GitHub 上有哪些优秀的 Python 爬虫项目?
大型爬虫项目:
一个高速的爬虫程序。最大的特点是它不是像普通爬虫那样只爬取结构和静态资源,Photon被偏向设计为信息收集爬虫,它有非常灵活的规则设置和利于阅读的导出结果。
Photon提供的各种选项可以让用户按照自己的方式抓取网页。
它最厉害的地方在于数据提取
默认情况下,Photon在抓取时会提取以下数据:
网址(范围内和范围外的)
带参数的网址(http://example.com/gallery.php?id=2)
情报(电子邮件,社交媒体帐户,亚马逊水桶等)
文件(pdf,png,xml等)
JavaScript等文件
基于自定义正则表达式模式的字符串
提取的信息按下图方式保存。

一个国人编写的强大的网络爬虫系统并带有强大的WebUI。采用Python语言编写,分布式架构,支持多种数据库后端,强大的WebUI支持脚本编辑器,任务监视器,项目管理器以及结果查看器。
它可以实现:
- python 脚本控制,可以用任何你喜欢的html解析包(内置 pyquery)
- WEB 界面编写调试脚本,起停脚本,监控执行状态,查看活动历史,获取结果产出
- 数据存储支持MySQL, MongoDB, Redis, SQLite, Elasticsearch; PostgreSQL 及 SQLAlchemy
- 队列服务支持RabbitMQ, Beanstalk, Redis 和 Kombu
- 支持抓取 JavaScript 的页面
- 组件可替换,支持单机/分布式部署,支持 Docker 部署
- 强大的调度控制,支持超时重爬及优先级设置
- 支持python2&3
实用型爬虫项目:
财务报表下载小助手。
动态示意图:

爱奇艺等主流视频网站的VIP视频破解助手(暂只支持PC和手机在线观看VIP视频!)
感谢Python3二维码生成器作者:https://github.com/sylnsfar/qrcode
无需Python3环境,在Windows下,解压即用!
爬取并分析北上广深链家网租房房源全部数据,得出租金分布,租房考虑因素等建议(北上广深租房图鉴)
主要的文件有:
- house_data_crawler.py:爬取北上广深租房房源数据的代码(带说明和注释,需要安装mongodb)
- info.py:租房类型和各城市各区域的信息,供house_data_crawler.py调用
- 北上广深租房图鉴.ipynb:Jupyter notebook代码,对北上广深租房数据进行分析
- data_sample.csv:租房数据,这里只随机选择了12000条,每城市3000条
用Python抢火车票简单代码,有爬虫基础就很好操作。
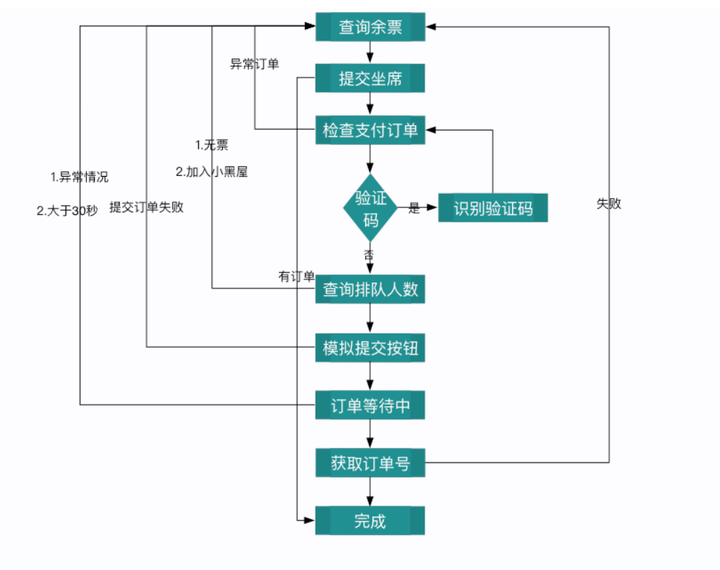
本系统是一个主要使用python3, celery和requests来爬取职位数据的爬虫,实现了定时任务,出错重试,日志记录,自动更改Cookies等的功能,并使用ECharts + Bootstrap 来构建前端页面,来展示爬取到的数据。
一个可以用于下载图片、视频、文件的小工具,有下载进度显示功能。稍加修改即可添加到自己的爬虫中。
《笔趣看》盗版小说网站,爬取小说工具
本系统是一个主要使用python3, celery和requests来爬取职位数据的爬虫,实现了定时任务,出错重试,日志记录,自动更改Cookies等的功能,并使用ECharts + Bootstrap 来构建前端页面,来展示爬取到的数据。
爬虫最大的敌人之一是什么?没错,验证码!Geetest作为提供验证码服务的行家,市场占有率还是蛮高的。
动态示意图:
各种爬虫---大众点评,安居客,58,人人贷,拍拍贷, IT桔子,拉勾网,豆瓣,搜房网,ASO100,气象数据,猫眼电影,链家,PM25.in...
