当前为Windows环境
1.首先安装Tesseract-OCR,链接:https://pan.baidu.com/s/12zazgAYWsNnxn8AxPjGfaw 提取码: esif
下载后默认安装就好,在安装过程中存在选项安装的情况,此时为选择语言,可略过
2.Tesseract-OCR安装完毕后,设置环境变量
设置tesseract.exe的环境变量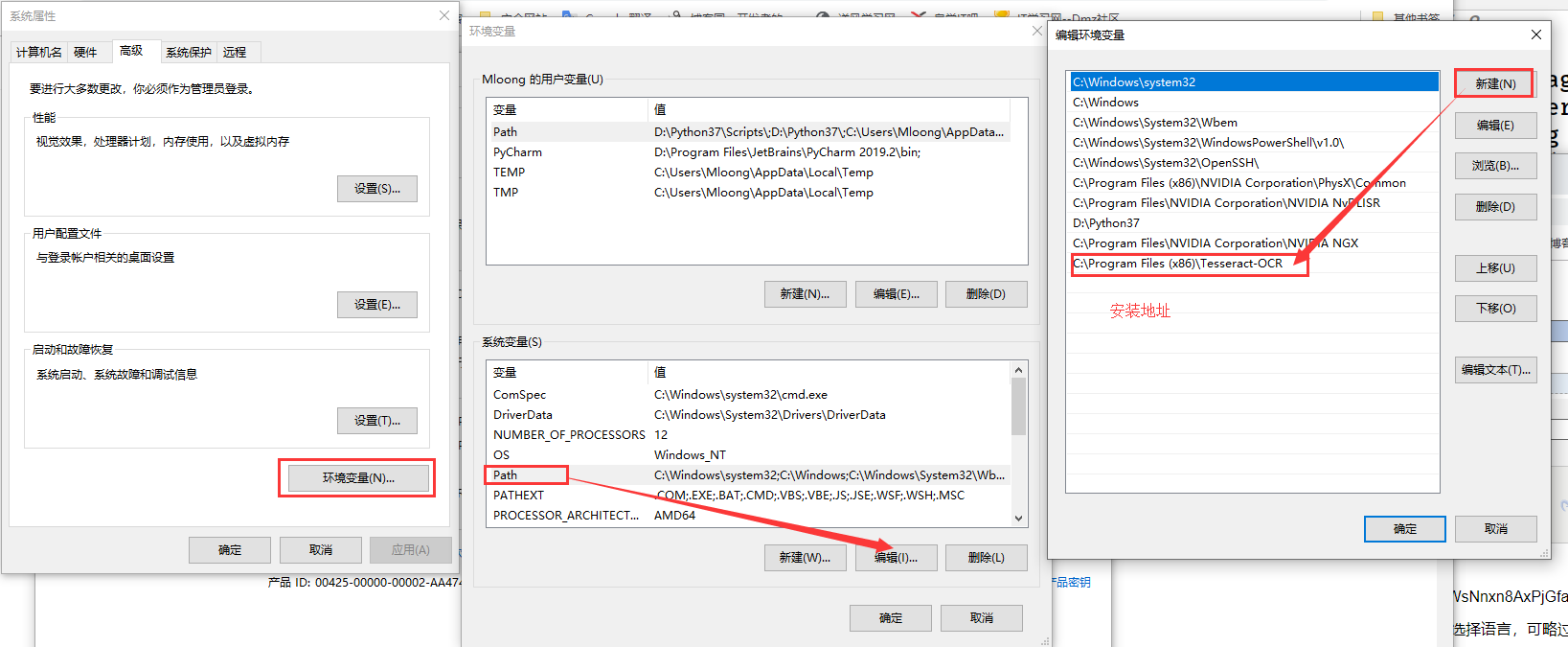
新建TESSDATA_PREFIX环境变量,值为C:Program Files (x86)Tesseract-OCR essdata,如图
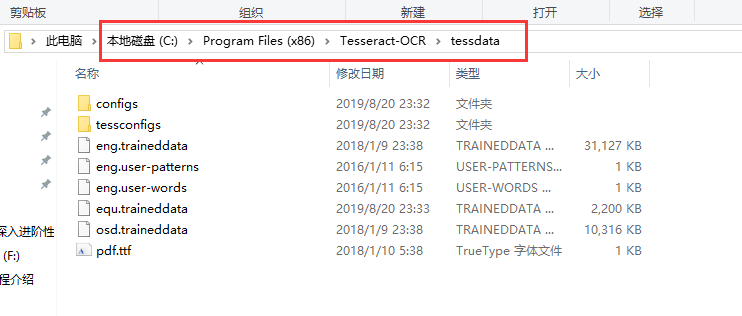
3.验证Tesseract-OCR
3.1 进入cmd 输入下面的命令查看版本,正常运行则安装成功:
tesseract --version

3.2 识别图片
tesseract 图片路径 输出文件


 识别成功!!
识别成功!!
4.进入cmd安装python依赖
4.1 安装依赖
pip install pytesseract
pip install pillow
4.2 编写代码
识别下面的验证码
代码如下:
import pytesseract from PIL import Image image = Image.open("F:/imooc2.png") text = pytesseract.image_to_string(image) print(text)
结果为6067,识别成功
5.此时特别容易出现错误
解决方案1:仔细查看环境变量是否正确
解决方案2:在代码中添加相关变量参数
#coding=utf-8 import pytesseract from PIL import Image pytesseract.pytesseract.tesseract_cmd = 'C://Program Files (x86)//Tesseract-OCR//tesseract.exe' tessdata_dir_config = '--tessdata-dir "C://Program Files (x86)//Tesseract-OCR//tessdata"' image = Image.open("F:/imooc2.png") text = pytesseract.image_to_string(image, lang ='eng', config=tessdata_dir_config) print(text)
