20172319 2018.05.09-05.21
《Java程序设计教程》第10周学习总结
目录
教材学习内容总结
第十三章 集合:
- 13.1 集合与数据结构:
集合: 一种对象,类似保存其他对象的存储库。
-
13.1.1 集合的同构与异构:
同构: 保存的对象类型相同
异构: 保存的对象类型不同 -
13.1.2 分离接口与实现:
集合可以用各种方法实现,(保存对象的基础数据结构可以以各种技术实现)
一个抽象数据类型(ADT)是由数据和在该数据上所实施的具体操作构成的集合。一个ADT有名称、值域和一组允许执行的操作。
“集合”和抽象数据类型”是可以互换的等同概念。
对象具有定义良好的接口,从而成为一种实现集合的完整机制。 -
13.2 数据结构的动态表示:
数据结构:
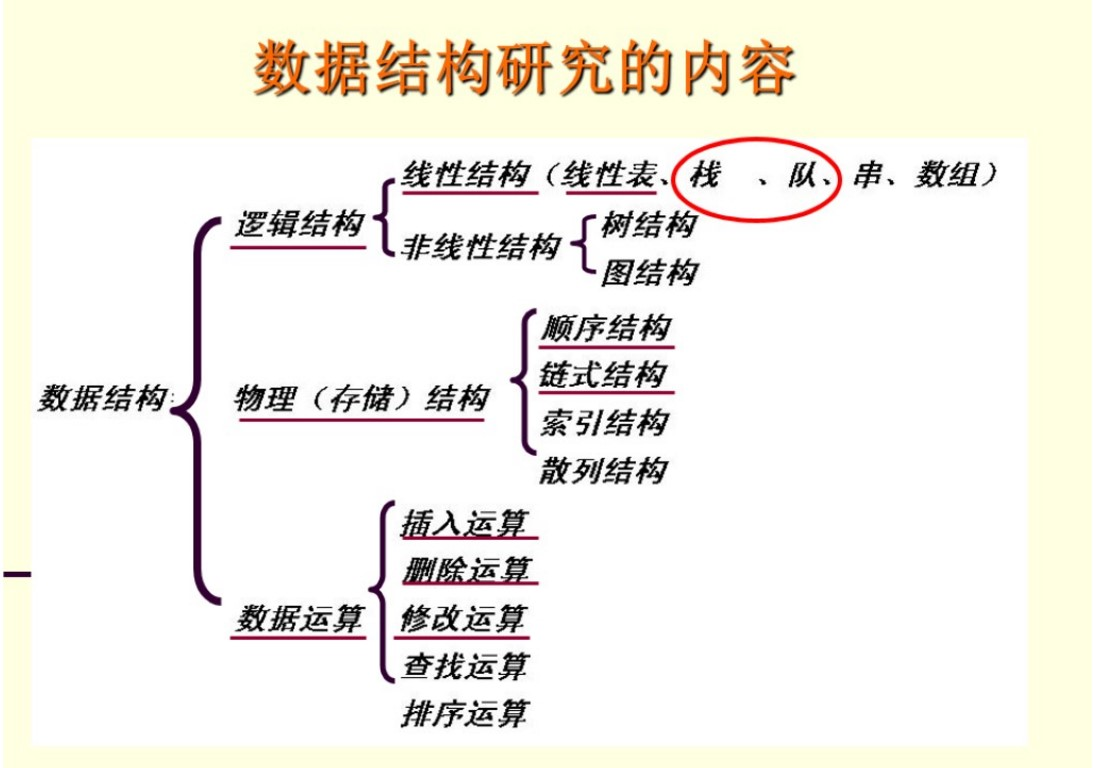
-
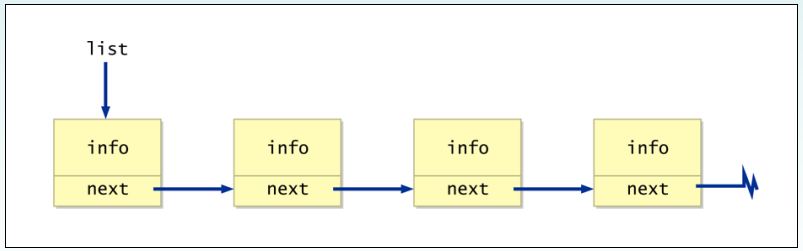
13.2.1 动态结构:
class Node
{
int info;
Node next;
}
-
13.2.2 动态链接的列表:
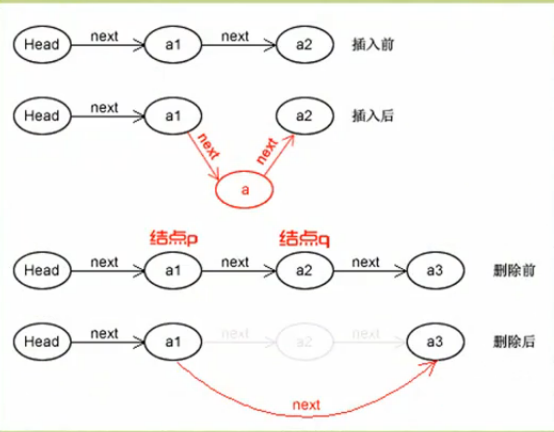
-
13.2.3 其他的动态列表:
class Node
{
int info;
Node next, prev;
}

class ListHeader
{
int count;
Node front,rear;
}
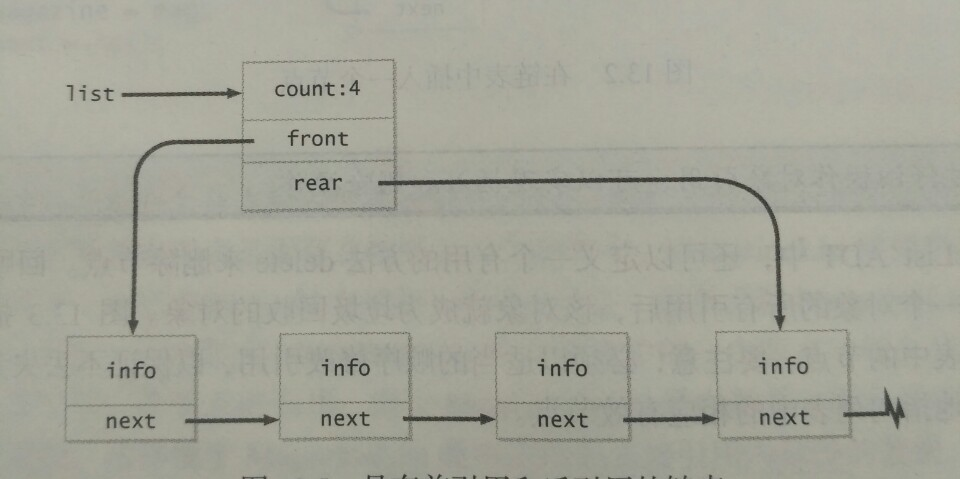
-
13.3 线性数据结构:
-
13.3.1 队列: 使用(FIFO)先进先出的存取方式;

