一、传统数据库回顾
1.以学生成绩管理系统为例,对环境进行假设
1)老师和学生的要求
-
-
- 正确的查询结果
- 最快查询速度
-
2)录入员的要求
-
-
-
正确记录分数
-
多人同时记录
-
录入数据不能丢失
-
-
3)输入和输出的协调
-
-
- 查询分数时不能查询一半
-
2.如何满足上述特性(ACID)
1)原子性
-
-
- 当一个学生成绩被录入的时候,要么是完全的被录入,要不然就是完全不被录入
-
2)一致性
-
-
- 指事物的一致性,比如学生交学费,从学生账户有扣款,学校账户就必须有进账,并且两者数量一致,避免出现因异常导致扣款逻辑完成,但是到账逻辑没有完成的情况,要么全部成功,要么全部失败。
-
3)隔离性
-
-
- 多个录入员可以同时录入多个不同学生的成绩,而互相之间不冲突
-
4)持久性
-
-
- 当成绩被正确录入到系统之后,发生系统崩溃,吊链之类的问题,数据库仍然可以在恢复后正常运作。
-
3.数据量变大后的新问题(以全国统考为例)
1)因为数据量较大,所以没有办法存放在同一台机器上面。
2)当数据量变大,并发量也会增大,单库不支持大量并发,所以差不了。
3)如果数据很重要,集中的数据库出现中间数据丢失,整个系统会陷入不可用的情况,会出现较大的风险。
二、分布式数据库概述
1)集中式数据库缺点
-
-
-
通信开销大:
- 录入的客户端存在于全国各地,而集中式数据库只能存在于一个地方
-
系统可靠性:
- 集中式数据库所有数据都存在于一个点上,记录点的故障就会导致整个系统停止运作。
-
性能差:
- 随着数据量变大,录入的客户端变多,存储系统本身的性能就会成为瓶颈。
-
可扩展性:
- 随着录入客户端的变多,集中式数据库的数据节点会发生严重的新能问题,而 有单机系统的磁盘,CPU,内存没办法无限制的扩展,所以集中式数据库的扩展就是一个严重问题。
-
设计管理困难:
- 当出现新的业务时,对数据库的逻辑会变得越来越复杂。
-
-
2)分布式和分散式数据库的区别
-
-
-
相同点
- 数据都分散在不同的存储位置,可解决集中式数据库遇到的可扩展性问题。
-
不同点
- 逻辑的整体性
-
分布式数据库基本要求
-
数据分布性
-
数据统一性
-
数据透明性
-
数据安全性
-
可扩展性
-
数据自治性
-
-
-
3)分布式数据库系统的定义
-
-
-
两个重点
- 保证逻辑一致性
- 保证数据分不到不同区域