以hao123为入口页面,滚动爬取外链,收集网址,并记录网址上的内链和外链数目,记录title等信息。windows7 32位上测试,目前每24个小时,可收集数据为10万左右
2019计算机视觉顶会CVPR全部论文PDF论文爬虫
百度文库word文章爬取,学生党超实用!支持txt,word,pdf,ppt类型资源的下载
其它有趣的Python爬虫小项目:
爬取了西瓜直播(今日头条旗下APP)各类型游戏的主播直播数据107.5万条,并分析直播平台和游戏主播行业是否真如我们想象般的暴利。适合Python爬虫学习者、Python数据分析学习者、Pandas使用者、数据可视化学习者
知乎关系网爬虫
按全国各个城市抓取飞猪“景点门票”栏的景点门票销售数据,并且分析五一哪些景点会人挤人,哪些景点值得一去。同样适合Python爬虫学习者、Python数据分析学习者、Pandas使用者、数据可视化学习者学习。
随机抓取吴亦凡发表《大碗宽面》微博的微博转发数据10万条,并分析该条微博的真假转发比例,以及大家对于这首歌的情感倾向如何
爬取了外籍人员招聘网站JobLEADChina上的外籍英语老师招聘数据945条,万行教师人才网上的英语老师招聘数据5780条,以及微信群成员信息498条,分析外教教师的招聘状况。洋外教的工资学历情况一目了然。
一个微信公众号文章采集器,用于采集微信公众号文章并保存至word文档。
项目很简单,主要包括以下文件:
- article_collector.py:主文件,用于爬取公众号文章以及把文章储存为word文档;
- add_hyperlinks.py:用于在word文档中添加超链接
- gzh.txt:待爬取的公众号列表
- 比心.JPG:用来撒狗粮的,不用管
一小时入门Python3网络爬虫。
内容有包括:
网络小说下载(静态网站)-biqukan
优美壁纸下载(动态网站)-unsplash
爱奇艺VIP视频下载
PUBG-juediqiusheng-data_analysis
项目主要分析绝地求生72万场比赛的数据,并结合数据给出吃鸡攻略,用数据吃鸡!
主要的文件为:
- 20G 绝地求生比赛数据集分析.ipynb:Jupyter Notebook格式,代码和说明都在这里
- erangel.jpg:绝地海岛艾伦格地图
- miramar.jpg:热情沙漠米拉玛地图
这个项目主要是模拟登录微博手机网页端,爬取指定微博下面的评论数据,并且下载评论中的表情包图片
主要的文件为:
photo_crawler.py:代码(带说明和注释)
cookie.txt:爬取电脑端网页时的cookie,具有时效性,需要自行更新
XSStrike是一个Cross Site Scripting检测套件,配备四个手写解析器,一个智能有效载荷生成器,是一个强大的模糊引擎和一个非常快速的爬虫。