典型的操作:
入队——在队尾添加一个元素;
出队——从队首移除一个元素;
检测空队列——若队列为空,返回true。 -
13.3.2 堆栈: 以后进先出的方式(LIFO)存取元素
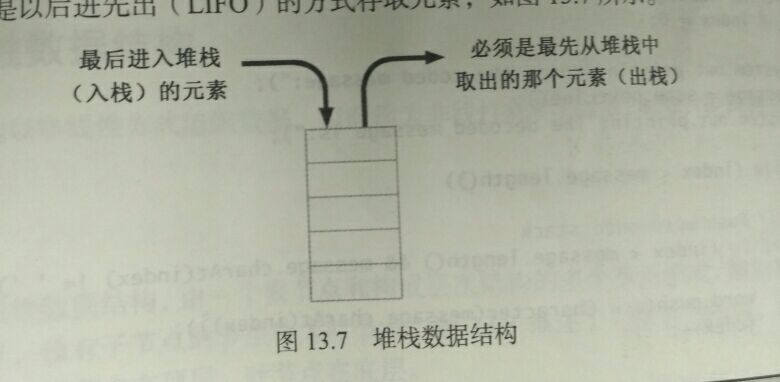
一个堆栈抽象数据类型(ADT)典型的操作:
入栈——将一个元素压入栈顶;
出栈——从栈顶移除一个元素;
读栈顶——从栈顶获取元素,但不将该元素移出栈顶;
检测空堆栈——若堆栈为空,返回true。 -
13.4 非线性数据结构:
-
13.4.1 树: 由一个根节点和构成层次结构的多个节点组成。
内部节点: 除根节点外的所有节点;
叶节点: 无子节点的节点;
注: 二叉树上的每个节点不能有超过两个的子节点;
除动态链外,亦可用静态表示方式(eg:数组)实现树数据结构。
