1 import tesserocr 2 from PIL import Image 3 4 5 img = Image.open("test.jpg") 6 print(tesserocr.image_to_text(img))
在第一次运行的时候可能会出现下面这个错误:
RuntimeError: Failed to init API, possibly an invalid tessdata path: E:Python/tessdata/
解决办法:将tesseract安装目录下的tessdata文件夹复制到你的Python安装目录下。
最终运行结果为:@ python’
我们可以看到tesserocr在不处理图片直接使用的情况下,识别的效果其实是比较差的,如果我们想要提高OCR识别的准确度,可以进行相应的识别训练。