-
两个要点
-
每个地域节点是拥有集中式数据库的计算机系统
-
每个节点都是由通信网络连接起来的节点集合
-
-
两个特性
-
透明性
-
逻辑统一
-
-
-
4)分布式系统的优点
-
-
-
灵活性更高
-
成本优势
-
可靠性和可用性更高
-
局部响应速度快
-
-
5)分布式系统的缺点
-
-
- 通信开销大
- 跨节点逻辑实现复杂
- 数据保密性相对较弱
-
三、分布式数据库系统的分类以及体系架构
1.数据库系统的分类
1)同质同构数据库

2)同质异构数据库

3)异构数据库(关系数据库+文档数据库+搜索引擎)

2.体系架构
1)数据分片
-
-
-
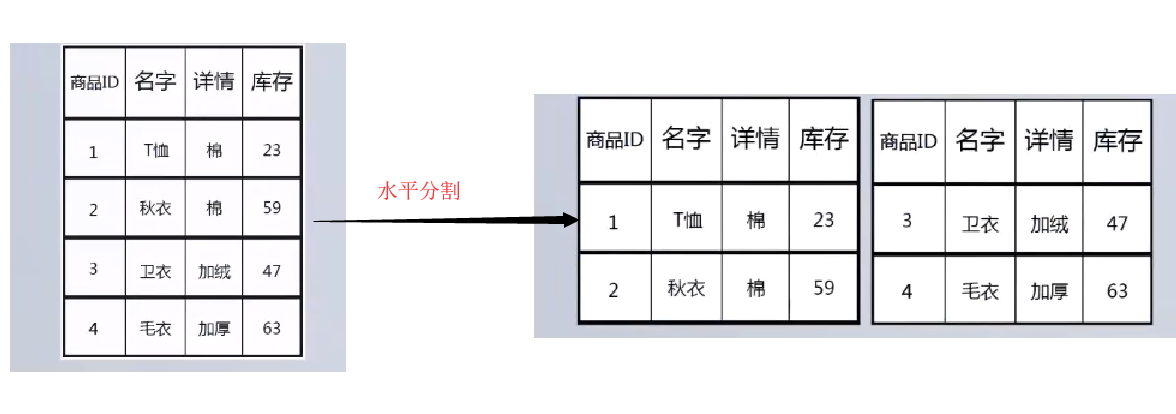
水平分片
- 实现方式:按行拆分
- 特点:数据结构一致,字段类型和字段类型是一样的。
- 图示
-
-
-
-
-
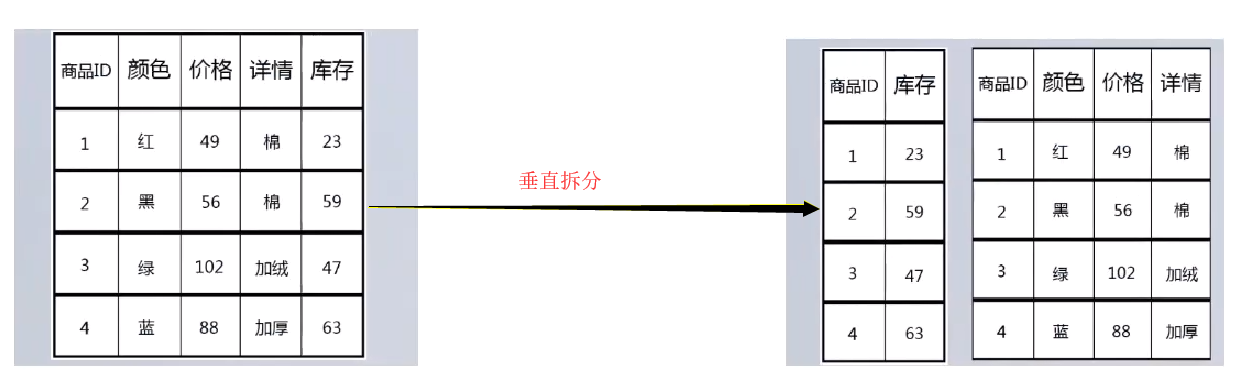
垂直分片
- 实现方式:一张表的数据按字段拆分成多个表,比如将频繁更新的字段和不频繁更新的字段分开,大的字段和小的字段进行分开。
- 特点:需要一个冗余主键来维持数据一致性。
- 主要目的:减少更新对磁盘造成的影响
- 图示:
-
-
-
-
-
混合分片
-
-
2)体系架构
-
-
-
数据分片
- 完备性:所有的数据被分配到不同的节点,所有节点的总和必须包含完整信息。
- 重构条件:把数据分配到不同的节点后,一定要有线索将数据通过固定的方法,合并成完整的数据。
- 不相交条件:一个商品不会同时出现在两个不同的地区
-
-
3)数据分配
-
-
-
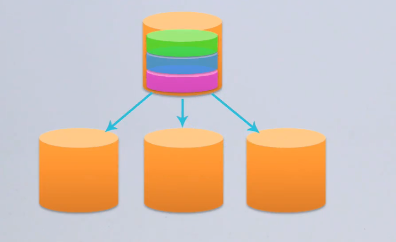
分割分配
- 定义:将数据都分散到不同的节点,并且每一个节点之间的数据都是不互相重复的。所有数据的综合是数据的全集。
- 图示
-
-
-
-
-
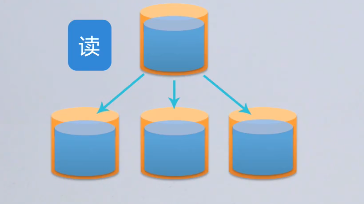
全复制分配
- 定义:每个节点都拥有全量的数据,不同节点的数据都是完全相同的。为了平衡读的压力,而写并没有出现压力的情况下所采取的措施。
- 图示
-
-
-
-
-
混合结构
- 定义:对于分散在全国各地的各个省而言,使用分割分配,而在每一个省内,为了保证数据的安全性和高可靠性,采用全复制分配。
- 图示
-
-