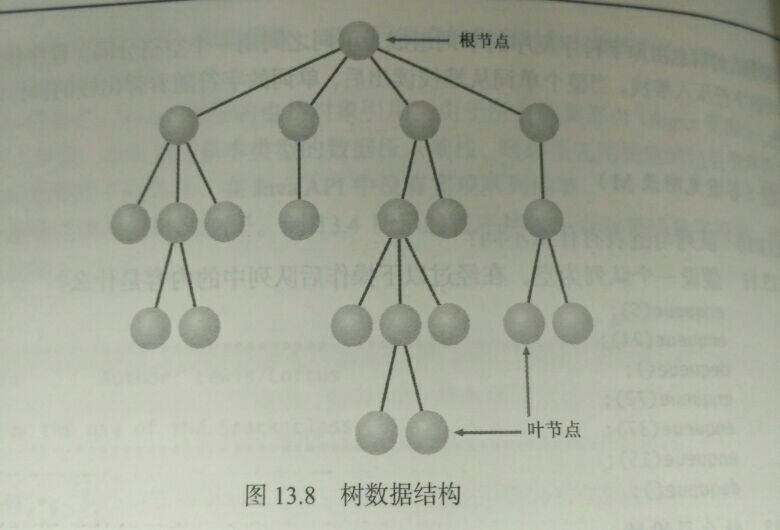
-
13.4.2 图:
边: 一个节点到令一个节点的连接,一般无限制;
可以用数组实现图,但更常用动态链。
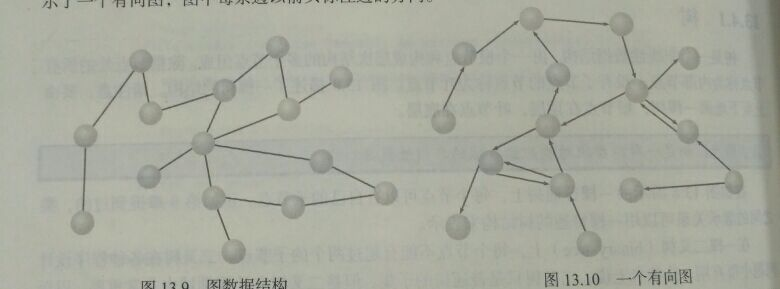
-
13.5 java集合类API: java标准类库中定义的几种表示不同类型集合的类。
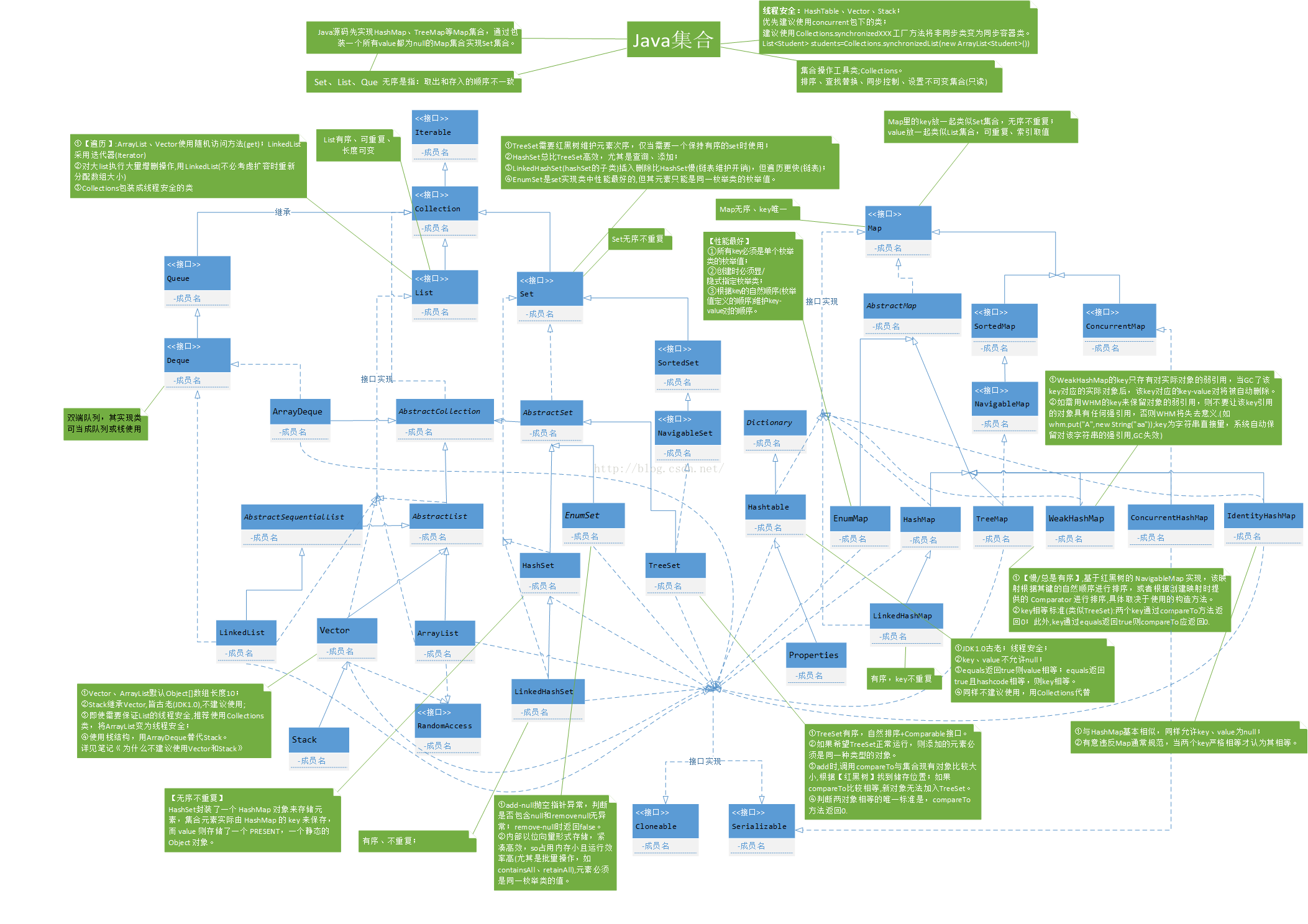
-
13.5.1 泛型: 指一个集合所管理的对象的类型要在实例化该集合对象时才确定;
好处:
只有适当类型的对象可以添加到集合中;
将对象移出集合时无需进行类型转换。
教材学习中的问题和解决过程
- 问题1: ArrayList 与LinkedList,哪个更好?
- 解决:让我们先看一段代码:
List<String> a1 = new ArrayList<String>();
a1.add("Program");
a1.add("Creek");
a1.add("Java");
a1.add("Java");
System.out.println("ArrayList Elements");
System.out.print(" " + a1 + "
");
List<String> l1 = new LinkedList<String>();
l1.add("Program");
l1.add("Creek");
l1.add("Java");
l1.add("Java");
System.out.println("LinkedList Elements");
System.out.print(" " + l1 + "
");
其输出结果为:
ArrayList Elements
[Program, Creek, Java, Java]
LinkedList Elements
[Program, Creek, Java, Java]
可见它们的运行结果是一样的,一样的东西为什么非要用不同的名词来表示?既然能整出这么个奇怪的语言,想必也不傻,怎么会多此一举......
查阅了相关资料:
** ArrayList:** 本质上是一个数组,可以直接通过索引(index)访问其中的元素;
LinkedList: 一个双向链表;
嗯!还是有所区别的,可仅仅只是这点区别貌似还是不能很好地说明名字不同的意义何在,而且,到底使用哪个更好?
有人用下面的代码做了个测试
ArrayList<Integer> arrayList = new ArrayList<Integer>();
LinkedList<Integer> linkedList = new LinkedList<Integer>();
// ArrayList add
long startTime = System.nanoTime();
for (int i = 0; i < 100000; i++) {
arrayList.add(i);
}
long endTime = System.nanoTime();
long duration = endTime - startTime;
System.out.println("ArrayList add: " + duration);
// LinkedList add
startTime = System.nanoTime();
for (int i = 0; i < 100000; i++) {
linkedList.add(i);
}
endTime = System.nanoTime();
duration = endTime - startTime;
System.out.println("LinkedList add: " + duration);
// ArrayList get
startTime = System.nanoTime();
for (int i = 0; i < 10000; i++) {
arrayList.get(i);
}
endTime = System.nanoTime();
duration = endTime - startTime;
System.out.println("ArrayList get: " + duration);
// LinkedList get
startTime = System.nanoTime();
for (int i = 0; i < 10000; i++) {
linkedList.get(i);
}
endTime = System.nanoTime();
duration = endTime - startTime;
System.out.println("LinkedList get: " + duration);
// ArrayList remove
startTime = System.nanoTime();
for (int i = 9999; i >=0; i--) {
arrayList.remove(i);
}
endTime = System.nanoTime();
duration = endTime - startTime;
System.out.println("ArrayList remove: " + duration);
// LinkedList remove
startTime = System.nanoTime();
for (int i = 9999; i >=0; i--) {
linkedList.remove(i);
}
endTime = System.nanoTime();
duration = endTime - startTime;
System.out.println("LinkedList remove: " + duration);
输出结果为:
ArrayList add: 13265642
LinkedList add: 9550057
ArrayList get: 1543352
LinkedList get: 85085551
ArrayList remove: 199961301
LinkedList remove: 85768810
并对其操作所需时间进行了统计:
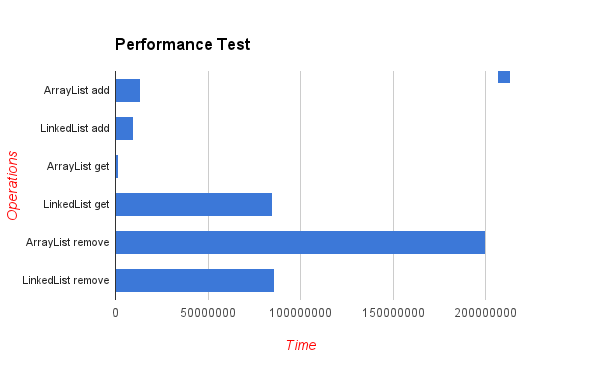
显而易见: LinkedList在添加和删除时速度更快,但获取速度更慢;
有人对二者的不同做了进一步解释:
ArrayList: 一旦数组被填满,就需要重新分配一个更大的数组,并将原数组的中的所有元素按顺序复制到新数组中,这需要耗费O(n)的时间。而且,在ArrayList中添加或移除一个元素都需要移动数组现有的元素。这可能是使用ArrayList的最大劣势。
LinkedList: 如果需要访问链表中间的元素,需要从链表的头部开始查找。但是,在LinkedList添加和移除元素的速度比较快,因为者只需要对链表进行局部修改。
二者某些方法的时间复杂度如下:

除了运行时间,对于大的list,还需要考虑内存的使用。在LinkedList中,每个指点中至少需要两个额外的指针分别指向前一个节点和下一个节点;而在ArrayList中,只需要一个包含元素的数组。
综上考虑: 在 :1.没有大量的随机访问元素;
2.有大量的添加/删除操作下
LinkedList要优于ArrayList。
代码调试中的问题和解决过程
- 问题1:编程项目13.3排序时第一个位置并不参与
- 解决:
关键代码:
public void SelectionSortList(){
int min;
SelectionSortNode a = null;
SelectionSortNode b = null;
for (a=list.next;a!=null;a=a.next){
for (b=a.next;b!=null;b=b.next){
if (a.num>b.num){
min = b.num;
b.num = a.num;
a.num = min;
}
}
}
}
仔细检查后发现,a=list.next 导致直接跳过节点的头,所以第一个节点被略过,无法参与排序;
修改后的代码:
public void SelectionSortList(){
int min;
SelectionSortNode a = null;
SelectionSortNode b = null;
for (a=list;a!=null;a=a.next){
for (b=a.next;b!=null;b=b.next){
if (a.num>b.num){
min = b.num;
b.num = a.num;
a.num = min;
}
}
}
}
a=list保证了从首位开始遍历链表,然后再一一比较。

代码托管

上周考试错题总结
- 错题1:

- 理解:检查的异常必须被捕获,否则必须在抛出子句中列出。未经检查的异常不需要抛出子句。这两种异常都遵循异常传递的规则。
- 错题2:

- 理解:catch不会捕获从其内部抛出的异常。
返回目录
结对及互评
点评过的同学博客和代码
- 本周结对学习情况:
- 20172316赵乾宸
- 博客中值得学习的或存在问题:
1.教材总结较以前更为完整
2.问题的解决较以前更为详细
3.关键部分给出了代码,很好。 - 20172329王文彬
- **博客中值得学习的或存在问题: **
1.问题解决详细
2.冒泡只是同学不经意间提到,自己去主动学习,很好
3.部分地方缩进有误
其他(感悟、思考等,可选)
- 本周其他事情不多,有更多的时间去实践、查阅,虽说关于集合这一章还有些不明白之处
但又说不上来,像是线程安全之类的,然而并没有去深究,或许是接触的东西还是太少了,
期望在以后的学习中逐步解惑。
学习进度条
| 代码行数(新增/累积) | 博客量(新增/累积) | 学习时间(新增/累积) | 重要成长 | |
|---|---|---|---|---|
| 目标 | 5000行 | 30篇 | 400小时 | |
| 第一周 | 202/202 | 1/2 | 15/15 | 积极主动敲代码 |
| 第二周 | 490/692 | 1/3 | 18/33 | 善于思考 |
| 第三周 | 581/1273 | 1/4 | 15/48 | 善于完善 |
| 第四周 | 1857/3130 | 1/6 | 33/81 | 累 |
| 第五周 | 655/3787 | 1/7 | 22/103 | |
| 第六周 | 531/4318 | 1/8 | 18/121 | |
| 第七周 | 810/5128 | 1/9 | 23/ 144 | |
| 第八周 | 698/5826 | 1/13 | 21/ 165 | |
| 第九周 | 756/6582 | 1/15 | 54/ 219 | |
| 第十周 | 1289/7871 | 1/16 | 56/ 275 |