四、分布式数据库组件
1.分布式数据库系统基本要求
1)逻辑统一性
2)入口统一性
3)全局数据字典
-
-
- 维护数据分片规则
- 网络状态
- 完整性约束
- 存储路径
- 存储权限
- 数据的全局一致性
- 当执行死锁检测时存储锁信息
- 实时事物状态
- 事物统计信息
- 数据变更状态
- 事物运行状态
-
4)全局数据管理系统
-
-
- 协调全局事务执行
- 并发控制
- 防死锁
- 全局提交/恢复
-
5)局部数据管理系统
-
-
- 接受全局管理系统的命令
- 做本地的数据处理
- 查询
- 更新
- 存储
- 返回结果
- 分布式事物的启动,提交,回滚接口
- 崩溃恢复的全局协调
-
6)局部数据管理系统
-
-
- 管理全局与局部管理系统之间的通信协议
- 每个分片之间的通信
-
2.数据库组件的基本功能
1)分布式事务处理
五、分布式数据库查询
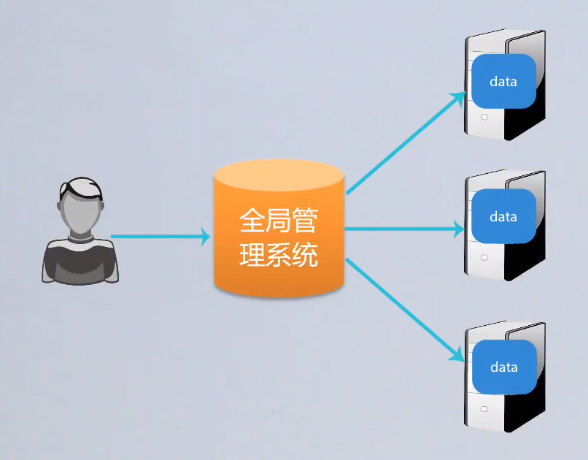
1.单节点查询
1)过程
-
-
- 全局管理系统将请求分配到单一的节点,在单一节点上执行查询,直接返回结果。
-
2)图示

2.多节点查询
1)业务需求
-
-
- 大量的查询需要通过从不同的节点取得数据,需要依赖多个节点的数据,对于这类查询,为了保证最快的速度和对系统最小的消耗,工程上会做不同的处理。
-
2)图示
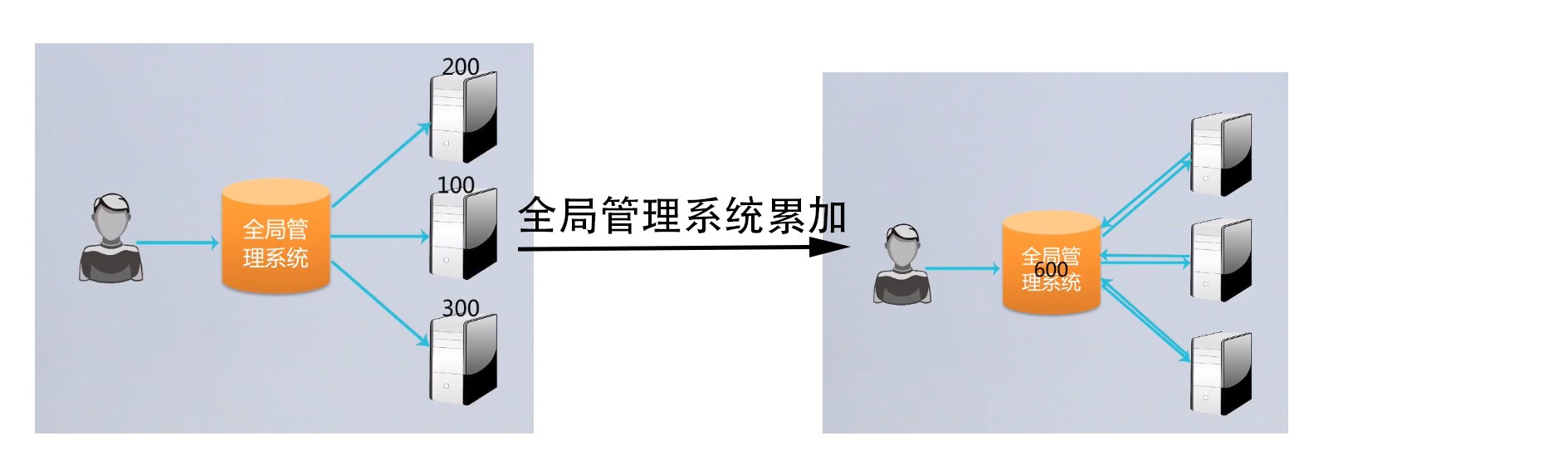
3)处理方式
-
-
-
查询下发
- 条件:每个数据节点可以单独计算出一部分结果
- 以计算商品总数为例,这种 请求被下发到每一个节点,而每一个节点只需要返回一个数字,而集中管理系统只需要做一个总和就可以完成。
-
-
-
-
-
结合不同节点间的数据
- 要求:将数据从各个分界点先汇总到一起,然后再进行计算。
- 技术难点:由于分布式数据库系统的数据往往比较大,汇总到一起回造成性能上的瓶颈。
- 解决方案:全局管理系统对查询做改写,获取最小的数据分片,不同节点拿到符合条件的数据后进行汇总
- 汇总方案:
- 汇总到统一的节点:
- 比如说取销售了排名前10 的商品,就可以让每个独立的节点取自己的部分数据,然后合并到全局管理系统的中心节点,做统一的逻辑处理,对于数据量较大是不可行的,因为需要占用大量的带宽,也会占据全局管理系统大量的CPU。
- 把数据做横向广播:
- 汇总到统一的节点:
-
-